


Kurs Arduino – Polskie litery w glcdfont.c
W poprzednich dwóch odcinkach (UR025 i UR026) zdobyliśmy komplet informacji, potrzebnych do wyświetlenia wszystkich liter polskiego alfabetu. Najpierw zajmiemy się podstawowym fontem o rozmiarach znaku 5×7 pikseli.
Polskie ogonki w glcdfont.c
W pliku glcdfont.c mamy definicje wszystkich znaków ASCII oraz innych symboli zgodnie ze stroną kodową CP437. Przypomnijmy, że jest to bardzo stara, wręcz „przedpotopowa“ strona kodowa, wykorzystywana w systemie MS-DOS od roku 1981.
W związku z problemem wyświetlania liter alfabetów wielu języków, już w systemie DOS wprowadzono szereg stron kodowych. Ponieważ w bibliotece Adafruit GFX mamy starą stronę CP437, na pewno powinniśmy zainteresować się też starą stroną systemu DOS, zawierającą polskie znaki. To strona DOS – CP852, której zawartość pokazana jest na rysunku 1.
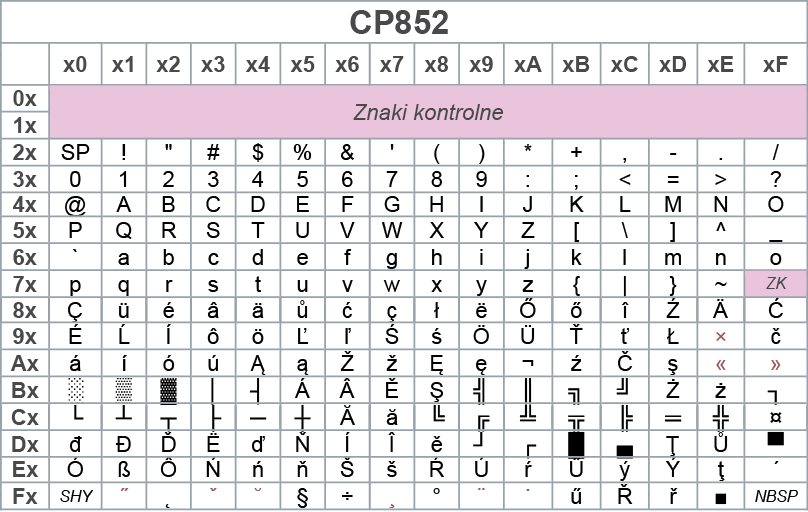
Rysunek 1
Później, w systemie Windows wykorzystywano inne strony kodowe, gdzie oczywiście podstawowe kody ASCII pozostawały bez mian, a inne były znaki o kodach powyżej 127 i ewentualnie poniżej 32. Rysunek 2 pokazuje zawartość strony kodowej Windows-1250, która też zawiera litery polskiego alfabetu, ale rozmieszczone inaczej niż w CP852.
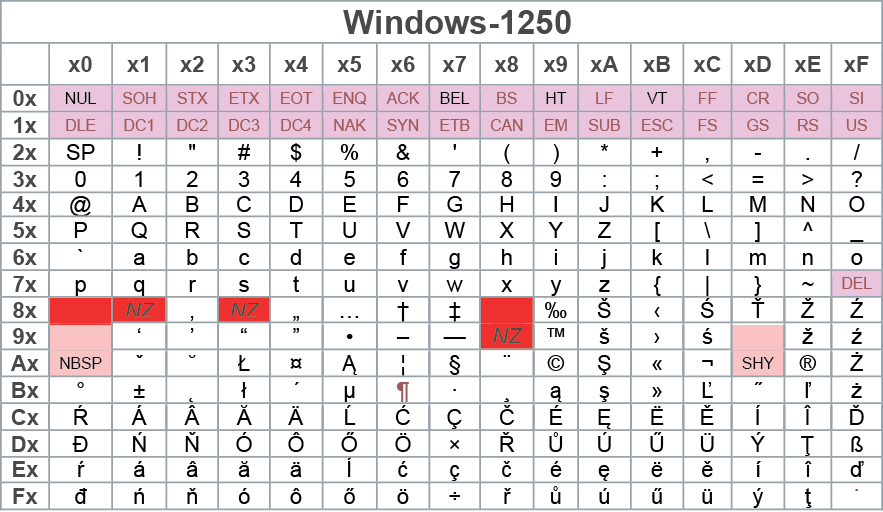
Rysunek 2
Z czasem dla rozwiązania problemów z kompatybilnością różnych systemów operacyjnych wprowadzono jeszcze inne strony kodowe według międzynarodowego standardu ISO. Rysunek 3 pokazuje zawartość strony kodowej ISO/IEC 8859-2 w wersji z roku 1999.
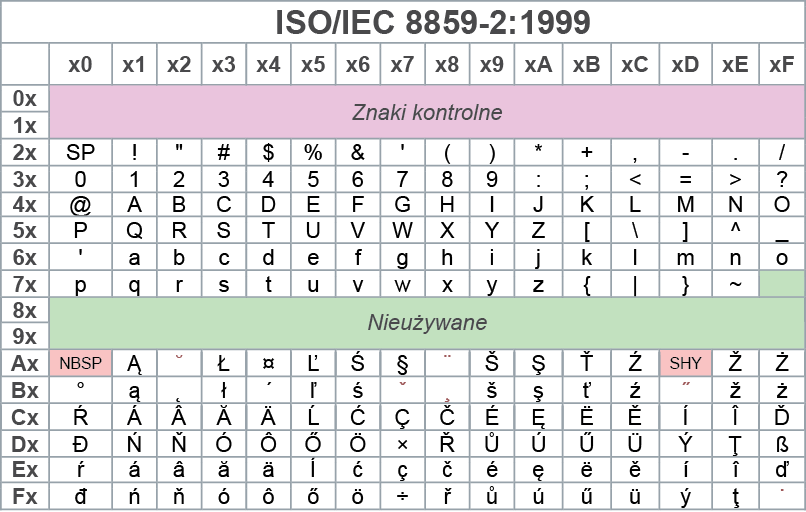
Rysunek 3
Rozmieszczenie polskich liter jest jeszcze inne, choć trochę podobne jak w Windows-1250. Wprowadzenie stron kodowych ISO nie do końca rozwiązało problemy. Usunięto je dopiero, wprowadzając Unikod i sposób kodowania UTF-8, co omawialiśmy dość dokładnie w cyklu „Wokół ArduinoV”. My takich problemów nie mamy, bo chcemy jedynie na wyświetlaczach graficznych sterowanych przez Arduino zobrazować wszystkie litery polskiego
alfabetu. Na pewno w grę wchodzą co najmniej trzy właśnie przypomniane stare strony kodowe, ale jak wiadomo (https://pl.wikipedia.org/wiki/Kodowanie_polskich_znak%C3%B3w), istniało też wiele innych sposobów, szereg stron kodowych używanych w Polsce. Moglibyśmy wykorzystać jedną z trzech przedstawionych stron kodowych, a dokładniej biorąc, wystarczyłoby w stronie CP437 podmienić tylko te definicje znaków, które mają kodować polskie litery „z ogonkami” według którejś z omówionych stron. Której?
W przypadku Arduino jest to w zasadzie obojętne! Możemy zachować zgodność z którąkolwiek z tych trzech stron. Ale możemy też zrobić własną, prywatną stronę kodową. W każdym razie na pewno w bibliotece Adafruit GFX zmienimy zawartość pliku glcdfont.c, by wstawić tam brakujące polskie litery „z ogonkami” . Ściślej biorąc, nie dodamy, tylko podmienimy, bo maksymalna liczba symboli – znaków nie może przekroczyć 256.
Gdy już zmodyfikujemy bibliotekę glcdfont, polskie litery „z ogonkami” zapewne i tak będziemy wyświetlać za pomocą prymitywnej metody .write(), podając kod – numer znaku według użytej strony kodowej. Zależnie od tego, jaką stronę kodową wykorzystamy, będziemy po prostu podawać inne numery – kody. ArduinoIDE wykorzystuje UTF-8. Można byłoby się zastanawiać, czy zastosowanie w miarę nowoczesnej strony kodowej ISO/IEC 8859-2 nie pozwoliłoby wprowadzać do szkicu Arduino napisów zawierających litery „z ogonkami” za pomocą klawiatury, bez wykorzystywania metody .write(). Być może jest to możliwe przy wykorzystaniu wstępnej konwersji numerów kodów, bo w sumie chodzi o to, żeby w szkicu .ino pojawiły się odpowiednie numery – kody. Jednak uzyskanie tego wiązałoby się z poważnymi kłopotami i wymagałoby dużej wiedzy o komputerach, systemach operacyjnych i czcionkach.
Dlatego lepiej, bezpieczniej pozostać przy prymitywnej, ale prostej w działaniu metodzie .write().
Wracamy do meritum: w języku polskim mamy 18 liter „z ogonkami”, a mianowicie:
Ą, Ć, Ę, Ł, Ń, Ó, Ś, Ż, Ź,
ą, ć, ę, ł, ń, ó, ś, ż, ź.
Niektórzy rezygnują z definiowania wielkich liter Ą, Ę, Ń. Uznają je za niepotrzebne, ponieważ żaden polski wyraz nie zaczyna się od którejkolwiek z tych liter. To prawda, ale czasem chcemy coś napisać WIELKIMI LITERAMI i wtedy i one mogą być potrzebne. Dlatego należałoby raczej zdefiniować wszystkie 18 symboli.
Możemy to zrobić „na piechotę”, o czym za chwilę. Ale oczywiście ktoś zrobił już za nas całą czarną robotę i w Internecie przy niewielkim wysiłku można znaleźć przygotowany plik glcdfont.c z kompletem liter polskiego alfabetu.
I w opisanych wcześniej stronach kodowych, i w większości samodzielnie „polonizowanych” stron kodowych, polskie litery „z ogonkami” są umieszczone w rozszerzonej części zbioru, czyli mają kody powyżej 127.
Dobrze, ale tak być nie musi!
Wróćmy do oryginalnego pliku glcdfont.c i strony kodowej 437. Jeszcze raz na fotografii 4 pokazane są dostępne tam znaki o kodach 0…127. Zakresu drukowalnych kodów ASCII, czyli 32…127, nie możemy zmieniać, bo spowodujemy poważny bałagan. Możemy natomiast podmienić znaki o kodach mniejszych od 32. Tak, ale pamiętamy, że nie możemy wykorzystać kodów 10 (LF) oraz 13 (CR), które są kodami sterującymi.
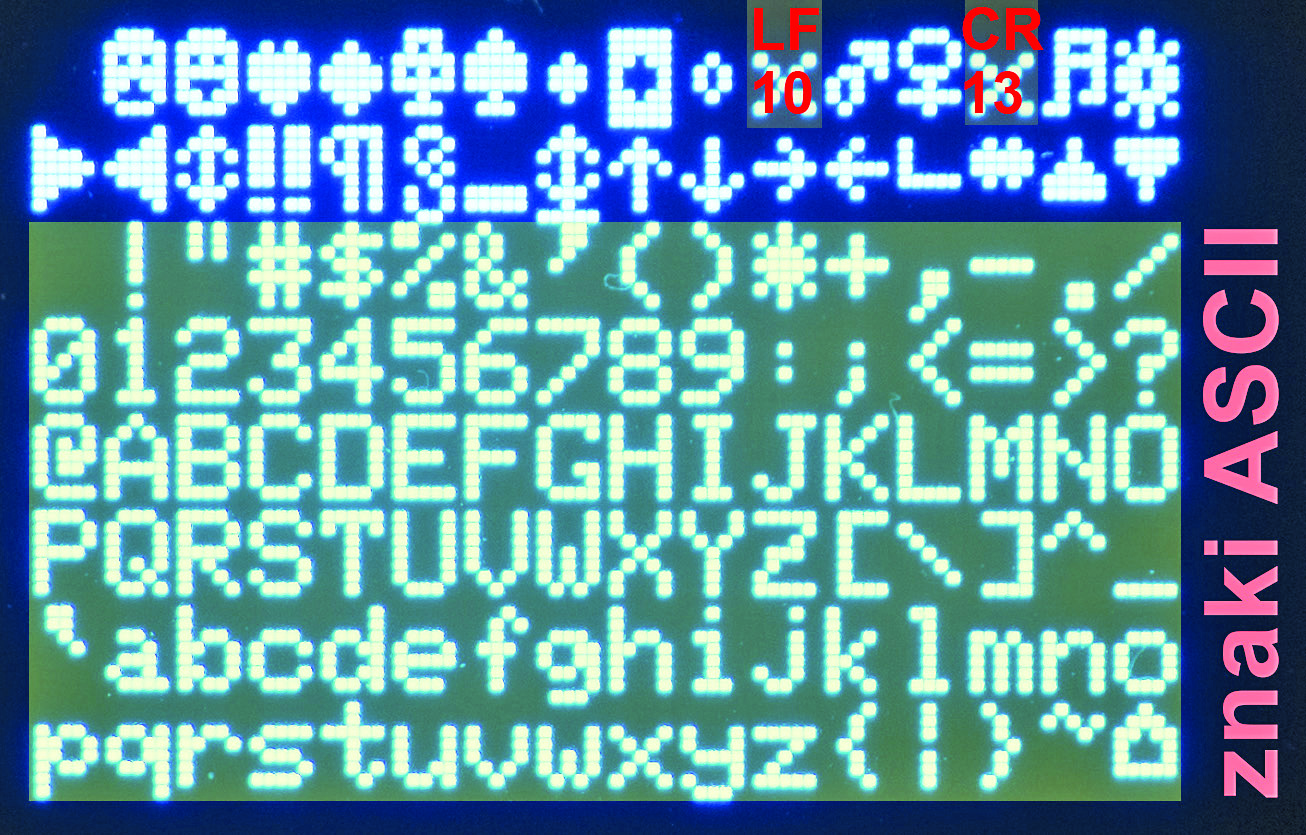
Fotografia 4
Tak się ładnie składa, że pomiędzy kodem 13 (CR) a kodem 32 (spacja) mamy 18 miejsc – dokładnie tyle, ile nam potrzeba. Możemy dowolnym kodom 14…31 przypisać dowolne polskie litery. Na przykład przyporządkowanie może być następujące:
kod – litera
14 – Ą,
15 – Ć,
16 – Ę,
17 – Ł,
18 – Ń,
19 – Ó,
20 – Ś,
21 – Ż,
22 – Ź,
23 – ą,
24 – ć,
25 – ę,
26 – ł,
27 – ń,
28 – ó,
29 – ś,
30 – ż,
31 – ź.
Czyli na przykład aby wyświetlić na ekranie małą literkę ć, w szkicu umieścimy instrukcję: .write(24);
Przyznam, że do pierwszych prób wykorzystałem plik znaleziony gdzieś w Internecie. Oczywiście definicje polskich liter znajdowały się tam w rozszerzonej części kodów powyżej 127, więc przeniosłem je „niżej”, w miejsca definiowane przez kody 14…31. Ściślej biorąc, oryginalnych definicji kodów 14…31 nie kasowałem, tylko wyłączyłem znakami komentarza /* */
Zmieniłem zawartość oryginalnego, bibliotecznego pliku glcdfont.c i po prostu go zapisałem.
Następnie wykorzystałem wcześniejszy program A2302.ino (omawiany w poprzednim odcinku kursu, dostępny w Elportalu). Bez żadnych mian skompilowałem go jeszcze raz, by skorzystał z fontu z mojego zmodyfikowanego pliku glcdfont.c. Uzyskałem na ekranie obraz, pokazany na fotografii 5.
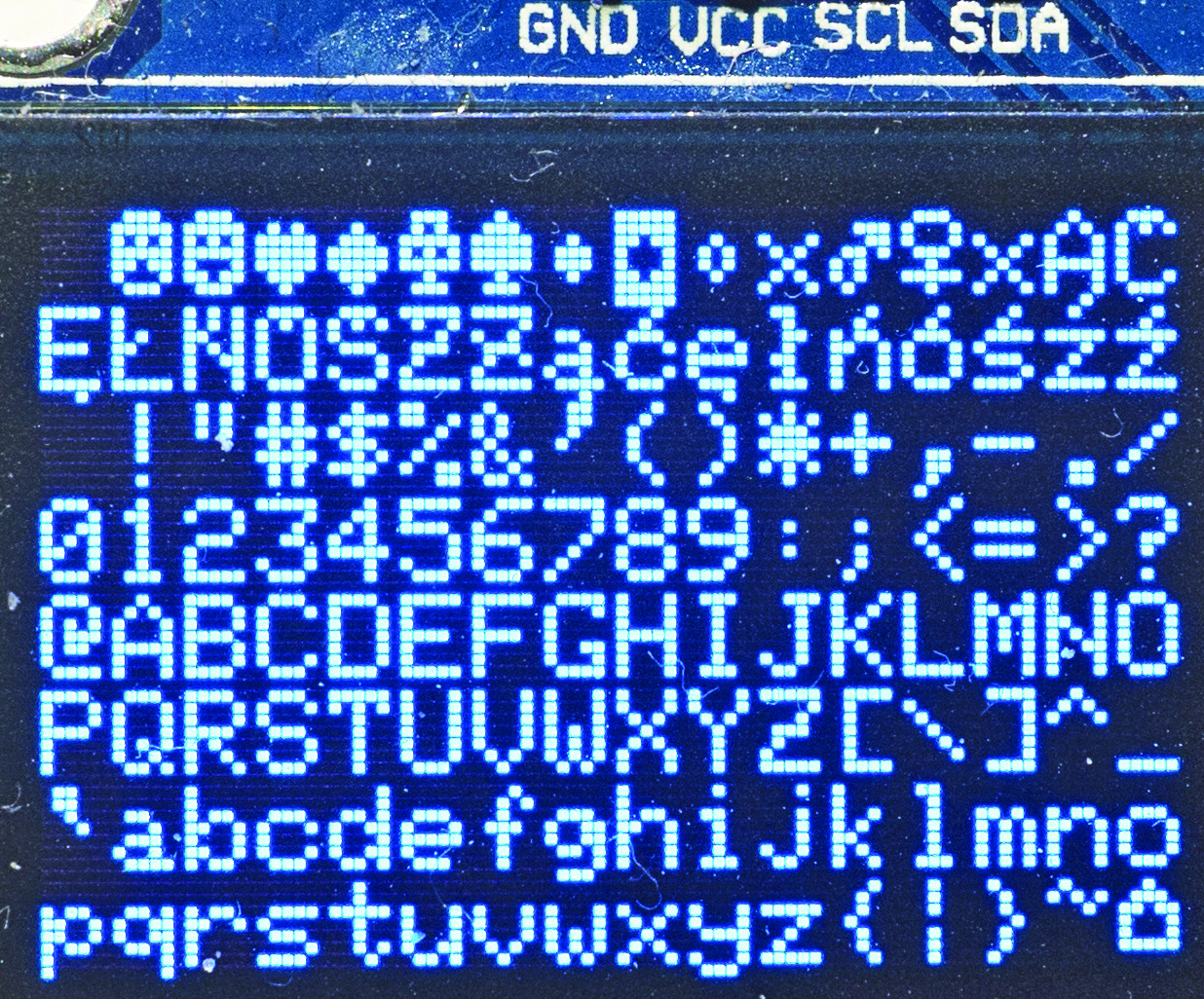
Fotografia 5
Zadanie zostało zrealizowane!
Jednak nie wszystkie kształty liter podobały mi się. Wprawdzie matryca 5×8 nie powoli wyświetlić ładnych liter, jednak uznałem, że znaki reprezentujące wielkie litery Ć, Ó, Ś, Ź, Ż trzeba zmienić.
Jest to bardzo łatwe i można to zrobić ręcznie dosłownie w ciągu kilku, maksymalnie kilkunastu minut. Mianowicie najpierw trzeba na siatce 5×8 narysować symbole o potrzebnym kształcie. W przypadku liter dolna linia wskazana na rysunku 6 czerwoną strzałką ma być pusta, a każda litera ma mieć wielkość 5×7 pikseli.
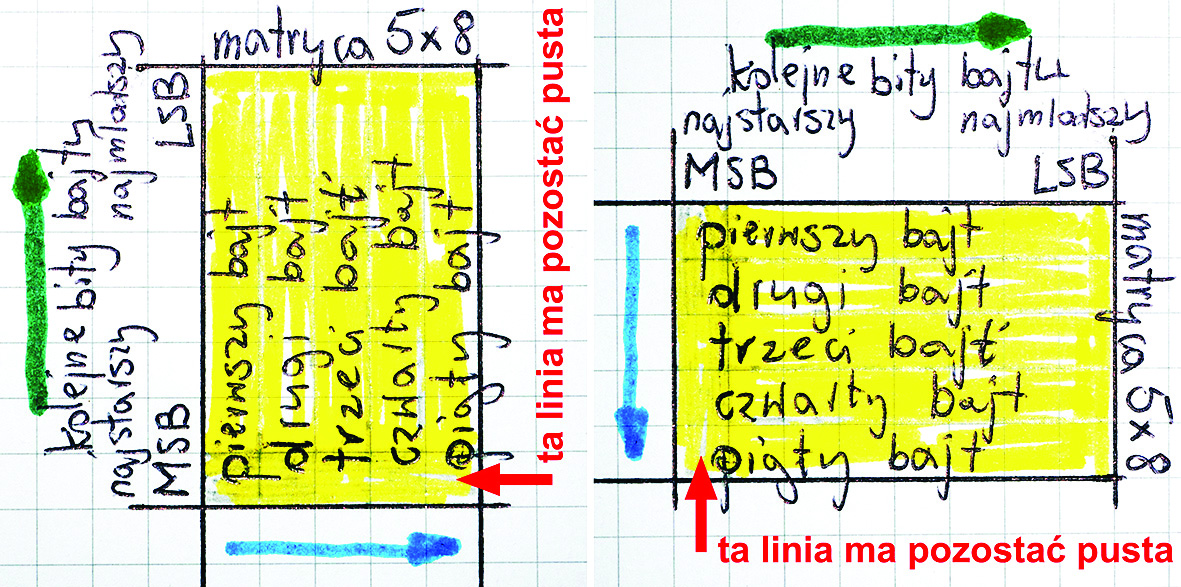
Rysunek 6
Przy takim projektowaniu pomocny będzie rysunek 7. Najpierw trzeba na takich matrycach zaprojektować wygląd litery, wypełniając jakimś kolorem poszczególne piksele. Na tak projektowany na kartce symbol trzeba spojrzeć z daleka, z odległości kilku metrów.
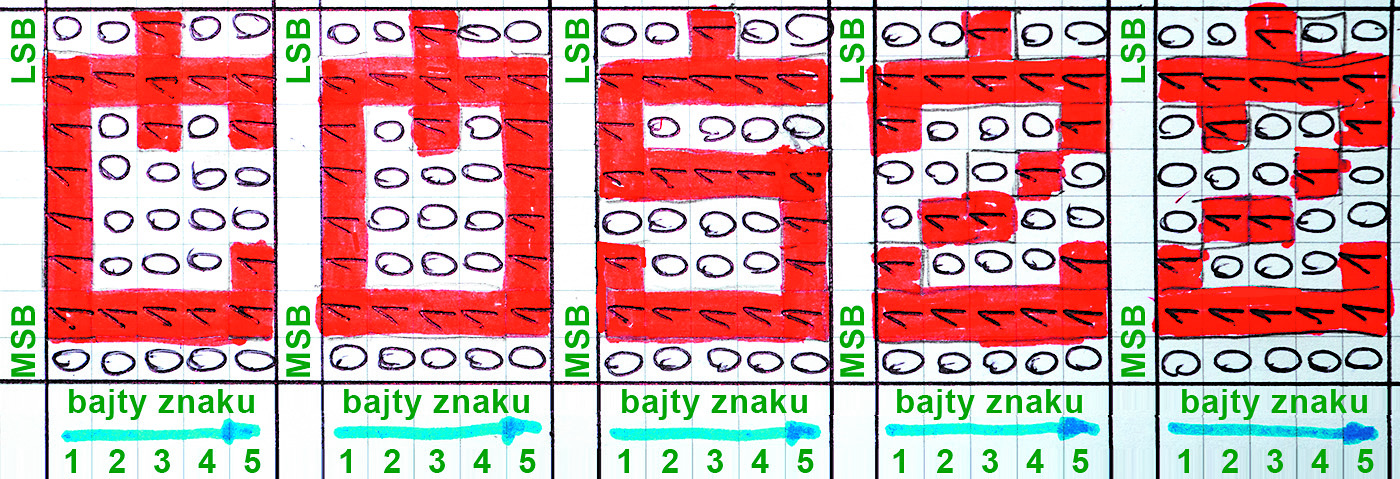
Rysunek 7
W przypadku znaku składającego się z 35 pikseli (5×7) nie ma wprawdzie żadnych szans na uzyskanie ładnego wyglądu pięciu wspomnianych liter: Ć, Ó, Ś, Ź, Ż, jednak uznałem, że w ich przypadku trzeba zmniejszyć wysokość litery podstawowej o jeden piksel, żeby zrobić miejsce na górną kropkę czy kreskę.
Najpierw czerwonym flamastrem w matrycach 5×8 zaznaczyłem aktywne piksele. Potem w tych kratkach wpisałem jedynki. Pozostałe kratki wypełniłem zerami. I w ten bardzo prosty sposób, bez żadnego przeliczania, miałem gotowe bajty w postaci ośmiobitowych liczb dwójkowych. Pokazane to jest wyraźnie na fotografii 8.
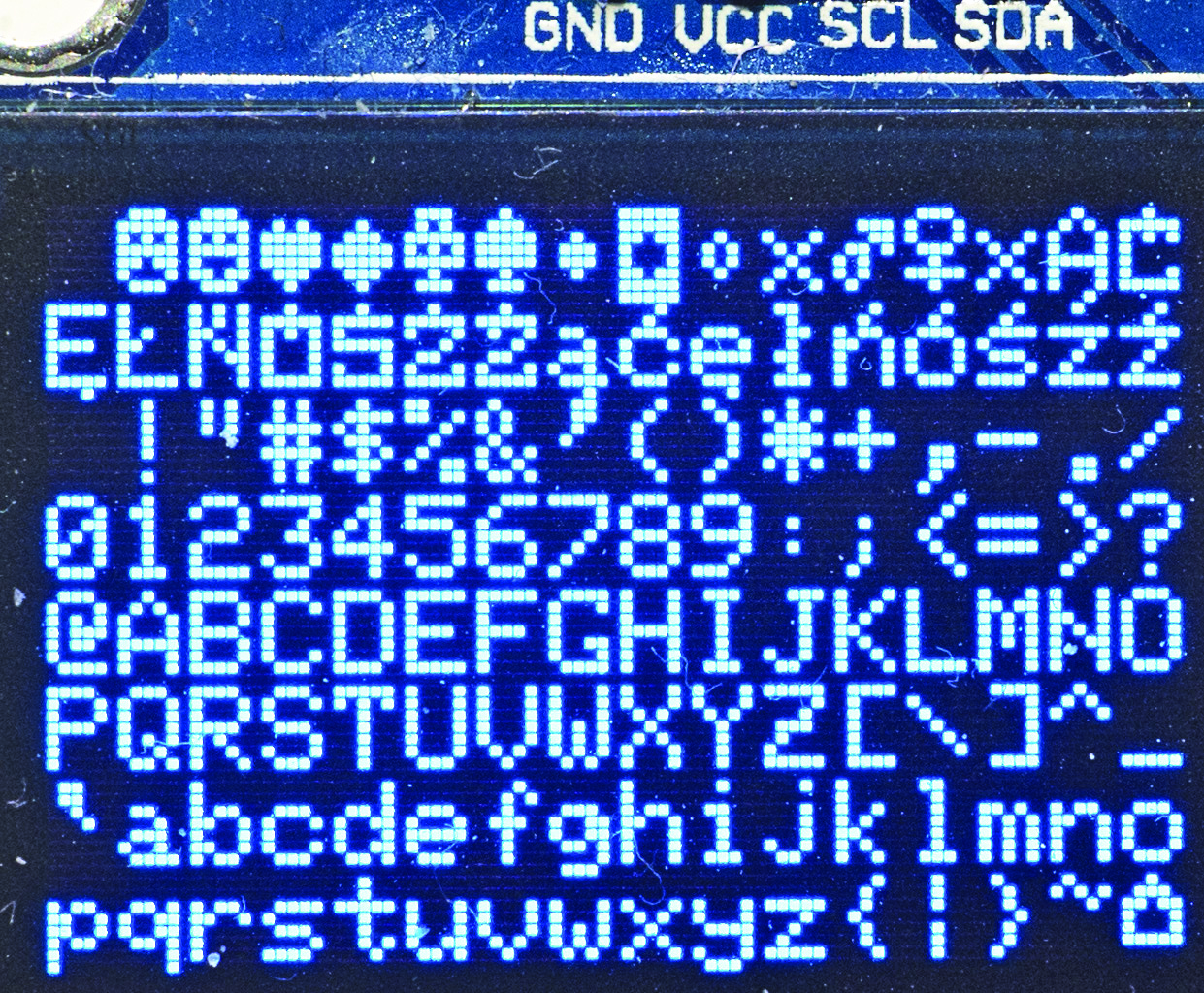
Fotografia 8
Jak pamiętamy, w bibliotecznym pliku glcdfont.c bajty przedstawione są w postaci dwucyfrowych liczb szesnastkowych (HEX). Ale my wcale nie musimy zamieniać liczb dwójkowych (BIN) na postać szesnastkową (HEX). Możemy do pliku glcdfont.c śmiało wpisać uzyskane z ręcznego kodowania liczby dwójkowe, stawiając tylko przed nimi 0b (b – binary).
Fragment zmodyfikowanego pliku glcdfont.c pokazany jest w szkicu 1. Zielonym kolorem wyróżniony jest fragment nieczynny, zakomentowany, zawierający definicje znaków CP437. Warto go zachować na wszelki wypadek. Czerwonym kolorem wyróżnione są nieskasowane wcześniejsze definicje dużych liter Ć, Ó, Ś, Ź, Ż, które mi się nie podobały i które widać na fotografii 5. Kody 32 i wyższe nie są zmienione.
Szkic 1: UWAGA KOLORY!!!!
0xFF, 0xE7, 0xDB, 0xE7, 0xFF, //10 LF - kod sterujący \n 0x30, 0x48, 0x3A, 0x06, 0x0E, //11 0x26, 0x29, 0x79, 0x29, 0x26, //12 0x40, 0x7F, 0x05, 0x05, 0x07, //13 CR kod sterujący \r /* //zakomentowane, nieaktywne oryginalne znaki CP437 o kodach 14 ...31: 0x40, 0x7F, 0x05, 0x25, 0x3F, //14 0x5A, 0x3C, 0xE7, 0x3C, 0x5A, //15 (...) 0x30, 0x38, 0x3E, 0x38, 0x30, //30 0x06, 0x0E, 0x3E, 0x0E, 0x06, //31 */ // polskie "ogonki" - nowe, podmienione kody 14 ... 31 0b01111100, 0b00010010, 0b00010001, 0b10010010, 0b01111100,//14 Ą - A_ogonek 0b01111110, 0b01000010, 0b01000111, 0b01000010, 0b01100110,//15 Ć - C_acute // 0b00111110, 0b01000001, 0b01000011, 0b01000001, 0b00100010,//15 Ć - C_acute 0b01111111, 0b01001001, 0b01001001, 0b11001001, 0b01000001,//16 Ę - E_ogonek 0b01111111, 0b01001000, 0b01000100, 0b01000000, 0b01000000,//17 Ł - N_stroke 0b01111111, 0b00000100, 0b00001011, 0b00010000, 0b01111111,//18 Ń - N_acute 0b01111110, 0b01000010, 0b01000111, 0b01000010, 0b01111110,//19 Ó - O_acute // 0b00111110, 0b01000001, 0b01000011, 0b01000001, 0b00111110,//19 Ó - O_acute 0b01101110, 0b01001010, 0b01001011, 0b01001010, 0b01111010,//20 Ś - S_acute // 0b00100110, 0b01001001, 0b01001011, 0b01001001, 0b00110010,//20 Ś - S_acute 0b01100110, 0b01010010, 0b01010011, 0b01001010, 0b01100110,//21 Ż - Z_dot // 0b01100001, 0b01011011, 0b01001001, 0b01001101, 0b01000011,//21 Ż - Z_dot 0b01100010, 0b01010110, 0b01010011, 0b01001010, 0b01100110,//22 Ź - Z_acute // 0b01100101, 0b01011001, 0b01001001, 0b01001101, 0b01010011,//22 Ź - Z_acute 0b00100000, 0b01010100, 0b01010100, 0b11111000, 0b01000000,//23 ą - a_ogonek 0b00111000, 0b01000100, 0b01000110, 0b01000101, 0b00101000,//24 ć - c_acute 0b00111000, 0b01010100, 0b01010100, 0b11010100, 0b00011000,//25 ę - e_ogonek 0b00000000, 0b01010001, 0b01111111, 0b01000100, 0b00000000,//26 ł - l_stroke 0b01111100, 0b00001000, 0b00000110, 0b00000101, 0b01111000,//27 ń - n_acute 0b00111000, 0b01000100, 0b01000110, 0b01000101, 0b00111000,//28 ó - o_acute 0b01001000, 0b01010100, 0b01010110, 0b01010101, 0b00100100,//29 ś - s_acute 0b01000100, 0b01100100, 0b01010101, 0b01001100, 0b01000100,//30 ż - z_acute 0b01000100, 0b01100100, 0b01010110, 0b01001101, 0b01000100,//31 ź - z_dot // tu zaczynają się niezmienione, drukowalne kody ASCII: 0x00, 0x00, 0x00, 0x00, 0x00,//32 SPACE 0x00, 0x00, 0x5F, 0x00, 0x00, (...)
Tak zmodyfikowany plik o nazwie glcdfont_pl_14_31.c dostępny jest w Elportalu wśród materiałów dodatkowych do tego numeru. Gdy w bibliotece Adafruit GFX podmienisz oryginalny plik gldcfont.c i wykorzystasz szkic A2302.ino albo A2501.ino, zapewne i Ty na ekranie modułu ze sterownikiem SH1106 zobaczysz widok jak na fotografii 8.
Fotografia 8
I tak oto mamy zmodyfikowany podstawowy font 5×7 ze wszystkimi literami polskiego alfabetu. Liter „z ogonkami” nie możemy w prosty sposób wykorzystać przy wyświetlaniu napisów za pomocą jakże pożytecznej metody .print(), gdzie tekst do wyświetlenia po prostu bierzemy w podwójne cudzysłowy „”. Nie przekażemy ich także do metody print(), która drukuje pojedyncze znaki w pojedynczych cudzysłowach.
Wprawdzie opisywane tu wyświetlanie na ekranie liter „z ogonkami” nie jest wygodne, bo trzeba korzystać z metody .write() i podawać jako argument nasz prywatny numer kodu, jak na razie w zakresie 14…31. Niemniej cieszymy się, bo skutecznie spolonizowaliśmy podstawowy font 5×7 Adafruit GFX. Możemy teraz prawidłowo wypisywać na ekranie dowolne polskie teksty, w tym chyba najbardziej popularny testowy: „Zażółć gęślą jaźń”. Kod samego wypisywania tekstu pokazany jest w szkicu 2 (dostępny także w Elportalu jako A2502.ino), a efekt widać na fotografii 9.
Szkic 2:
// w funkcji setup()
// wyswietlamy klasyczny tekst:
wysw.print("za");
wysw.write(30); // ż
wysw.write(28); // ó
wysw.write(26); // ł
wysw.write(24); // ć
wysw.print(" g");
wysw.write(25); // ę
wysw.write(29); // ś
wysw.print('l'); // litera l
wysw.write(23); // ą
wysw.print(" ja");
wysw.write(31); // ź
wysw.write(27); // ń
wysw.println(); // nowa linia
wysw.println(); // nowa linia
wysw.print("ZA");
wysw.write(21); // Ż
wysw.write(19); // Ó
wysw.write(17); // Ł
wysw.write(15); // Ć
wysw.print(" G");
wysw.write(16); // Ę
wysw.write(20); // Ś
wysw.print('L'); // litera L
wysw.write(14); // Ą
wysw.print(" JA");
wysw.write(22); // Ź
wysw.write(18); // Ń
wysw.display(); //wyświetl

Fotografia 9
Ulepszonymi fontami GFX zajmiemy się w następnym odcinku i wtedy okaże się, że jest to zadanie znacznie trudniejsze i znacznie bardziej pracochłonne, niż polonizowanie fontu podstawowego 5×7. Na razie nie będziemy wchodzić w szczegóły, ale by zachować ten sam sposób wprowadzania polskich liter i w nowszych fontach GFX, i w starym klasycznym 5×7, przenieś samodzielnie w pliku glcdfont.c polskie litery z zakresu kodów 14…31 do zakresu 128…145. Tego wyższego zakresu celowo nie wybraliśmy od razu, by pokazać, że „polonizowanie” można przeprowadzić na wiele sposobów.
Teraz po prostu przenosimy definicje 18 polskich liter tuż powyżej zakresu ASCII. Oryginalne kody 128…145 strony CP437 zamieniamy na polskie litery. Tak zmodyfikowany plik dostępny jest w Elportalu, ma nazwę glcdfont_pl_128_145.c i można go po prostu umieścić w bibliotece zamiast oryginalnego, oczywiście po zmianie nazwy. Tak, ale proponuję, żebyś taką przeróbkę pliku glcdfont.c przeprowadził samodzielnie.
Dostępny w Elportalu szkic A2503.ino z użyciem tak zmodyfikowanego pliku glcdfont.c wyświetla znaki o kodach 32…159 – efekt na fotografii 10.

Fotografia 10
Teraz po zmianie na stronie kodowej miejsca wstawienia zestawu polskich liter, do metody .write() musimy podawać inne numery – kody. Przydatna będzie do tego tabelka, pokazana na rysunku 11.

Rysunek 11
W ramach ćwiczeń domowych samodzielnie zmodyfikuj szkic A2502.ino, nazwij go A2504.ino, żeby wyświetlić napis, a raczej napisy zażółć gęśla jaźń tak, jak na fotografii 9. Ja przy okazji realizacji szkicu 3, gdzie dwukrotne przejście do nowej linii realizują dwa inne polecenia, leciutko poprawiłem też w pliku glcdfont.c definicję dużej litery Ź, co widać na fotografii 12.
Szkic 3:
//po zmianie pliku glcdfont.c
// w funkcji setup()
// Wyświetlamy klasyczny tekst:
wysw.print("za");
wysw.write(144); // ż
wysw.write(142); // ó
wysw.write(140); // ł
wysw.write(138); // ć
wysw.print(" g");
wysw.write(139); // ę
wysw.write(143); // ś
wysw.print('l'); //litera l
wysw.write(137); // ą
wysw.print(" ja");
wysw.write(145); // ź
wysw.write(141); // ń
//wysw.println(); //nowa linia
//wysw.println();//druga nowa linia
wysw.print("\n"); //nowa linia
wysw.write(10);//druga nowa linia
wysw.print("ZA");
wysw.write(135); // Ż
wysw.write(133); // Ó
wysw.write(131); // Ł
wysw.write(129); // Ć
wysw.print(" G");
wysw.write(130); // Ę
wysw.write(134); // Ś
wysw.print('L'); // litera L
wysw.write(128); // Ą
wysw.print(" JA");
wysw.write(136); // Ź
wysw.write(132); // Ń
wysw.display(); //wyświetl

Fotografia 12
Jeżeli chcesz, możesz oczywiście eksperymentować, do czego zresztą zachęcam. Możesz umieścić polskie litery w innych miejscach tabeli kodowej, niekoniecznie w proponowanej kolejności i niekoniecznie w jednym bloku, tylko zastępując dowolnie wybrane, zupełnie nieprzydatne, dziwne symbole.
Koniecznie jednak poćwicz wykorzystanie kodów 128…145, ponieważ w następnej kolejności podejmiemy próbę spolonizowania ulepszonych fontów GFX. A wtedy z pewnych względów, które dokładniej omawiamy w następnym odcinku (UR028), wygodne okaże się właśnie wykorzystanie obok klasycznych kodów ASCII (32…127), także kodów po nich następujących.
Piotr Górecki


