

Kurs Arduino – Polonizowanie fontów GFX
Zgodnie z zapowiedzią podejmiemy próbę spolonizowania ulepszonych fontów GFX, które omawiane były we wcześniejszych odcinkach cyklu.Na początek musimy przypomnieć, że aby wyświetlić na ekranie literę, cyfrę lub inny symbol, podajemy jej numer – liczbę 8-bitową. Jest to albo kod ASCII (liczba 1…127), albo kod znaku z zestawu rozszerzonego (128…255). W przypadku Arduino liczba – kod z zakresu 1…255, powinna wyświetlić malutki obrazek – literkę, cyferkę lub inny symbol według strony kodowej CP437. Zawartość tych malutkich obrazków brana jest z zapisanej w pamięci procesora tabeli, definiującej taki czy inny font. W przypadku podstawowego kroju 5×7 z pliku glcdfont.c, każde kolejne 5 bajtów tabeli definiuje wygląd kolejnego znaku. Chcąc wyświetlić symbol o kodzie – numerze N, po prostu sięgamy do pięciu kolejnych bajtów. Nie ma problemu, bo najprościej biorąc, pierwszy z tych bajtów ma numer N*5.
W fontach GFX zasada jest znacząco inna. Wiemy już, że szerokość poszczególnych znaków w krojach Serif oraz Sans nie jest jednakowa. Przykładowo do opisania mniejszego znaku, choćby chudziutkiej literki i, potrzeba mniej bitów niż do opisania szerokiej literki w lub m. Jeszcze mniej potrzeba do opisania wyglądu cudzysłowów, przecinka lub kropki.
W związku z tym sposób definiowania poszczególnych znaków jest zdecydowanie inny niż w foncie podstawowym.
Problem w tym, że w pliku definiującym dowolny font GFX obrazeczki – bitmapy poszczególnych znaków mają różne wielkości i nie są rozdzielone. Bez dodatkowych informacji nie sposób się zorientować, w którym bajcie kończy się opis bitmapy jednego znaku i zaczyna opis następnej. Dlatego w plikach definiujących fonty GFX zawarte są dwie tabele: jedna (Bitmaps) opisuje wygląd kolejnych obrazeczków, a druga (Glyphs – glify) określa między innymi numery bajtów, gdzie zaczyna się opis kolejnych symboli. W bibliotece /Dokumenty/Arduino/libraries/ Adafruit-GFX-Library-master znajdziemy plik gfxfont.h określający strukturę takiego opisu za pomocą sześciu liczb. Spolonizowaną wersję pokazuje szkic 1.
Szkic 1:
//Struktura fontów wersji Adafruit_GFX (v.1.1 i nowszych)
(...)
// dla każdego symbolu zawartego w foncie zostaje określone:
typedef struct {
uint16_t bitmapOffset; //numer bajtu, gdzie zaczyna się opis bitmapy
uint8_t width; //szerokość bitmapy w pikselach
uint8_t height; //wysokość bitmapy w pikselach
uint8_t xAdvance; //skok kursora po narysowaniu bitmapy
int8_t xOffset; //przesunięcie w poziomie lewego dolnego rogu
int8_t yOffset; //przesunięcie w pionie lewego dolnego rogu
} GFXglyph;
(...)
Gdy chcemy wyświetlić jakiś znak z użyciem fontu GFX, oczywiście podajemy numer znaku, czyli jego kod ASCII. Program w tablicy Glyphs tego fontu najpierw znajduje opis danego symbolu – sześć liczb według szkicu 1. Pierwsza liczba to numer bajtu w tabeli Bitmaps, gdzie zaczyna się opis bitmapy tego symbolu. Dwie następne określają wielkość bitmapy, co pozwala też obliczyć liczbę bajtów tego symbolu. Czwarta liczba pokazuje, o ile pikseli należy przesunąć w poziomie kursor po wyświetleniu bitmapy.
Jak wiadomo, zasadniczo kursor określa, gdzie będzie górny lewy róg bitmapy. Wiemy, że jest to przyczyną kłopotów w foncie podstawowym (glcdfont.c), dlatego w fontach GFX mamy dwie dodatkowe liczby, pokazujące przesunięcie dolnego lewego rogu obrazka w stosunku do pozycji kursora.
Mając takie informacje, program pobiera z tabeli Bitmaps potrzebne bajty i wyświetla symbol na ekranie.
Problem z fontami GFX
Opisana zasada jest dość prosta, ale pewne szczegóły mocno utrudniają wyświetlanie polskich liter.
Otóż takie definicje ulepszonych, ładniejszych fontów GFX zajmują dużo więcej miejsca niż prymitywny font glcdfont.c. Aby oszczędnie gospodarować małą pamięcią programu w Arduino, definicje fontów GFX z reguły obejmują tylko znaki ASCII o kodach od 32 do 126, czyli szesnastkowo 0x20…0x7E. Jest to podane na końcu pliku definiującego font. Na przykład w pliku FreeSerif9pt7b.h mamy:
const GFXfont FreeSerif9pt7b PROGMEM={
(uint8_t *)FreeSerif9pt7bBitmaps,
(GFXglyph *)FreeSerif9pt7bGlyphs,
0x20, 0x7E, 22 };
gdzie 22 to odstęp między liniami tekstu.
Gdy więc podany zostaje numer – kod ASCII do wyświetlenia, wtedy najpierw od tego numeru odejmowana jest liczba 32 (0x20) i tak uzyskana liczba określa numer znaku najpierw z tablicy Glyphs, potem w tablicy Bitmaps.
Poważnie utrudnia to umieszczenie polskich liter poniżej kodu 32. Wymagałoby to bowiem żmudnej zmiany pierwszej liczby we wszystkich liniach tabeli Glyphs.
Dużo prościej jest umieścić polskie litery tuż powyżej kodów ASCII, czyli na pozycjach 128…145. Aby się więcej nauczyć, zróbmy własny font.
Generowanie fontu GFX
Fonty GFX Arduino są bitmapowe, a w komputerach wykorzystujemy o wiele lepsze fonty wektorowe w najróżniejszych odmianach. Opracowano sposoby zamiany fontów wektorowych na bitmapowe GFX, na przykład na stronie:
http://oleddisplay.squix.ch/
Dla przykładu wybierzemy font Open Sans Condensed. Znaki na ekranie będą miały wielkość 10 (później przekonamy się jakich jednostek), będą skondensowane, wąskie, więc w linii zmieści się sporo znaków. Chcemy wykorzystać odmianę Plain, czyli Normal. (ale okaże sie, że otrzymamy wersję pogrubioną Bold). Format wyjściowy ma być fontem GFX według rysunku 1.
Rysunek 1
Po kliknięciu Create zobaczymy tabelkę z kodem, który skopiujemy do pliku tekstowego (ja do tego wykorzystuję Notepad++). Plik zapiszemy pod nazwą Open_Sans_Condensed_Bold_10.h i będzie to oryginalna wersja kontrolna. Ten sam plik zapiszemy też drugi raz pod nazwą FontEdW.h i tak się będzie nazywał nasz font, który spróbujemy spolonizować. Kluczowe fragmenty pokazane są w szkicu 2.
Szkic 2:
(...)
const uint8_t FontEdWBitmaps[] PROGMEM = {
// Bitmap Data:
0x00, // ' '
0xAA,0x88, // '!'
0xEE,0xC0, // '"'
(...)
0xE0, // '-'
0x80, // '.'
0x11,0x08,0xC4,0x23,0x00, // '/'
0x71,0x4D,0xB6,0xD9,0x47,0x00, // '0'
(...)
0x71,0x45,0x14,0x73,0x68,0x80, // 'A'
0xE5,0x29,0xCB,0x5B,0x80, // 'B'
0x39,0x04,0x30,0x41,0x03,0x80, // 'C'
0xE2,0x49,0x26,0x92,0x4E,0x00, // 'D'
0xE8,0x8C,0x88,0xE0, // 'E'
(...)
0xF1,0x18,0x8F,0x00, // 'z'
0x31,0x08,0xCC,0x30,0x84,0x30, // '{'
0xAA,0xAA,0x80, // '|'
0xC2,0x10,0xC3,0x31,0x08,0xC0 // '}'
// ' ' spacja - kod 127 0 bajtów
// poniżej dodane bitmapy kodów 128 ... 145:
0x71,0x45,0x14,0x73,0x68,0x80,//'A' 128 6 bajtów
0x39,0x04,0x30,0x41,0x03,0x80, // 'C' 6 bajtów
0xE8,0x8C,0x88,0xE0, // 'E' 4 bajty
0x88,0x88,0x88,0xE0, // 'L' 4 bajty
0x96,0xB5,0x6B,0x5A,0x40, // 'N' 5 bajtów
0x78,0x93,0x36,0x6C,0xC9,0x1E,0x00,//'O' 7 bajtów
0x76,0x30,0xC3,0x1B,0x80, // 'S' 5 bajtów
0xF1,0x08,0xC4,0x63,0xC0, // 'Z' 5 bajtów
0xF1,0x08,0xC4,0x63,0xC0, // 'Z' 5 bajtów
0x70,0x9D,0xA7,0x00, // 'a' 4 bajty
0x76,0x31,0x87,0x00, // 'c' 4 bajty
0x71,0x6F,0x90,0x70, // 'e' 4 bajty
0xDB,0x6D,0xB0, // 'l' 3 bajty
0xE5,0xAD,0x6B,0x00, // 'n' 4 bajty
0x73,0x6D,0x96,0x70, // 'o' 4 bajty
0x76,0x18,0x6E,0x00, // 's' 4 bajty
0xF1,0x18,0x8F,0x00, // 'z' 4 bajty
0xF1,0x18,0x8F,0x00, // 'z' kod 145 4 bajty
};
const GFXglyph FontEdWGlyphs[] PROGMEM = {
//bitmapOffset, width, height, xAdvance, xOffset, yOffset
{ 0, 1, 1, 3, 0, 0 }, // ' '
{ 1, 2, 7, 4, 1, -7 }, // '!'
{ 3, 4, 3, 5, 1, -7 }, // '"'
(...)
{ 411, 5, 5, 5, 0, -5 }, // 'z'
{ 415, 5, 9, 5, 0, -7 }, // '{'
{ 421, 2, 9, 6, 2, -7 }, // '|'
{ 424, 5, 9, 5, 0, -7 } // '}'
// poniżej kod 127 - skopiowana spacja
{ 0, 1, 1, 3, 0, 0 }, // ' ' 0 bajtów
// poniżej dodane opisy glifów kodów 128...145:
{ 145, 6, 7, 6, 0, -7 }, // 'A' 6 bajtów
{ 156, 6, 7, 6, 0, -7 }, // 'C' 6 bajtów
{ 168, 4, 7, 5, 1, -7 }, // 'E' 4 bajty
{ 199, 4, 7, 5, 1, -7 }, // 'L' 4 bajty
{ 210, 5, 7, 7, 1, -7 }, // 'N' 5 bajtów
{ 215, 7, 7, 7, 0, -7 }, // 'O' 7 bajtów
{ 240, 5, 7, 5, 0, -7 }, // 'S' 5 bajtów
{ 281, 5, 7, 5, 0, -7 }, // 'Z' 5 bajtów
{ 411, 5, 5, 5, 0, -5 }, // 'z' 5 bajtów
{ 304, 5, 5, 6, 0, -5 }, // 'a' 4 bajty
{ 313, 5, 5, 5, 0, -5 }, // 'c' 4 bajty
{ 322, 6, 5, 6, 0, -5 }, // 'e' 4 bajty
{ 353, 3, 7, 3, 0, -7 }, // 'l' 3 bajty
{ 361, 5, 5, 6, 1, -5 }, // 'n' 4 bajty
{ 365, 6, 5, 6, 0, -5 }, // 'o' 4 bajty
{ 382, 5, 5, 5, 0, -5 }, // 's' 4 bajty
{ 411, 5, 5, 5, 0, -5 }, // 'z' 4 bajty
{ 411, 5, 5, 5, 0, -5 }, // 'z' 4 bajty
};
const GFXfont FontEdW PROGMEM = {
(uint8_t *)FontEdWBitmaps,
(GFXglyph *)FontEdWGlyphs,0x20, 0x7E, 14};
Wersja kontrolna w pliku Open_Sans_Condensed_Bold_10.h zapewne okaże się przydatna, bo nie tylko powoli sprawdzić, jak wyglądają znaki, ale też posłuży do poszukiwania błędów w modyfikowanym pliku FontEdW.h. A o takie błędy nietrudno, choć w sumie przeróbka jest prosta, tylko nieco żmudna i czasochłonna.
Jeżeli zmieniamy nazwę pliku na FontEdW.h, zmieniamy też nazwy dwóch zawartych w nim tablic:
FontEdWBitmaps[]
FontEdWGlyphs[]
a na samym dole pliku także:
const GFXfont FontEdW PROGMEM = { (uint8_t *)FontEdWBitmaps,(GFXglyph *)FontEdWGlyphs,0x20, 0x7E,14};
czyli w miejscu, gdzie deklarujemy te tablice i gdzie zawarta jest informacja, że nasz font obejmuje znaki o kodach od 0x20 (32) do 0x7E (126) i że odległość między kolejnymi wierszami tekstu wynosi 14 pikseli. Miłą cechą tego konwertera ze strony http://oleddisplay.squix.ch/ jest fakt, że definicje bitmap w tablicy – znaków są rozdzielone i opisane, co znacząco ułatwi nam polonizowanie.
Dodawanie znaków
Na końcu pierwszej tablicy FontEdWBitmap[] dodamy definicje bitmap polskich liter (na razie „zwykłych” liter). A na końcu drugiej tablicy FontEdWGlyphs[] dodamy opisy glifów tych polskich liter. Jeżeli zgodnie z deklaracją font obejmuje symbole o kodach 32…126, to uzupełnimy go, dla kodu 127 (0xF7) kopiując spację. Na kolejne pozycje, czyli kody/znaki 128…145 skopiujemy „zwyczajne” litery A, C, E, L, N, O, S, Z, Z, a, c, e, l, n, o, s, z, z, które chcemy polonizować. Trzeba skopiować zarówno definicje bitmap w pierwszej tablicy FontEdWBitmap[], jak i opisy w drugiej tablicy FontEdWGlyphs[].
Takie kopiowanie można wykonać bardzo szybko, ale nie uzyskujemy jeszcze prawidłowego pliku fontu. Otóż w „dolnej” tablicy FontEdWGlyphs[] mamy informacje o poszczególnych glifach. W pierwszym polu (bitmapOffset) zawsze mamy numer kolejny bajtu, gdzie zaczyna się definicja tego znaku w tablicy FontEdWBitmap[]. Na razie liczby w tych pierwszych polach dodanych, a właściwie skopiowanych liter wskazują na „zwykłe” litery w tablicy FontEdWBitmap[]. A docelowo ma być inaczej! Za chwilę zmodyfikujemy wygląd dodanych polskich liter w pliku FontEdWBitmap[]. Ale najpierw musimy spowodować, by opisy w tablicy FontEdWGlyphs[] wskazywały pierwsze bajty definicji tych dodanych liter. To ręczna i dość żmudna robota. Aby prawidłowo zmodyfikować numery bajtów w pierwszym polu (bitmapOffset) tablicy FontEdWGlyphs[], musimy wiedzieć, ile bajtów opisuje dany znak. W tym celu w tablicy FontEdWBitmap[] musimy to policzyć i zapisać. Ten wstępny etap polonizowania zawarty jest w dostępnym w Elportalu pliku FontEdW_A.h.
Potem liczbę bajtów każdego znaku trzeba dodać jako komentarz w tablicy FontEdWGlyphs[]. Ten etap polonizowania zawarty jest w pliku FontEdW_B.h, dostępnym w Elportalu. Pokazany jest też w szkicu 2 . Kolorem niebieskim zaznaczone są dodane fragmenty, a kolor czerwony pokazuje, które pola (bitmapOffset) mają na razie błędną zawartość, bo wskazują bitmapy „starych, zwykłych liter”. I właśnie to trzeba poprawić w kolejnym etapie pracy.
Poprawianie tablicy glifów
Poprawianie szkicu 2 trzeba zacząć od miejsc zaznaczonych na zielono, dotyczących ostatniego znaku/symbolu pierwotnego fontu –klamry zamykającej }. W dolnej tablicy FontEdWGlyphs[] widzimy, że definicja tego znaku w tablicy FontEdWBitmap[] zaczyna się od bajtu o numerze kolejnym 424. Wyżej drugi zielony fragment pokazuje ten bajt, który ma wartość 0xC2. Ten bajt ma numer kolejny 424 (dziesiętnie) i widzimy, że znak ten definiuje sześć bajtów:
0xC2,0x10,0xC3,0x31,0x08,0xC0
Jeżeli sześć, to opis następnego znaku w tablicy FontEdWBitmap[] będzie się rozpoczynał w bajcie o numerze kolejnym 430 (424+6). Następnym znakiem o kodzie 127 jest spacja (w zasadzie powinna to być spacja niełamiąca NBSP, ale tym się absolutnie nie przejmujemy). W pole (bitmapOffset) tej spacji zamiast zera wpisujemy 430. Spacja jest znakiem „pustym” i nie musi mieć opisującej ją bitmapy – wtedy jej opis zajmuje 0 bajtów. A to znaczy, że w polu (bitmapOffset) następnego znaku też wpiszemy 430 (430+0). Ten następny znak ma być wyświetlany przez kod 128. Na razie mamy skopiowaną literę A i wskazanie, że jej opis zaczyna się od 145 bajtu tablicy FontEdWBitmap[].
Docelowo będzie to literka Ą, czyli A „z ogonkiem” i jej symbol będzie zdefiniowany w 6 kolejnych bajtach, zaczynających się od bajtu 430.
A to oznacza, że następny znak/symbol będzie opisany w tablicy FontEdWBitmap[] w kilku bajtach, zaczynających się od bajtu 436 (430+6). Docelowo będzie to litera Ć, której opis też zajmie 6 bajtów.
Opis kolejnej litery Ę zacznie się więc w tablicy FontEdWBitmap[] w bajcie numer 442 (436+6) i zajmie nie 6, tylko 4 bajty. Dlatego kolejny opis literki Ł zacznie się w bajcie 446 (442+4). I tak dalej…
W ten sposób dodane kody o numerach 128…145 (rozszerzone kody ASCII) spowodują wyświetlenie „miniobrazków”, zdefiniowanych w tablicy FontEdWBitmap[] w bajtach zaczynających się od 430 do 512 (508+4).
Trzeba jeszcze tylko zmienić w pliku informację, jaki numer ma ostatni (last), największy kod tego fontu. Wcześniej miał to być ostatni drukowalny kod ASCII o numerze 126, czyli szesnastkowo 07E, a teraz jest to mała literka ź, którą w naszym foncie ma wyświetlać kod numer 145, czyli szesnastkowo 0x91. Dlatego na samym dole pliku trzeba zmienić wartość pola last, z 0x7E na 0x91 w linii:
(GFXglyph *)FontEdWGlyphs,0x20, 0x91, 14};
Stan prac po tej operacji zawarty jest w dostępnym w Elportalu pliku FontEdW_C.h.
Pierwsze testy
Jak na razie zmieniliśmy tylko treść tablicy FontEdWGlyphs[], natomiast tablicy FontEdWBitmap[] nie ruszaliśmy, więc na nowych, dodanych miejscach nadal zawiera ona oryginalne definicje „zwykłych” liter. Niemniej w pracowicie przygotowanym pliku FontEdW_C.h mamy kompletną definicję fontu i możemy sprawdzić, czy nasz font działa. W tym celu w bibliotece Adafruit GFX w katalogu /Fonts należałoby skopiować plik FontEdW_C.h i zapisać w pliku FontEdW.h – rysunek 2.
Rysunek 2
To pozwoli wykorzystać go w szkicu A2601.ino, który jest dostępny w Elportalu, gdzie dyrektywa kompilatora dołącza nasz font, a potem już po inicjalizacji instrukcja przełącza z fontu podstawowego 5×7 na nasz świeżo zrobiony FontEdW.
Wszystkie znaki – glify naszego fontu nie zmieściłyby się na ekraniku OLED 128×64, dlatego w szkicu A2601.ino wyświetlimy na ekranie tylko te o kodach od 64 do 145. Fotografia 3 pokazuje efekt.
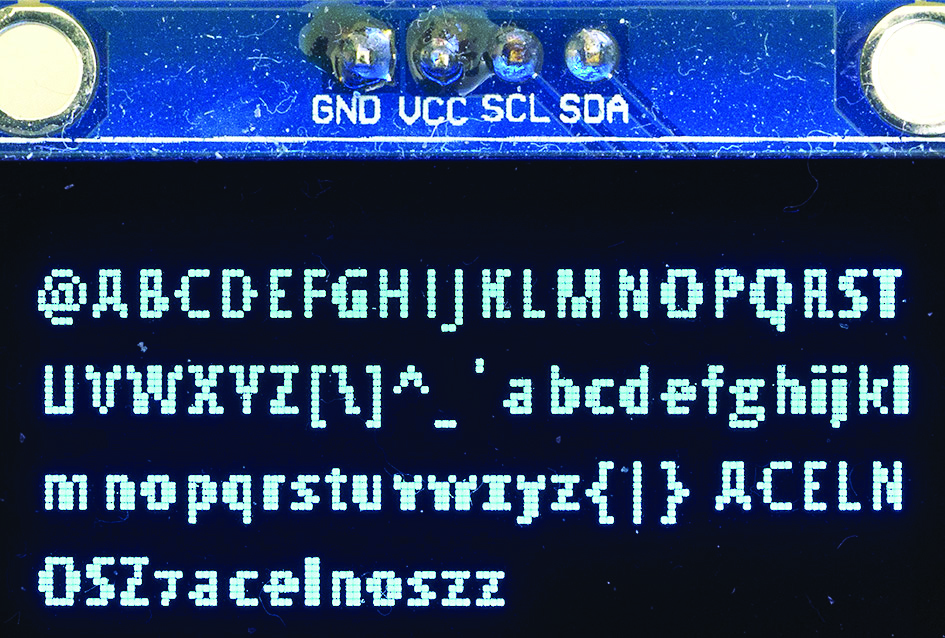
Fotografia 3
Szału nie ma! Ale cieszymy się, że nasz font działa! Dodane przez nas 18 znaków grzecznie wyświetliło się po klasycznych kodach ASCII.
Zaskoczeni jesteśmy wielkością symboli: zgodnie z rysunkiem 1 przy generowaniu fontu ustawiliśmy wielkość równą 10. Mogliśmy się spodziewać, że będzie to 10 pikseli. Niestety jest to 10 tak zwanych punktów typograficznych (1pt = 1/72 cala przy przyjęciu rozdzielczości ekranika OLED 0,96 cala). Wysokość znaków w naszym foncie to tylko 7 pikseli, czyli podobnie jak w foncie standardowym 5×7. Przez to literki nie wyglądają ładnie, i trudno byłoby je polonizować, ale jeśli chcesz – spróbuj.
Ja na stronie http://oleddisplay.squix.ch/ jeszcze raz przekonwertowałem font Open Sans Condensed, tym razem o wielkości 20 punktów, a wynik zapisałem w pliku FontEdW20.h. Skopiowanie 18 liter, które przerobimy na polskie, i zaktualizowanie tablic bez zmiany bitmap zajęło mi nieco ponad 20 minut. Po skompilowaniu szkicu A2602.ino z plikiem FontEdW20.h ekran wyglądał jak na fotografii 4.

Fotografia 4
Edytowanie bitmap znaków
Mamy już wstępnie przygotowany, działający font i w kolejnym kroku trzeba zmienić wygląd dodanych glifów, żeby przypominały polskie litery. Wiemy, że w tabeli FontEdWBitmap[] zawarte są „małe obrazeczki”, które ustalają wygląd poszczególnych znaków. Wcześniej ustaliliśmy, że każdy „obrazeczek” podstawowego fontu 5×7 (glcdfont.c) definiowany jest za pomocą pięciu bajtów, co daje matrycę 5 kolumn po 8 pikseli. Kolumny skanowane są od strony lewej do prawej i każda kolumna od dołu do góry – najniższy piksel to najstarszy bit (MSB) bajtu.
Wiemy też, że biblioteka Adafruit GFX wyświetla „zwyczajne obrazki“ skanowane poziomo, przy czym jedna linia pozioma, niezależnie od liczby pikseli w linii, zapisywana jest w całkowitej liczbie bajtów.
I jedne, i drugie bitmapy potrafimy „ręcznie zdekodować” na kartce papieru w kratkę. Teraz jednak mamy do czynienia z ulepszonymi fontami GFX, gdzie dla oszczędności pamięci skanowanie jest inne od tych dwóch opisanych. Niemniej „ręczne dekodowanie” na kartce też jest możliwe. W przypadku osiemnastu liter o małych rozmiarach można byłoby podjąć się takiego zadania. Ale przy fontach o większych rozmiarach, jak nasz FontEdW20.h, „ręczne dekodowanie”, choć możliwe, byłoby bardzo czasochłonne, męczące, wymagające ogromnego skupienia, żeby nie popełnić błędów. A dla każdego pliku zawierającego font danego rodzaju, kroju i wielkości trzeba to robić oddzielnie.
Zapowiada się istny koszmar!
Niekoniecznie, ponieważ w Internecie można znaleźć narzędzia, które to ułatwią, na przykład: https://tchapi.github.io/Adafruit-GFX-Font-Customiser/
Zawartość pliku fontu (FontEdW20.h) trzeba skopiować do lewego okna Original font file (rysunek 5) i kliknąć Extract.
Rysunek 5
Wtedy skrypt przeanalizuje plik fontu i niżej na stronie wyświetli jego wszystkie symbole. Moje pierwsze dodane symbole pokazane są na rysunku 6.

Rysunek 6
Teraz klikając na poszczególne piksele, można łatwo zmieniać wygląd symboli. Można też za pomocą kolorowych przycisków w prosty sposób dodawać do poszczególnych symboli wiersze i kolumny, przesuwać linię bazową i skok kursora po wyświetleniu symbolu. Zachęcam do takiej zabawy!
W sumie taka przeróbka wyglądu bitmap jest łatwa i przyjemna – mnie zajęła około 20 minut.
Jedynym problemem dla mnie było to, że jeśli klikniemy znak plus na fioletowej podkładce Rows, to nowa linia zostaje dodana na dole znaku. Jest to wygodne w przypadku liter z dolnymi ogonkami, ale dla większości polskich liter, gdzie trzeba dodać co najmniej jedną nową linię od góry, jest to pewien kłopot. Nie potrafiłem dodać nowej linii na górze obrazka (nie wiem, czy jest to możliwe), więc dodawałem na dole, modyfikowałem stan pikseli i zmieniałem linię bazową (Base –) – kolor zielony.
Gdy po takiej zabawie polskie litery są gotowe, trzeba na górze strony kliknąć przycisk Process and create file i z prawego okna skopiować zmodyfikowany font do pliku .h (u mnie do nowej wersji FontEdW20.h).
Po podstawieniu w bibliotece tak przerobionego pliku FontEdW20.h i po skompilowaniu szkicu A2602.ino ekran wyglądał jak na fotografii 7. SUKCES! Mamy w zasięgu reki wszystkie polskie litery!

Fotografia 7
Nie jest to arcydzieło, literki niewątpliwie mogłyby być ładniejsze. Jeżeli będziesz dokonywał podobnej przeróbki, zapewne zrobisz to lepiej i ładniej niż ja, na przykład dodając nie po jednej, tylko po dwie lub trzy nowe linie do każdej polskiej literki.
Cieszymy się z dotychczasowych sukcesów, jednak próba wyświetlenia napisu ZAŻÓŁĆ GĘŚLĄ JAŹŃ ze szkicu A2603.ino dała fatalny skutek, pokazany na fotografii 8.

Fotografia 8
Spróbuj samodzielnie znaleźć drobny w sumie błąd, a raczej dwa „sąsiednie“ błędy i poprawić plik FontEdW20.h. W następnym odcinku zrobimy to wspólnie, bo musimy się jeszcze sporo nauczyć o fontach.
Piotr Górecki


