Wokół języka C. Historia programowania
Wielu elektroników chciałoby programować w języku C, jednak przeraża ich dziwny sposób zapisu. Straszą nawet takie w sumie proste pojęcia jak ciało funkcji, typy danych, operatory, warunki czy pętle. Kłopoty sprawiają zmienne lokalne i globalne, które na dodatek mogą być volatile. Mrożą krew w żyłach wskaźniki, rzutowanie, przeciążanie funkcji, a podczas dalszej nauki także klasy, instancje, dziedziczenie.Do tego dochodzą takie pojęcia „mikroprocesorowe”, zarówno te „ogólne”, jak rejestry specjalnego przeznaczenia, rejestr stanu, flagi, maskowanie, wskaźnik stosu, jak też mnóstwo innych, charakterystycznych dla mikrokontrolerów jednoukładowych.
Barierą okazuje się nie tyle stopień trudności, co uprzedzenia i właśnie strach. A strach, jak wiadomo, ma wielkie oczy. Wielu osobom programowanie procesorów wydaje się zadaniem ponad siły, i to nie tylko ze względu na trudność nauczenia się podstaw C, ale także na fakt, że jednocześnie trzeba „ogarnąć” szereg innych zagadnień, związanych budową i działaniem mikroprocesora. O skali problemu świadczą nadesłane ostatnio do redakcji listy, z których część przedstawiona jest w rubryce Poczta. Właśnie te listy spowodowały, że zmodyfikowaliśmy wcześniejsze plany i rozszerzamy zakres kursu C. Dużą barierą okazał się zakres i objętość materiału, dotyczącego dwóch dziedzin:
– samego języka C i programowania,
– budowy i działania mikroprocesora.
To prawda, że zakres materiału z dziedziny programowania w C oraz działania mikroprocesorów jest ogromny. Na początek wystarczy jednak drobny ułamek dostępnej wiedzy. Największą trudnością okazuje się odróżnienie i poznanie tylko tego, co konieczne i najważniejsze. Dobrze jest na początku zrozumieć najważniejsze zagadnienia, czyli niejako poznać główny szkielet. A dopiero potem zagłębiać szczegóły.
Omawiając szkielet, czyli ogólny zarys zagadnienia, warto dokonywać uproszczeń. Lepiej jest zrozumieć istotę sprawy w pewnym uproszczeniu, nawet bez uwzględnienia pewnych istotnych kwestii, niż uwikłać się w niezliczone drobne szczegóły, które nie pozwolą poznać sedna sprawy ani przejść do praktyki.
W sumie programowanie mikroprocesorów w C okaże się lekkie, łatwe i przyjemne, jeżeli tylko podejdzie się do niego z odpowiedniej strony. Warto wiedzieć, że…
Po pierwsze, język C wcale nie jest taki straszny, jak wydaje się większości początkujących. Wprost przeciwnie, jest elegancki, zwięzły, logiczny i ze swej natury pozwala uniknąć wielu błędów.
Po drugie, wcale nie trzeba wszystkiego wiedzieć. Każdy może nauczyć się programować w C, a nie musi być ekspertem.
Po trzecie, jak najszerzej należy wykorzystywać gotowe „kawałki programów” w ogromnej obfitości dostępne w Internecie. Nie warto wyważać otwartych drzwi.
Ponieważ zagadnienie ma szereg rozmaitych aspektów, spróbujemy spojrzeć na nie z kilku stron, by wyrobić sobie ogólny obraz. Dlatego oprócz zapowiadanego od dawna kursu C, będziemy sukcesywnie przedstawiać dodatkowe materiały wprowadzające dla „bojących się języka C”, żeby stopniowo wprowadzić ich w obce dotychczas dziedziny.
Celem pierwszego artykułu tej serii (PR001) jest usunięcie, a przynajmniej zmniejszenie lęku przed mikroprocesorami i ich programowaniem w języku C. Natomiast poniższy materiał jest bardziej poważnym rozwinięciem niektórych informacji, podanych w tamtym wstępnym artykule.
Nas interesuje teraz tylko programowanie mikrokontrolerów jednoukładowych AVR w języku C, a wobec tego informacje o historii oraz innych językach programowania wydają się niepotrzebne.
W zasadzie tak – niezbędne nie są.
Okazuje się jednak, że z kilku względów warto nieco bliżej przyjrzeć się rozwojowi języków programowania, ponieważ rozszerzenie horyzontów jest pomocne i wartościowe. Między innymi po to, żeby zobaczyć w tym nawale informacji porządek i sens oraz by docenić zalety języka C.
Rozważania zacznijmy od pierwszych elektronicznych komputerów cyfrowych (równolegle i nieco wcześniej istniały też komputery analogowe, ale to historia z innej bajki), budowanych od lat 40. XX wieku, najpierw na przekaźnikach i lampach (ABC, ENIAC, Colossus), potem tranzystorach, a następnie na mniej i bardziej skomplikowanych układach scalonych. W tamtych dawnych czasach, w połowie XX wieku komputery były ogromną rzadkością.
Komputer był wtedy czymś tak wyjątkowym i kosztownym, że tylko nieliczni specjaliści rozumieli jego budowę i potrafili napisać program. Pierwsze komputery, jak na dzisiejsze standardy, miały bardzo skromne możliwości, miały niewielką szybkość i mało pamięci. Nic dziwnego, że pisane dla nich programy musiały ściśle odzwierciedlać specyfikę oraz cechy szczególne i ograniczenia sprzętu.
Dość szybko, już w latach 50. komputery zaczęto produkować seryjnie, ale wyłącznie jako potężne maszyny do celów profesjonalnych. W praktyce były one dostępne tylko dla bardzo wąskiego grona naukowców w uniwersytetach i wojskowych ośrodkach badawczych. Sprzęt był niesamowicie drogi, a użytkownicy: nieliczni i wysoko kwalifikowani, więc na samym początku nie przykładano dużej wagi do kwestii pisania programów. Niemniej od początku istnienia komputerów podejmowano różne próby, by uprościć sposób ich programowania.
Na samym początku do programowania wykorzystywano zapożyczone z maszyn przędzalniczych karty z wycięciami, tzw. karty Holleritha (fotografia 1), gdzie dane były reprezentowane przez wycięcia w odpowiednich miejscach tekturki.

Fotografia 1
Potem wykorzystywano też papierową taśmę perforowaną (fotografia 2), a następnie taśmę i dyski magnetyczne, a dziś pamięci półprzewodnikowe.

Fotografia 2
Komputerowi, czyli maszynie, potrzebny był i jest program w postaci (długiej) serii elementarnych rozkazów i danych. Dziś mówimy, że jest to kod maszynowy, gdzie i rozkazy i dane przedstawione są w postaci dwójkowej, czyli w postaci ciągów zer i jedynek. Trzeba podkreślić, że rozkazy kodu maszynowego są proste, elementarne. Żeby komputer/procesor zrealizował choćby nieco bardziej skomplikowane zadanie, trzeba je „rozpisać” na mnóstwo elementarnych rozkazów kodu maszynowego. Dawniej te zera i jedynki były reprezentowane przez otwory w karcie lub taśmie. Dziś kod maszynowy procesora to też zera i jedynki wpisywane do pamięci, ale jeżeli zachodzi potrzeba ich zobrazowania, to dla wygody człowieka przedstawiane są przeważnie nie w kodzie dwójkowym, tylko w pokrewnym kodzie szesnastkowym (heksadecymalnymn), gdzie każde cztery bity kodu dwójkowego są przedstawione jako jedna cyfra kodu szesnastkowego (0…9, A, B, C, D, E, F). Rysunek 3 pokazuje fragment pliku .HEX, który zawiera kod maszynowy, wprowadzany do pamięci programu.
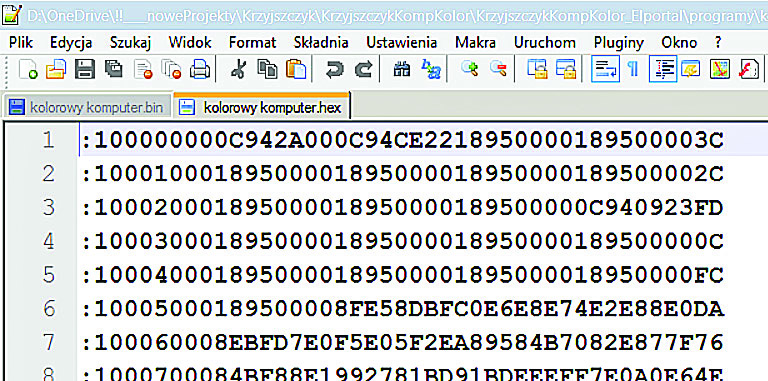
Rysunek 3
Stosowane w pierwszych komputerach programowanie w kodzie maszynowym, polegające w sumie na tworzeniu ciągów zer i jedynek było bardzo żmudne i wymagało dużej wiedzy i ogromnej staranności. Częściowym rozwiązaniem problemu i znacznym ułatwieniem było wprowadzenie asemblera (1950). Asembler to język programowania niskiego poziomu, w którym kod rozkazu dla danego komputera/procesora (kod maszynowy) zapisywany jest w bardziej przyjazny dla człowieka sposób, nie jako dwójkowa liczba kodu maszynowego, tylko zwykle jako trzyliterowy skrót, nawiązujący do treści rozkazu. Listing 1 (z Wikipedii) pokazuje prosty program, napisany w języku asemblera.
Listing 1:
TITLE EXECUTING. ASM EXECUTING PARTED ASSUME CS:EXECUTING ORG 100h START: MOV AH, 9 MOV AL, 40h MOV AH, 10d MOV CX, 11D INT 10h MOV AH, 4ch INT 21h EXECUTING ENDS END START
Można w uproszczeniu powiedzieć, że kod napisany w asemblerze jest bliższą człowiekowi wersją zerojedynkowego kodu maszynowego. Tak napisany program musi zostać przetłumaczony na kod maszynowy zrozumiały dla procesora. Program napisany w języku asemblera, języku specyficznym dla danego procesora (dla rodziny procesorów), w procesie zwanym asemblacją należało zamienić niejako w proporcji 1:1, na zera i jedynki kodu maszynowego, co ilustruje rysunek 4. Wprowadzenie asemblera było ułatwieniem, jednak nadal programista musiał dbać o wszystkie szczegóły dotyczące programu.
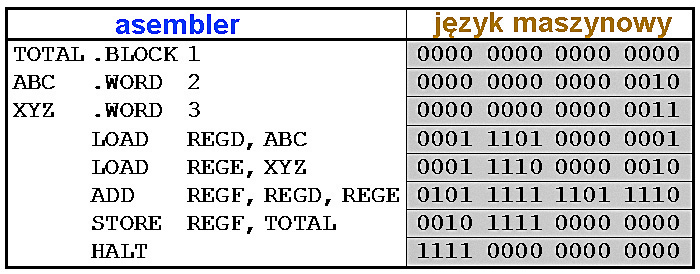
Rysunek 4
W drugiej połowie XX wieku słynne były duże komputery firmy IBM i właśnie w laboratoriach IBM już latach 1954-57 opracowano pierwszy popularny język wysokiego poziomu FORTRAN, który służył, i co ciekawe, do dziś służy uczonym, głównie do różnorodnych obliczeń matematycznych. Na listingu 2 przedstawiony jest przykładowy program w tym języku.
Listing 2:
C AREA OF A TRIANGLE - HERON’S FORMULA C INPUT - CARD READER UNIT 5, INTEGER INPUT, NO BLANK CARD FOR END OF DATA C OUTPUT - LINE PRINTER UNIT 6, REAL OUTPUT C INPUT ERROR DISPAYS ERROR MESSAGE ON OUTPUT 501 FORMAT(3I5) 601 FORMAT(„ A= „,I5,” B= „,I5,” C= „,I5,” AREA= „,F10.2,”SQUARE UNITS”) 602 FORMAT(„NORMAL END”) 603 FORMAT(„INPUT ERROR OR ZERO VALUE ERROR”) INTEGER A,B,C 10 READ(5,501,END=50,ERR=90) A,B,C IF(A=0 .OR. B=0 .OR. C=0) GO TO 90 S = (A + B + C) / 2.0 AREA = SQRT( S * (S - A) * (S - B) * (S - C) ) WRITE(6,601) A,B,C,AREA GO TO 10 50 WRITE(6,602) STOP 90 WRITE(6,603) STOP END
Najprościej biorąc, w języku wysokiego poziomu chodzi o to, żeby programista nie musiał pisać wszystkich pojedynczych drobnych rozkazów kodu maszynowego ani asemblera. Idea jest bardzo prosta: obliczenia matematyczne są standardowe, powtarzalne, więc pisanie programu może polegać na zwięzłym sformułowaniu potrzebnych operacji matematycznych. Tak napisany program będzie zwięzły, ale… zupełnie niezrozumiały dla procesora. Mało tego, potrzeby obliczeniowe są, można powiedzieć, standardowe, natomiast komputery/procesory różnych producentów mają inną budowę, specyfikę i wymagania. Dlatego niezbędny jest „pośrednik”, który taki zwięzły zapis rozwinie w sposób zrozumiały dla danego procesora, używając drobnych, elementarnych rozkazów kodu maszynowego, a także go uzupełni, ponieważ oprócz rodzaju operacji matematycznych trzeba też dokładnie określić, skąd mają być branie dane do obliczeń i gdzie mają być umieszczane wyniki. I właśnie tłumaczeniem takiego zwięzłego kodu programu na (długi) ciąg zerojedynkowych rozkazów kodu maszynowego danego procesora zajmuje się odpowiedni kompilator.
Dziś kompilator jest po prostu programem komputerowym, natomiast (niezrealizowane) propozycje elektromechanicznego kompilatora i języka programowania wysokiego poziomu (Plankalkül) były opracowane w Niemczech już w czasie wojny, w latach 1943-45 przez Konrada Zuse dla jego elektromechanicznego komputera Z3.
Używany do dziś język FORTRAN i kompilatory tego języka na kod maszynowy kolejnych komputerów, nie były uniwersalne. Otóż FORTRAN był „nakierowany” na obliczenia matematyczne, a z czasem okazało się też, jak ważne jest zbieranie i przetwarzanie różnorodnych danych, w tym przeszukiwanie baz danych, operacje statystyczne czy specyfika przeprowadzania operacji bankowych. Dlatego od początku „ery komputerów” powstawały różne języki „nakierowane” na poszczególne dziedziny zastosowań. Szybko zaproponowano mnóstwo języków programowania, spośród których niewiele zyskało popularność i znaczenie praktyczne. Z bardziej popularnych „wczesnych” języków programowania (z roku 1958) należałoby wymienić wykorzystujący tzw. polską notację Łukasiewicza LISP a także ALGOL, stworzony głównie do transakcji bankowych, oraz późniejsze COBOL (1959), SNOBOL (1962), oraz popularne do dziś BASIC (1964), Pascal (1970) oraz język C (1969-72). Ulepszeniem i rozszerzeniem języka C stał się obiektowy C++ (1983). Pojawiło się też mnóstwo innych, z których należałoby wymienić choćby następujące: SQL (1978), Matlab (1984), Perl (1987), Visual Basic (1991), Python (1991), Ruby (1993), Java (1995), Delphi – Object Pascal (1995), JavaScript (1995), PHP (1995) czy C# (2001). Na stronie http://cdn.oreillystatic.com/news/graphics/prog_lang_poster.pdf, w skrócie http://goo.gl/ZgM02Q można znaleźć plakat, pokazujący graficznie rozwój i wzajemne zależności popularniejszych języków programowania.
Poszczególne języki programowania zostały pomyślane i zrealizowane (zaimplementowane w kompilatorach) pod różne potrzeby. Trzeba też podkreślić, że obecnie główny nurt rozwoju języków programowania dotyczy potężnych procesorów stosowanych w komputerach, a także tabletach, smartfonach i innym zaawansowanym sprzęcie. Natomiast mikroprocesory jednoukładowe, którymi my się interesujemy, są stosunkowo proste i mają swą specyfikę – znacząco różnią się od „dużych procesorów”, stosowanych w komputerach, tabletach czy smartfonach.
Języki programowania już dawno całkowicie oddzieliły się od sprzętu. Dzisiejszy informatyk – programista może nie wiedzieć praktycznie nic o fizycznej budowie procesora, który ostatecznie będzie wykonywał jego program. I często tak jest. Natomiast przy programowaniu mikrokontrolerów jednoukładowych koniecznie trzeba znać ich budowę.
Można stworzyć (i stworzono, co pokazuje strona https://goo.gl/SxcUu6) setki języków programowania. Bo język programowania to jedynie zbiór zasad określających, kiedy ciąg symboli tworzy program komputerowy oraz jakie obliczenia opisuje. Stosowny zbiór zasad można stworzyć na nieskończenie wiele sposobów, a potem zgodnie z nim pisać programy…
i co dalej?
No właśnie – program w języku wysokiego poziomu, zwany programem źródłowym, jest… całkowicie bezużyteczny, o ile nie zostanie prawidłowo skompilowany, czyli zamieniony na język maszynowy konkretnego typu procesora. Druga kluczowa kwestia brzmi: czy dostępny jest stosowny kompilator dla danego języka i danego procesora i jakie ten kompilator ma możliwości i ograniczenia. Ściślej biorąc w grę wchodzi suma trzech czynników:
– specyfiki mikroprocesora,
– reguł użytego języka programowania,
– dostępności i możliwości kompilatora.
Wybór języka programowania jest o tyle ważny, że reguły poszczególnych języków pozwalają gorzej lub lepiej panować nad sytuacją i unikać błędów. Jeżeli jednak chcemy programować mikroprocesory jednoukładowe, nie interesujemy się zdecydowaną większością obecnych języków programowania. Nawet jeśli istnieją kompilatory dla „małych mikroprocesorów” skądinąd bardzo interesującego Pascala, są bardzo mało popularne. Nie ma kompilatorów, które zamieniałyby zapis popularnych „najnowocześniejszych” języków programowania na kod maszynowy mikroprocesorów jednoukładowych. Nie ma i nie będzie, ponieważ większość wykorzystywanych dziś języków programowania wysokiego poziomu stworzono do zadań zupełnie innych, najczęściej znacznie bardziej zaawansowanych, niż mogłyby wykonać „nasze małe mikroprocesory”.
Do programowania mikroprocesorów jednoukładowych w grze pozostają praktycznie tylko następujące języki:
A – asembler
B – BASIC
C – język C.
Przyjrzyjmy się temu nieco bliżej.
Korzystanie z asemblera oznacza, że programista pisze kod, praktycznie będący kodem maszynowym procesora. Jak już wiesz, przekształcenie programu źródłowego, czyli programu w języku niskiego poziomu w kod maszynowy nie wymaga kompilatora, bo chodzi o bardzo prostą, bezpośrednią zamianę symboli asemblera na dwójkowe rozkazy kodu maszynowego). Programista „asemblerowy” musi jednak bardzo dobrze znać mikroprocesor, a podczas pisania programu pilnować wszystkich szczegółów. W praktyce korzystanie z asemblera okazuje się żmudne i trudne, ale za to można w ten sposób uzyskać optymalny, czyli najlepszy kod.
Rzecz w tym, że dany cel można osiągnąć na wiele gorszych i lepszych sposobów. Tworzone programy mogą być lepsze i gorsze. Optymalny program w swej ostatecznej postaci kodu maszynowego zajmie minimalną ilość miejsca w pamięci procesora i będzie wykonywany możliwie jak najszybciej. Program nieoptymalny do wykonania tego samego zadania będzie potrzebował i więcej pamięci, i więcej czasu. I właśnie asembler powala uzyskać optymalny kod, a programista ma pełną kontrolę nad wszystkimi szczegółami, w tym nad czasem wykonywania programu, co w mikrokontrolerach jednoukładowych często ma ogromne znaczenie. Obecnie asembler jest jednak mało popularny, bowiem trudno w tym języku niskiego poziomu pisać większe programy. Gdy bowiem program się rozrasta, zdecydowanie rośnie problem utrzymania porządku i „ogarnięcia” całości. Konieczne staje się wykorzystanie języka wysokiego poziomu (wersje B, C).
Owszem, w krytycznych miejscach programu, gdzie kluczowe znaczenie ma czas wykonywania programu i oszczędne wykorzystanie zasobów komputera/procesora, bywają stosowane tak zwane wstawki asemblerowe. Praktycznie każdy kompilator języka wysokiego poziomu pozwala dołączać takie wstawki. Ich obecność gwarantuje, że wytworzony z nich kod maszynowy będzie dokładnie taki, jak chciał programista. Ale obecnie wstawki asemblerowe to rzadkość.
Przechodzimy do wersji B: BASIC, a w praktyce znany Czytelnikom EdW BASCOM, jest bardzo popularny wśród hobbystów, ponieważ ma jedną ogromną zaletę: jest prosty do nauczenia się. Niestety, jest to chyba jedyna zaleta. Właściwości samego języka BASIC, a także kompilatora BASCOM są takie, że uzyskany kod maszynowy, wpisywany do mikroprocesora, jest daleki od optymalnego. W związku z rosnącymi pojemnościami pamięci mikroprocesorów ten problem wprawdzie traci znaczenie, jednak jest coś znacznie gorszego. Po pierwsze wykorzystując BASIC programista nie ma pełnej kontroli nad procesorem, bo kompilator pewne polecenia języka wysokiego poziomu zamienia na kod maszynowy według swoich własnych, nieoptymalnych zasad.
I drugie, jeszcze gorsze: zasady języka BASIC są wprawdzie intuicyjne, lecz mówiąc w skrócie – uczą złych przyzwyczajeń. Dlatego BASIC (BASCOM) jest dobry dla hobbystów, dla których najważniejsze jest, by program w ogóle działał, a nie zależy im na optymalizacji i profesjonalnym podejściu. Mówiąc krótko: zbyt głębokie „utknięcie” w BASIC-u zamyka drogę do tego, by być porządnym, profesjonalnym programistą.
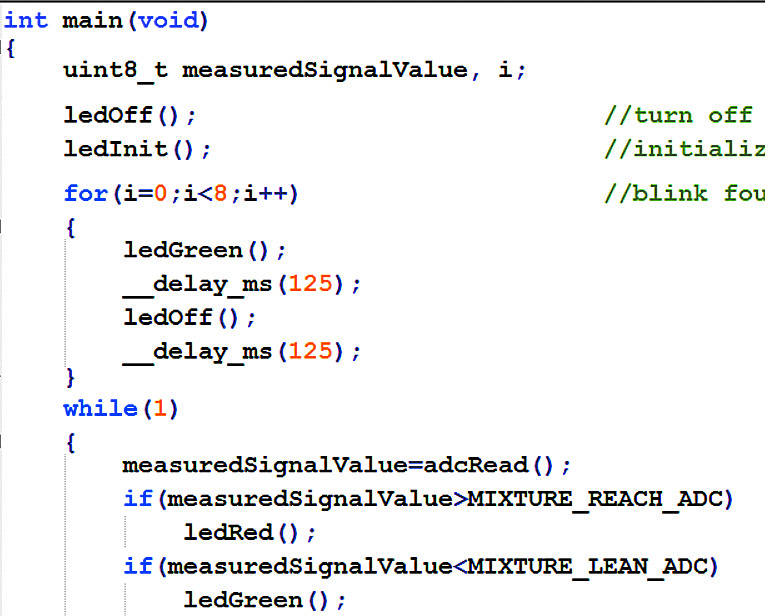
Rysunek 5
I tu dochodzimy trzeciej możliwości, jaką jest język C (przykładowy fragment programu na rysunku 5). Wielu początkującym program w tym języku wydaje się czarną magią. Okazuje się jednak, iż zasady tego języka są na tyle przemyślane (czego niestety początkujący nie dostrzegają), a kompilatory – dopracowane, że z tego języka możemy uzyskać kod bliski optymalnemu. Pisanie programów w C, zwłaszcza tych obszerniejszych, okazuje się nieporównanie szybsze i łatwiejsze, niż w asemblerze, a uzyskiwany efekt w postaci kodu maszynowego wpisywanego do procesora jest zbliżony. Co ważne, jeżeli elektronik opanuje programowanie mikroprocesorów w C, ma otwartą drogę do innych języków „komputerowych”, w tym PHP, Java czy modnego ostatnio C#.
Na razie uwierz na słowo, że na pozór dziwne wymagania (reguły składni) języka C wcale nie są kaprysami jego twórcy, tylko bardzo głęboko przemyślanymi zaletami i dobrodziejstwami.
Jeżeli więc ktoś chce pisać porządne programy dla mikroprocesorów i nie zamykać sobie drogi do programowania komputerów w innych językach, to tak naprawdę nie ma alternatywy: musi się nauczyć języka C.
Jest tylko jeden poważny problem…
Elektronikowi bardzo trudno nauczyć się języka C, jeżeli nie zna on żadnych innych języków programowania i jeśli nie miał wcześniej kontaktu z mikroprocesorami. Problem w dużej mierze dotyczy także osób, które programowanie zaczęły od BASCOM-a. W kolejnych odcinkach, w tym w nastęnym PR003, znajdziesz kolejne informacje, które pozwolą stopniowo zrozumieć oraz polubić język C.
Piotr Górecki