

Wokół Arduino. Napisy i inne zakrętasy, część 3
Podane dalej informacje o unikodzie i UTF-8 nie są zwykłą ciekawostką rozszerzającą horyzonty. W cyklu Wokół Arduino, interesujemy się małymi mikroprocesorami i tym, jak one sobie radzą z tekstami. Radzą sobie dość dobrze, ale zapewne już na początku zauważyłeś, że występują pewne kłopoty i pułapki.
Otóż pakiet Arduino IDE wykorzystuje kodowanie zwane UTF-8. Jeśli chcemy wyświetlić na konsoli ekranu znaki spoza zestawu ASCII, to musimy wykorzystać kod UTF-8. Gorzej jest w drugą stronę, a także przy wykorzystaniu znakowego wyświetlacza LCD, gdzie mamy kod ASCII i określone dodatkowe znaki. Mamy do czynienia z różnymi sposobami kodowania napisów, a dla początkujących jest to czarna magia.
W poprzednich artykułach „Wokół Arduino” omówiliśmy siedmiobitowy kod ASCII. Wiemy, że do zakodowania podstawowych znaków języka angielskiego wystarczy siedem bitów, co daje 128 kombinacji zer i jedynek. Podstawową jednostką w informatyce jest bajt, czyli osiem bitów i wiemy już, jak dodatkowe 128 kombinacji może kodować różne znaki narodowe (litery) i inne znaki graficzne. Dowiedzieliśmy się też o poważnych problemach z tak zwanymi stronami kodowymi. Potrzebne okazało się jeszcze inne rozwiązanie, pozwalające kodować jeszcze więcej znaków. Tym rozwiązaniem jest…
Unikod (Unicode)
Już dawno powstała instytucja (konsorcjum), która od lat 80. próbowała stworzyć jeden zunifikowany zestaw znaków dla wszystkich języków i opracować standard ich kodowania (czyli sposób reprezentacji liter i innych znaków w systemach cyfrowych). Najpierw przewidywano, że będzie to kod co najwyżej 16-bitowy, co daje maksymalnie 65536 znaków-symboli. Jednak już w roku 1996 zniesiono to ograniczenie i do unikodu zaczęto włączać nie tylko znaki z języków używanych współcześnie, ale też najróżniejsze symbole, ikony oraz znaki z języków martwych, między innymi… egipskie hieroglify i znaki mezopotamskiego pisma klinowego (rysunek 1). Dziś w unikodzie przewidziane jest miejsce na ponad milion znaków, ale jak na razie, w najnowszej wersji Unikodu z roku 2017, jest ich mniej niż 140 tysięcy, co i tak jest zaskakująco dużą liczbą.
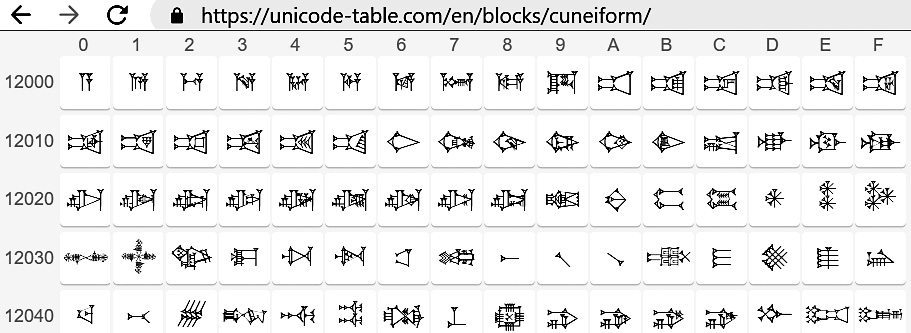
Rysunek 1
Najogólniej biorąc, unikod to zunifikowany zestaw znaków graficznych, występujących we wszystkich językach świata. Żeby się nie pogubić w temacie, podkreślmy, że przede wszystkim unikod to uporządkowane zestawienie „wszystkich znaków”, gdzie każdemu znakowi przydzielono numer porządkowy. Mamy więc pary: znak i jego numer. Znaki i ich numery można odnaleźć na przykład na stronie: https://unicode-table.com/pl/, gdzie jak pokazuje rysunek 2, można sprawdzić oficjalną nazwę znaku i jego numer w unikodzie.
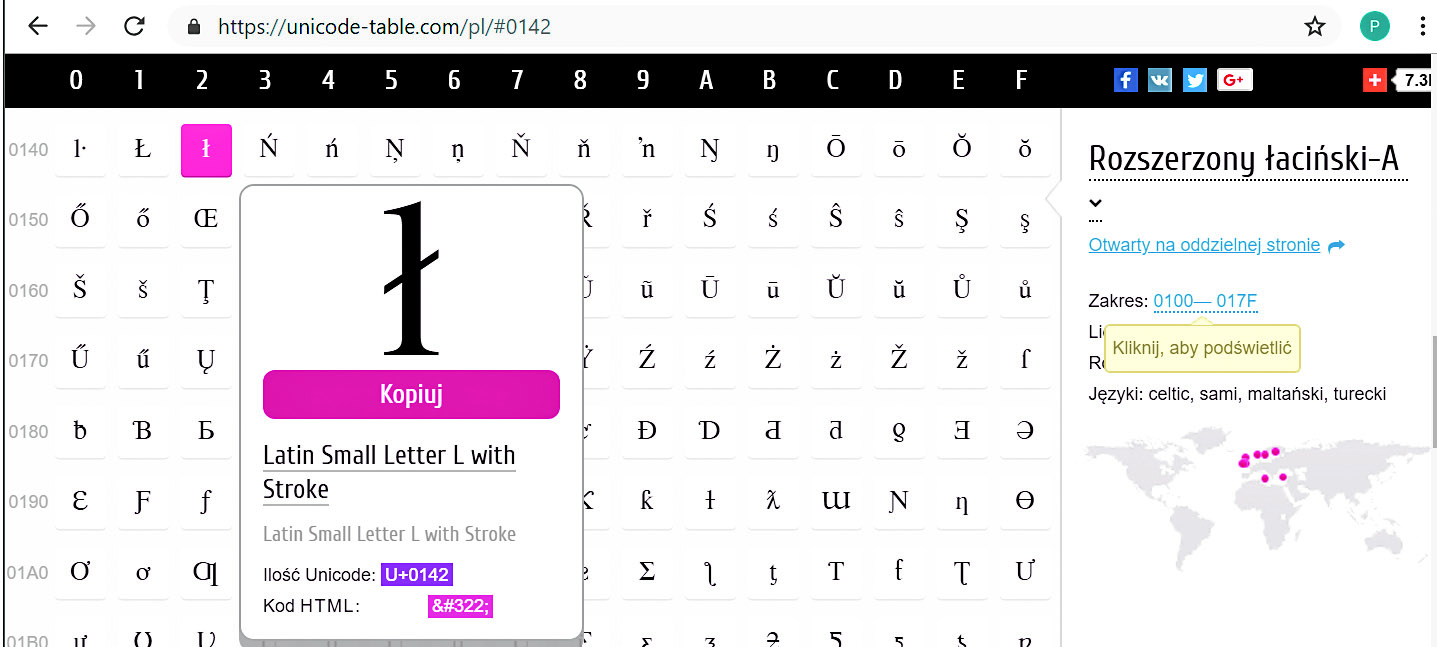
Rysunek 2
Dla uniknięcia wątpliwości, numer unikodu przyjęto oznaczać dużą literą U, znakiem plus (+) i numerem kolejnym znaku, ale przedstawionym nie dziesiętnie, tylko szesnastkowo (heksadecymalnie). W sumie w unikodzie przewidziano miejsce na ponad milion, a konkretnie na 1 112 064 znaków. Cała ta pula numerów znaków podzielona jest na 17 tak zwanych płaszczyzn (ang. plane) o numerach 0…16, co szesnastkowo daje liczby w zakresie 0…10. Każda płaszczyzna teoretycznie zawiera 65 536 znaków, a liczby 0…65535 można przedstawić jako 4-cyfrowe liczby szesnastkowe 0000…FFFF. W unikodzie przewidziano więc numery znaków w zakresie U+0…U+10FFFF, co daje ponad milion numerów, z czego przydzielonych jest już około 140 tysięcy.
Co istotne, najbardziej popularne znaki prawie wszystkich współczesnych języków zawarte są na pierwszej z 17 płaszczyzn, zwanej BMP (Basic Multilingual Plane). Ta pierwsza płaszczyzna ma numer zero, więc zawarte tam znaki mają numery składające się z co najwyżej czterech cyfr szesnastkowych U+0000…U+FFFF, czyli dziesiętnie 0…65535. A więc numery najpopularniejszych znaków z płaszczyzny BMP można zapisać jako liczby dwójkowe szesnastobitowe – dwubajtowe.
I tu może nasuwać się niesłuszny wniosek, że w unikodzie znaki są jednoznacznie kodowane przez podanie ich numerów.
NIEKONIECZNIE!
Trzeba tu rozróżnić dwie sprawy: jedna to numer znaku/symbolu w unikodzie, a druga, odrębna, to sposób zakodowania tego znaku/symbolu.
Kodowanie
Unikod (Unicode) to jedynie przyjęty powszechnie uznany zbiór, zestawienie, przyporządkowanie znaków i odpowiadających im numerów. Oddzielną sprawą jest sposób kodowania znaków Unicode w praktyce. Można to zrobić na różne sposoby. Oto trzy z nich:
UTF-32. Najprostsze i niejako naturalne wydaje się kodowanie przez podawanie numeru znaku, jaki ma on w unikodzie. Przewidziano ponad milion znaków o szesnastkowych numerach 0…10FFFF, więc na numer-kod na pewno nie wystarczy jeden bajt ani nawet dwa bajty. Zasadniczo wystarczyłyby trzy bajty (24 bity), co obejmuje liczby 0…FFFFFF, ale w informatyce następną „komputerową wielkością” po dwóch bajtach są cztery bajty, czyli 32 bity. W informatyce wykorzystujemy liczby 8-, 16- i 32-bitowe, więc dla znaków unikodu trzeba wykorzystać liczby 32-bitowe.
I oto mamy oczywisty, niejako naturalny sposób kodowania, zwany UTF-32 (UTF – Unicode Transformation Format), gdzie kod każdego znaku ma 32 bity. Wadą jest po pierwsze brak kompatybilności z kodem ASCII, a po drugie duża objętość tak zakodowanych tekstów – czterokrotnie większa niż tekstów ASCII. Niemniej UTF-32 bywa wykorzystywany.
UTF-16. Innym sposobem kodowania jest UTF-16, gdzie, biorąc rzecz w największym uproszczeniu, popularne znaki z bazowej warstwy (BMP) są kodowane liczbami 16-bitowymi, a pozostałe, „wyższe” znaki unikodu za pomocą 32-bitów. UTF-16 jest stosowany rzadko, m.in. przez brak kompatybilności z kodem ASCII.
UTF-8. Obecnie do kodowania znaków unikodu zdecydowanie najczęściej wykorzystuje się zaskakująco sprytny sposób, nazwany UTF-8. Najpopularniejsze, czyli najczęściej używane znaki koduje on za pomocą 8 bitów, czyli jednego bajtu. Mniej popularne za pomocą dwóch bajtów, a bardzo mało popularne – za pomocą trzech albo czterech bajtów. Ponieważ zdecydowana większość tekstów pisanych w alfabetach łacińskich zawiera głównie znaki ASCII, objętość pliku tekstowego „uniwersalnie” zakodowanego w UTF-8 nie wzrasta znacząco względem sprawiających kłopoty wcześniejszych sposobów kodowania z użyciem stron kodowych. Po konwersji na UTF-8 objętość tekstu wzrasta tylko w niewielkim stopniu, zależnie od zawartości mało popularnych znaków. Bardzo sprytne, a w sumie zaskakująco proste są zasady kodowania eliminujące wątpliwości i ryzyko błędnej interpretacji.
Zasady kodowania UTF-8
W informatyce podstawową jednostką jest bajt (osiem bitów) i także przy kodowaniu UTF-8 tekst składa się z bajtów, czyli liczb ośmiobitowych. Przy analizie należy zwrócić uwagę na wartość bajtu.
Podstawowa zasada jest taka: jeśli w kodzie UTF-8 najstarszy bit bajtu jest zerem, nie ma wątpliwości, że zawiera liczbę z zakresu 0…127, więc jest to jednocześnie kod znaku ASCII! W ten sposób UTF-8 jest w pełni kompatybilny z kodem ASCII! I co ważne, działa to w obie strony!
Tak: każdy tekst w ASCII jest jednocześnie tekstem w UTF-8, co jest ogromną zaletą z uwagi na miliony i miliardy istniejących plików ASCII!
Świetnie, a jak w UTF-8 kodowane są tysiące znaków unikodu spoza ASCII?
To też jest sprytne i zaskakująco proste: W kodzie UTF-8 mamy tylko „porcje” 8-bitowe (bajty) i gdy najstarszy bit bajtu jest jedynką, na pewno jest to część kodu kilkubajtowego.
Ilubajtowego? To też jest bardzo łatwe: wystarczy policzyć, ile jedynek jest na początku bajtu. Jeżeli są dwie jedynki (a potem zero), to jest to pierwszy bajt kodu dwubajtowego.
Jeżeli na początku bajtu mamy trzy jedynki, a potem zero, to jest to pierwszy bajt kodu trzybajtowego. Gdy bajt ma na początku cztery jedynki i zero, jest to pierwszy bajt kodu czterobajtowego.
Proste?
No tak, a jeśli bajt ma na początku tylko jedną jedynkę i po niej zero?
To też jest proste: wtedy oczywiście nie chodzi o kod jednobajtowy, tylko jest to kolejny (drugi, trzeci lub czwarty) bajt kodu kilkubajtowego.
Ten zaskakująco prosty sposób pozwala też zapisać w kodzie UTF-8 dłuższe sekwencje, do 6 bajtów, ale dla miliona numerów unikodu wystarczą cztery bajty i obecnie sekwencje 5- i 6-bajtowe są w UTF-8 zabronione. W kodzie UTF-8 nie mogą wystąpić bajty o wartości FE and FF, co pozwala odróżnić ten kod od UTF-16, gdzie one występują.
Omówiliśmy właśnie podejście „bitowe” do kodowania UTF-8. Ale można też podejść inaczej i po prostu sprawdzić, jaką liczbę z zakresu 0…255 (szesnastkowo 0…FF) zawiera dany bajt kodu UTF-8.
Ogólnie biorąc, jeśli bajt ma wartość z zakresu 00…7F (dziesiętnie 0…127), jest to kod jednobajtowy – znak z zestawu ASCII.
Jeżeli bajt ma wartość z zakresu 80, to BF (dziesiętnie 128…191), to na pewno jest to jeden z kolejnych bajtów kodu kilkubajtowego.
Jeżeli bajt ma wartość z zakresu C2…DF (dziesiętnie 194…223), to na pewno jest on pierwszym bajtem kodu dwubitowego. Wtedy drugi bajt na pewno będzie miał wartość 80 to BF (dziesiętnie 128…191).
Jeżeli bajt ma wartość z zakresu E0 to EF hex (224 do 239), na pewno jest to pierwszy bajt kodu trzybajtowego, a kolejne dwa bajty będą mieć wartości z zakresu 80 to BF (dziesiętnie 128…191).
Analogicznie jeżeli pierwszy bajt ma wartość F0 do FD (dziesiętnie 240…253), jest to pierwszy bajt kodu czterobajtowego, a kolejne trzy bajty będą z zakresu 80 to BF (dziesiętnie 128…191).
Ilustruje to w uproszczeniu rysunek 3.
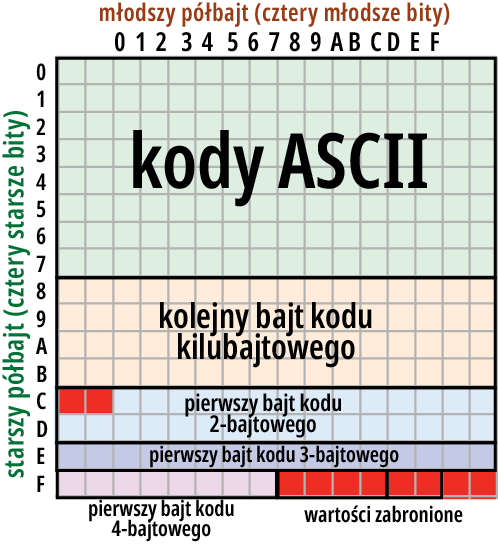
Rysunek 3
Dokładniej pokazuje to rysunek 4 pochodzący z angielskiej wikipedii (https://en.wikipedia.org/wiki/UTF-8), gdzie można też szukać bliższych wyjaśnień. Różowymi podkładkami zaznaczone są wartości zabronione, jakie nie mogą pojawić się w kodzie UTF-8. Przeanalizuj ten rysunek, by utrwalić podane informacje. A potem zrobimy następny krok…
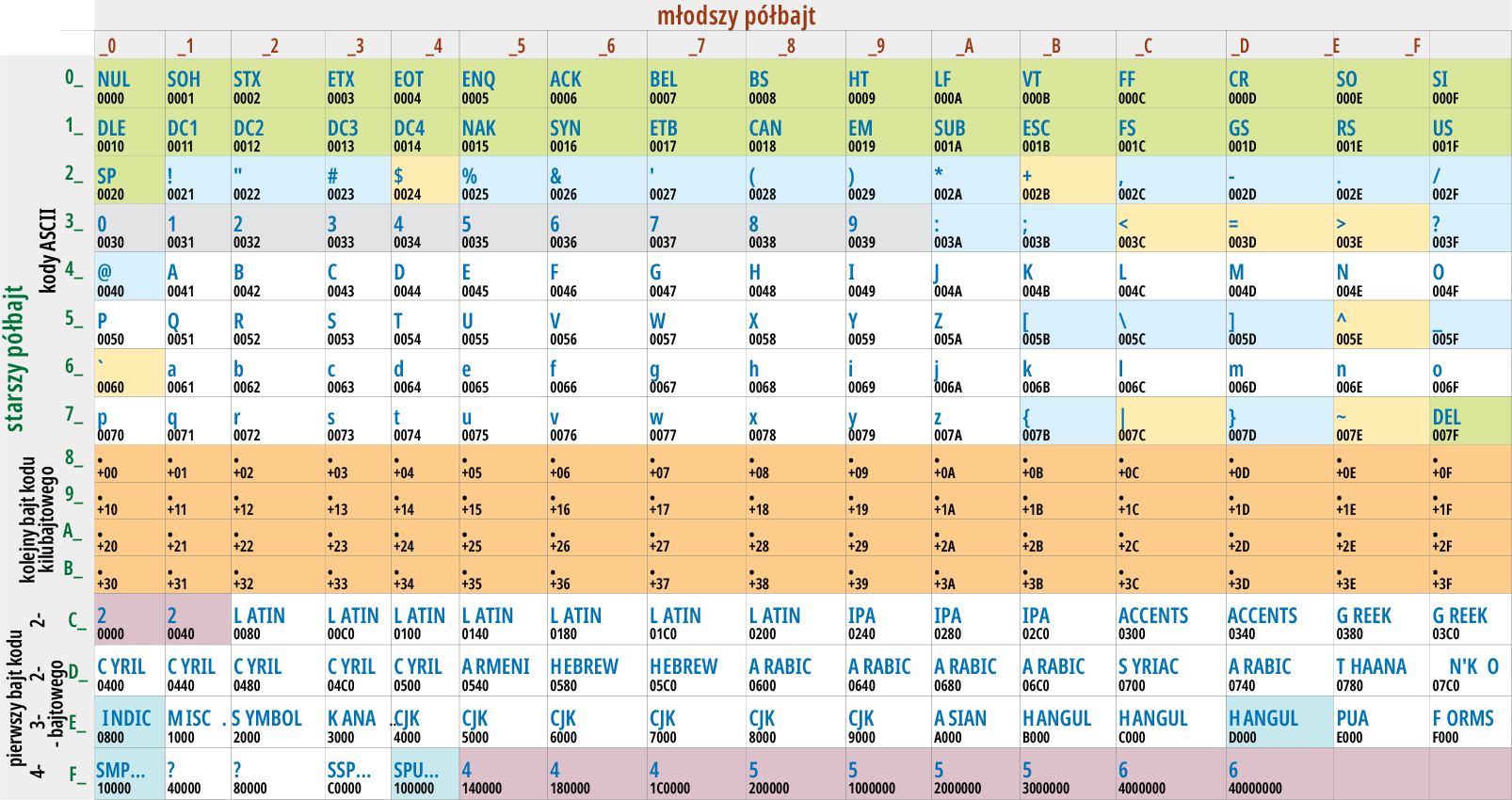
Rysunek 4
Wcześniej jednak krótko wspomnijmy o kodowaniu „polskich liter”. Otóż w UTF-8 polskie znaki kodowane są w dwóch bajtach, a więc według podanych reguł pierwszy bajt na początku musi mieć dwie jedynki i zero: 110xxxxx
Zapisując ośmiobitową liczbę dwójkową w postaci szesnastkowej, potrzebujemy dwóch cyfr (0…F), bo jedna cyfra szesnastkowa odpowiada czterem bitom liczby dwójkowej:
110xxxxx
więc pierwszą z tych dwóch cyfr pierwszego bajtu albo będzie 1100, czyli szesnastkowo C, albo 1101, czyli szesnastkowo D. Tak, i to nie tylko w przypadku polskich liter, zawsze pierwszy bajt zapisany w postaci szesnastkowej to albo cyfra C (cyfra dwanaście), albo cyfra D (trzynaście).
A drugi bajt?
Jak już wiemy, musi się on zaczynać od jednej jedynki i zera:
10xxxxxx
A więc przy zapisie szesnastkowym mamy cztery możliwości: 1000, 1001, 1010, 1011, co odpowiada cyfrom szesnastkowym: 8 (osiem), 9 (dziewięć), A (dziesięć), B (jedenaście). A więc drugi bajt znaku zapisany w postaci szesnastkowej zaczyna się od jednej z cyfr: 8, 9, A, B. Druga cyfra może być dowolna 0…F.
Wiemy już, jak należy traktować poszczególne bajty kodu UTF-8. Wypadałoby jeszcze wyjaśnić, jak dokładnie kodowany jest dany znak. O tym w następnej części.
Piotr Górecki


