


Mikrokontroler jednoukładowy. Asembler i adresowanie cz. 2
W poprzednim artykule (UR033) omawialiśmy rozkazy asemblera oraz ich związek z zerami i jedynkami kodu maszynowego. Teraz omówimy tryby adresowania. Opis trybów adresowania i związane z tym rysunki straszą większość początkujących. Tymczasem zasady są proste. Zacznijmy od tego, że w ogóle adresowanie to podanie numeru komórki pamięci, by odczytać jej zawartość albo coś do niej zapisać. Jakiej pamięci?
Każdej dostępnej w procesorze: FLASH, RAM, EEPROM. Omówmy je po kolei.
Adresowanie pamięci programu FLASH
W przypadku pamięci FLASH zasadniczo mamy do czynienia tylko z odczytem. O pracy procesora decyduje adresujący pamięć FLASH licznik programu (PC – Program Counter), który podczas normalnej pracy jest automatycznie inkrementowany (po wykonaniu rozkazu, zawartość PC jest zwiększana o 1). Dzięki temu standardowo wykonywane są rozkazy z kolejnych komórek pamięci FLASH. Ale jak już wiesz, do licznika programu można wpisać jakąś liczbę i w ten sposób wymusić przejście do innej części programu. Coś takiego automatycznie dzieje się w przypadku obsługi przerwań – przerwanie powoduje skok do komórki pamięci programu, przypisanej temu przerwaniu. Gdy przerwanie zostanie obsłużone, rozkaz RETI powoduje powrót do miejsca w programie tuż przed przerwaniem (ewentualnie wykorzystywane jest też stos oraz rozkazy PUSH i POP). Ale skoki mogą także następować z innych powodów.
W niektórych procesorach może być zrealizowany „podwójny” rozkaz skoku bezwarunkowego JMP albo przejścia do podprogramu CALL. Część adresu skoku zawarta jest w rozkazie, reszta – w następnej komórce pamięci. Struktura „podwójnego” rozkazu (długiego) skoku bezwarunkowego JMP jest następująca:
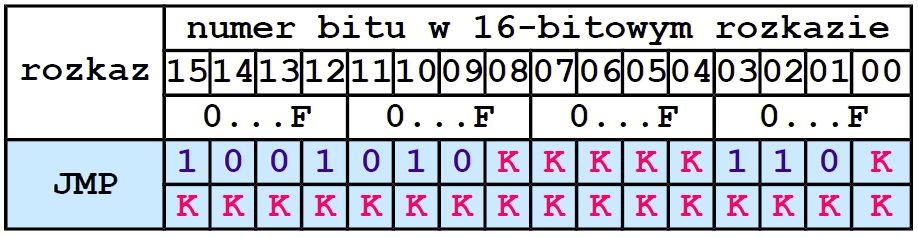
22-bitowa liczba K powala zaadresować 4194304 (4M) komórek pamięci programu. Taki bezpośredni sposób adresowania pamięci programu przedstawiony jest na rysunku 10.

Rysunek 10
Rozkazy JMP, CALL nie są dostępne w wielu procesorach. Ale we wszystkich można realizować inne rozkazy skoków. Zawsze dostępne są „pojedyncze” rozkazy skoków względnych (relative) RJMP, RCALL:
 gdzie 12-bitowa liczba dwójkowa S (ze znakiem – w formacie uzupełnienia do 2) pozwala na skok o –2048…+2047 komórek pamięci względem aktualnego stanu licznika PC. Taki sposób adresowania pamięci jest zilustrowany na rysunku 11.
gdzie 12-bitowa liczba dwójkowa S (ze znakiem – w formacie uzupełnienia do 2) pozwala na skok o –2048…+2047 komórek pamięci względem aktualnego stanu licznika PC. Taki sposób adresowania pamięci jest zilustrowany na rysunku 11.

Rysunek 11
Dostępne są rozkazy IJMP, ICALL, gdzie wykorzystuje się tzw. adresowanie pośrednie – w sumie bardzo proste: do licznika programu PC wpisywana jest zawartość tzw. rejestru Z, a rejestr Z to nic innego jak para „ostatnich” rejestrów roboczych R31, R30, w sumie 16 bitów, co pozwala zaadresować 64K słów programu (w „większych” procesorach przewidziane są „rozszerzone” rozkazy EIJPM, EICALL, wykorzystujące też dodatkowy rejestr EIND).
Omówione szczegóły dotyczą skoków, czyli sterowania przebiegiem programu. Programując w C, nie musisz się w to zbytnio zagłębiać. Powinieneś jednak wiedzieć o innej możliwości. Otóż pamięć RAM w procesorach AVR generalnie jest mała. Tymczasem w wielu urządzeniach wykorzystujemy wyświetlacze znakowe i graficzne. Wiele z wyświetlanej na nich treści to napisy lub inne znaki graficzne – w każdym razie są to niezmienne elementy (stałe). Innym przykładem są tablice przeliczeniowe (look-up tables). Standardowo te niezmienne elementy są „zaszyte” w programie w pamięci FLASH, ale po rozpoczęciu pracy programu tworzona jest ich kopia w pamięci RAM i dopiero stamtąd wysyłane są do wyświetlenia. Oznacza to marnotrawstwo skąpej pamięci RAM. Można temu zapobiec, wykorzystując dostępne w wielu procesorach trzy odmiany polecenia LPM (i „rozszerzone” ELPM z wykorzystaniem dodatkowego rejestru RAMPZ z przestrzeni I/O). Pozwalają one szybko i bezpośrednio odczytać zawartość komórek pamięci FLASH, gdzie nie są zawarte rozkazy zawierające „zaszyte stałe elementy”, tylko gdzie wspomniane stałe są zapisane „wprost”. I właśnie rozkazy LPM (ELPM) służą do odczytywania takich stałych danych zapisanych „wprost” z pamięci FLASH do jednego z rejestrów roboczych R0…R31. Problem jednak w tym, że komórki pamięci FLASH są 16-bitowe, a rejestr, do którego mają być odczytane, jest 8-bitowy. Jednorazowo można więc odczytać tylko jedną „połówkę” komórki FLASH. Do określenia adresu i „połówki” odczytywanej komórki pamięci FLASH w rozkazach LPM i LPM Rd,Z wykorzystywana jest zawartość rejestru Z (+ ewentualnie RAMPZ). Najmłodszy bit w rejestrze Z określa, czy ma być odczytana „wyższa połówka”, czy „niższa”. Ponieważ zwykle nie chodzi o odczytanie jednego bajtu, tylko co najmniej kilku (np. liter do „napisów stałych” albo tablic przeliczeniowych look-up), dostępny jest też „seryjny” rozkaz LPM Rd,Z+, (ELPM Rd,Z+)
 gdzie zawartość rejestru Z jest automatycznie zwiększana po każdym odczycie, jak pokazuje rysunek 12. Pięć bitów d określa numer rejestru, dokąd trafią odczytane dane. Oczywiście z uwagi na to, czym jest rejestr Z (R31+R30), mało sensowne są rozkazy LPM r30,Z+ oraz LPM r31,Z+.
gdzie zawartość rejestru Z jest automatycznie zwiększana po każdym odczycie, jak pokazuje rysunek 12. Pięć bitów d określa numer rejestru, dokąd trafią odczytane dane. Oczywiście z uwagi na to, czym jest rejestr Z (R31+R30), mało sensowne są rozkazy LPM r30,Z+ oraz LPM r31,Z+.
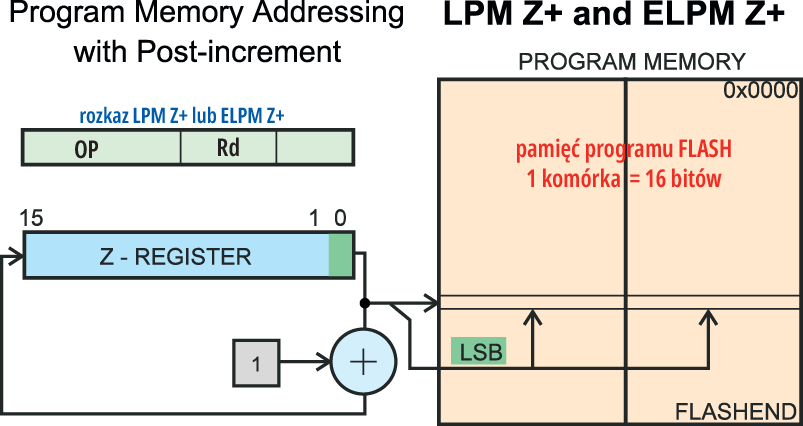
Rysunek 12
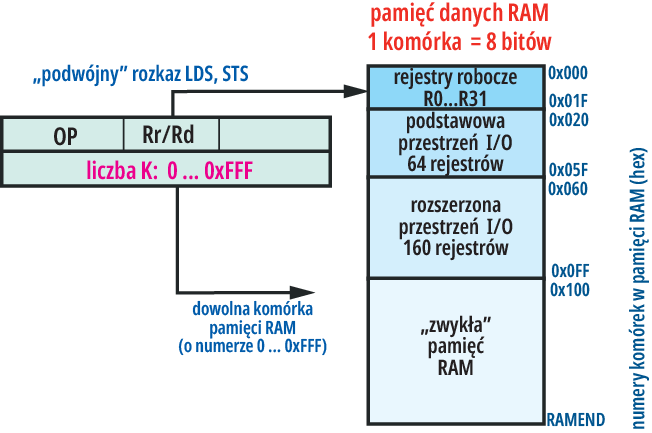
Adresowanie pamięci danych RAM
Więcej rodzajów adresowania dotyczy pamięci RAM. Tym bardziej że pamięć RAM dzielimy na: 32 rejestry robocze (R0…R31), 64 rejestry podstawowej przestrzeni I/O, dodatkowo w „większych” procesorach 160 rejestrów rozszerzonej przestrzeni I/O, a dalej „zwykłą” pamięć RAM – rysunek 13. Komórki RAM mają numerację ciągłą, ale 64 rejestry podstawowej przestrzeni I/O mają oddzielną numerację – numer rejestru jest mniejszy o 32 (0x20) od numeru komórki RAM.
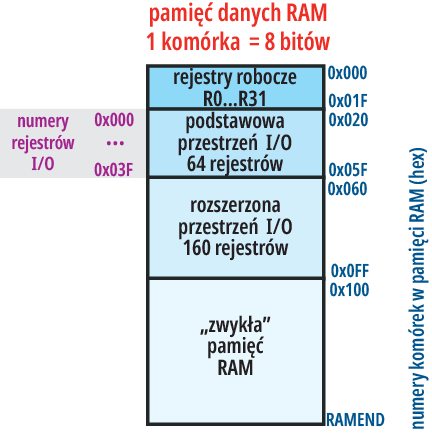
Rysunek 13
Podczas pracy procesora najczęściej wykorzystujemy rejestry robocze R0…R31, ponieważ są one ściśle związane z „kalkulatorem” CPU. Dlatego w operacjach przesyłania danych jedną ze stron jest właśnie któryś z 32 rejestrów roboczych. Aby go zaadresować, trzeba podać jego numer: wystarczy do tego 5 bitów (25 = 32). Numer wykorzystywanego rejestru roboczego zawarty jest w treści rozkazu.
Najprostszym sposobem adresowania jest więc umieszczenie w rozkazie adresu rejestru albo adresów dwóch rejestrów, jak na przykład w MOV Rd, Rr:
![]() – omawialiśmy to dość dokładnie w poprzednim odcinku. Ale tak adresujemy tylko rejestry robocze w pierwszych 32 komórkach RAM, wykorzystując ich pięciobitowe adresy-numery.
– omawialiśmy to dość dokładnie w poprzednim odcinku. Ale tak adresujemy tylko rejestry robocze w pierwszych 32 komórkach RAM, wykorzystując ich pięciobitowe adresy-numery.
Natomiast rozkazy IN, OUT:
![]()
wymieniają dane między rejestrem roboczym Rd (d) a jednym z 64 podstawowych rejestrów I/O o sześciobitowym numerze (a). Zauważ, że w kodzie rozkazów IN, OUT zawarty jest numer kolejny rejestru I/O, a nie jego adres RAM, który jest o 32 (0x20) większy – stąd też podwójna numeracja tych podstawowych rejestrów I/O w kartach katalogowych. Ilustruje to rysunek 14.
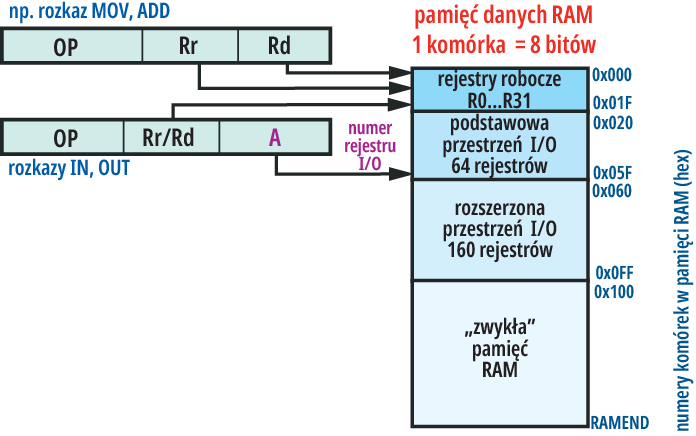
Rysunek 14
Dostępne są też pokrewne „podwójne” rozkazy LDS i STS, wykorzystujące adresowanie bezpośrednie. Pozwalają one odpowiednio wczytać do rejestru roboczego Rd (d) zawartość komórki dowolnej pamięci RAM o 16-bitowym adresie-numerze (K) oraz zawartość rejestru wpisać do tak zaadresowanej komórki pamięci:

Ilustruje to rysunek 15.
Rysunek 15
Ogólnie biorąc, przy adresowaniu bezpośrednim, numery-adresy komórek pamięci RAM podane są w treści rozkazu. I to jest w sumie proste. Początkującym sprawia kłopot zrozumienie, co to jest…
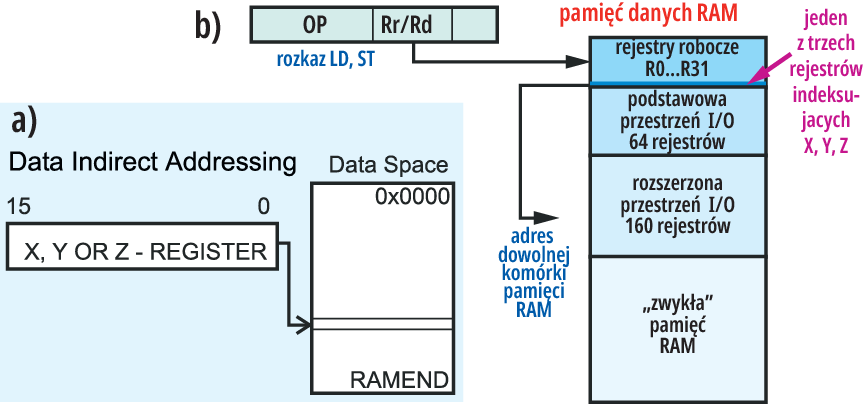
Adresowanie pośrednie (indirect adressing), choć jego idea też wcale nie jest trudna. Znów jedną ze „stron” wymiany danych jest któryś rejestr roboczy R0…R31 (jego pięciobitowy adres jest podany w treści rozkazu, czyli w pamięci FLASH). „Drugą stroną” operacji wymiany danych jest dowolna komórka pamięci RAM o numerze-adresie, który NIE jest podany w treści rozkazu, tylko zawarty jest w jednym z 16-bitowych rejestrów X, Y, Z. Rejestry wskaźnikowe X, Y, Z to w rzeczywistości pary 8-bitowych rejestrów roboczych, odpowiednio R26-R27; R28-R29; R30-R31. Czyli przy adresowaniu pośrednim adres potrzebnej komórki RAM podany jest w innej, określonej części pamięci RAM. W katalogach przedstawione to jest jak na rysunku 16a.
Rysunek 16
To, że adres potrzebnej komórki RAM jest zawarty w najwyższych rejestrach roboczych X, Y lub Z, pokazuje rysunek 16b, przedstawiający nieco dokładniej działanie „podstawowych” rozkazów odczytu LD Rs,X, LD Rs,Y, LD Rs,Z oraz zapisu dowolnej komórki pamięci ST Rr,X, ST Rr,Y, ST Rr,Z.
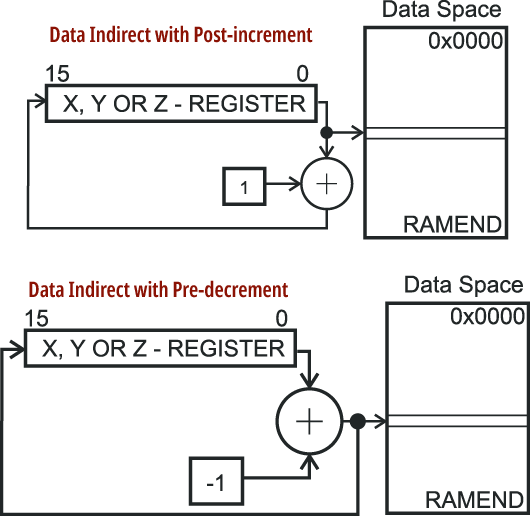
Jednak sposób prezentacji z rysunku 16b utrudnia pokazanie zasad działania odmian rozkazów LD, ST, na przykład LD Rs,-X, LD Rs,X+ (czy też LDD i STD). Ich działanie jest w sumie proste, tylko trudniej to zobrazować graficznie. Otóż w przypadku rozkazów LD Rs,X+, ST Rr,X+ i pokrewnych „z plusem” (Y+, Z+), po wykonaniu rozkazu przesłania danych LD (ST) następuje automatyczne zwiększenie o 1 (inkrementacja) zawartości rejestru indeksującego (X, Y lub Z). Wskutek tego zwiększenia ponowne wykonanie identycznego rozkazu będzie dotyczyć następnej komórki RAM, itd. Te rozkazy znakomicie ułatwiają odczyt czy zapis szeregu komórek RAM, np. przy obsłudze stosu, tablic lub napisów.
Bardzo podobne jest działanie rozkazów
LD Rs,-X,
ST Rr,-X
i pokrewnych „z minusem” (-Y, -Z), gdzie znak minus i jego pozycja „przed” pokazują, że zawartość rejestru indeksującego jest automatycznie zmniejszana o 1 (dekrementowana) i to PRZED wykonaniem rozkazu przesłania LD lub ST. Czyli że wybierana jest komórka RAM o adresie o jeden mniejszym, niż wynosiła zawartość rejestru indeksującego X, Y lub Z w chwili wywołania rozkazu LD/ST „z minusem”. W katalogach jest to przedstawiane jak na rysunku 17.
Nie musisz zagłębiać się w szczegóły, ale warto, przynajmniej z grubsza rozumieć, co znaczą na pozór dziwne opisy działania poszczególnych rozkazów. Spróbujmy je zrozumieć.
Rysunek 17
Opis działania
Jak więc rozumieć zaznaczony czerwono opis działania rozkazu LD Rd,-X?
![]() Początkującym tego rodzaju zapisy rzeczywiście wydają się dziwne, ale wcale nie znaczy to, że w informatyce wykorzystujemy jakąś zupełnie inną matematykę. Matematyka (logika) jest tylko jedna. Po prostu przyjęło się, że pewne operacje i działania zapisujemy inaczej, niż to jest od wieków przyjęte w innych dziedzinach. Czyli do opisu tych samych działań stosujemy różne notacje – sposoby zapisu.
Początkującym tego rodzaju zapisy rzeczywiście wydają się dziwne, ale wcale nie znaczy to, że w informatyce wykorzystujemy jakąś zupełnie inną matematykę. Matematyka (logika) jest tylko jedna. Po prostu przyjęło się, że pewne operacje i działania zapisujemy inaczej, niż to jest od wieków przyjęte w innych dziedzinach. Czyli do opisu tych samych działań stosujemy różne notacje – sposoby zapisu.
Przyzwyczailiśmy się, że działania arytmetyczne (i logiczne) zapisujemy tak: 2 + 3 = 5, czyli najpierw podajemy składniki, a na końcu wynik. Najogólniej biorąc, odwrotnie jest w informatyce: najpierw zapisujemy wynik, a potem „składniki”. Dotyczy to nie tylko działań arytmetycznych, ale też bardziej ogólnych.
Można byłoby dyskutować, jaka notacja, czyli sposób zapisu, jest bardziej logiczna czy intuicyjna. Można byłoby przywołać postać Jana Łukasiewicza, polskiego logika i filozofa, twórcy tak zwanej notacji polskiej. Mógłbym też opowiedzieć, jak pod koniec lat 70. stałem się szczęśliwym posiadaczem znakomitego na owe czasy kalkulatora Omron, którego oprócz mnie i jednego kolegi, nikt w naszym technikum obsługiwać nie umiał – właśnie z uwagi na wykorzystanie w nim RPN (odwrotnej notacji polskiej).
Zamiast zagłębiać się w takie skądinąd interesujące szczegóły powiedzmy, że w informatyce stosujemy specyficzny, w pewnym sensie „odwrotny” sposób zapisu. Dotyczy to zarówno języka C, jak i omawianego teraz asemblera i kodu maszynowego.
Nie ma rady – trzeba się przyzwyczaić!
I tak działanie rozkazu przekopiowania (przesunięcia) danych z rejestru źródłowego Rr do rejestru przeznaczenia Rs NIE jest opisane w sposób znany z klasycznej matematyki Rr → Rd, tylko „odwrotnie”: Rd ← Rr. W katalogu rozkaz ten jest opisany następująco:
![]() Polecenie ADD, które dodaje zawartość dwóch rejestrów, NIE jest opisane:
Polecenie ADD, które dodaje zawartość dwóch rejestrów, NIE jest opisane:
Rr + Rd → Rd, tylko „odwrotnie”:
Rd ← Rd + Rr.
Analogicznie „odwrotnie” opisane są także inne rozkazy. Na rysunku 18 masz trzy różne opisy kilku rozkazów – zwróć uwagę na wyróżnione różowym kolorem „odwrotne” opisy działania. Opisy te mówią, że działania dotyczą zawartości rejestrów.

Rysunek 18

Rysunek 19
A teraz zwróć uwagę na rysunek 19, gdzie przedstawione są opisy rozkazów wczytywania danych do rejestru (Rd). W rozkazie LDI Rd, K do rejestru Rd wpisywana jest (ośmiobitowa) stała K, zawarta w treści rozkazu, co opisane jest Rd ← K. W rozkazach LD wykorzystuje się adresowanie pośrednie zawartością rejestru wskaźnikowego X (pary rejestrów roboczych R27, R26). A więc do rejestru przeznaczenia Rd NIE jest wpisywana zawartość (16-bitowego) rejestru X, tylko zawartość komórki RAM o adresie-numerze, zawartym w rejestrze wskaźnikowym X. Dlatego w opisie nie piszemy Rd ← X, tylko Rd ← (X). Nawias wskazuje tu, że chodzi o adresowanie pośrednie, nie o zawartość rejestru X, tylko zawartość komórki pamięci RAM, której adres-numer zawarty jest w rejestrze X.
Opis rozkazu LD Rd, X+ jest następujący:
Rd ← (X), X ← X + 1
najpierw do rejestru Rd wpisywana jest zawartość komórki RAM, adresowana przez rejestr X, a potem liczba-adres w rejestrze X jest zwiększana o 1.
Czy teraz jest dla Ciebie jasne, że w przypadku rozkazu LD Rd,-X opis
X ← X – 1, Rd ← (X)wskazuje, iż najpierw zmniejszana jest o 1 zawartość rejestru X, a dopiero potem do rejestru Rd wpisywana jest zawartość komórki RAM, adresowana takim „zmniejszonym” adresem? A teraz kolejny istotny szczegół.
Jeszcze raz flagi
Na rysunku 18 masz kolumnę, w której podane jest, które flagi może zmodyfikować wykonanie danego rozkazu. Chodzi tu o flagi zawarte w rejestrze stanu (SREG). Są one wyróżnione niebieskim kolorem na rysunku 20.

Rysunek 20
Przypomnijmy, że te flagi są ustawiane automatycznie w wyniku wykonania niektórych rozkazów, głównie arytmetyczno-logicznych, ale także niektórych innych. I tak flagi H, S, V, N, Z, C są ustawiane (wpisywana wartość 1):
N – gdy wynik operacji jest ujemny
Z – gdy wynik operacji jest zerem
C – (Carry) gdy nastąpiło przeniesienie
H (Half Carry) – gdy nastąpi tzw. przeniesienie połówkowe, wykorzystywane przy obliczeniach w kodzie BCD
V – (Two’s Complement Overflow Flag) flaga przeniesienia/przepełnienia przy operacjach na liczbach ze znakiem w formacie uzupełnienia do 2
S – flaga znaku; ustawiana, gdy flagi V, N nie są jednakowe (S = N V). Te automatycznie ustawiane flagi niosą pewne ważne informacje o wyniku przeprowadzonej operacji i mogą być użyte do sprawdzania warunków i podejmowania decyzji o przebiegu programu (o skokach i pominięciach (branch, skip)).
Jeśli chcesz, samodzielnie zbadaj te sprawy dokładniej. Ale nie jest to konieczne, bo przy programowaniu w języku C tymi szczegółami będzie się zajmował kompilator. My krótko omówimy jeszcze tylko…
Pamięć EEPROM
Jak wiesz, oprócz stałej pamięci programu FLASH i ulotnej pamięci danych RAM, mikrokontrolery jednoukładowe zawierają też pamięć nieulotną EEPROM. Służy ona do zapamiętywania bieżących ustawień, które nie powinny zostać utracone po wyłączeniu zasilania, ale które nie są „na sztywno” wpisane do pamięci FLASH. Jest to więc pomocnicza, nieulotna pamięć danych. Jej wadą jest ograniczona liczba cykli zapisu (rzędu 100000) oraz długi czas zapisu.
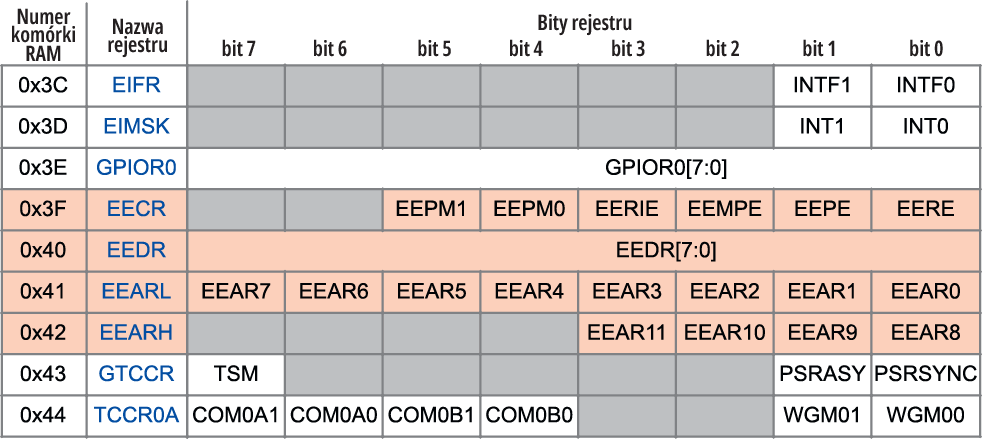
Adresowanie i obsługa pamięci EEPROM nie są skomplikowane, ale są specyficzne. Wracając do opisu procesora jako biura, w którym pracuje bardzo skrupulatny, ale słabo rozgarnięty i ograniczony umysłowo urzędnik, powiemy, że ten urzędnik… nawet nie wie o istnieniu pamięci EEPROM. Pamięć EEPROM jest niejako ukryta i można się do niej dostać przez rejestry w podstawowym obszarze I/O. Jest obsługiwana przez cztery ośmiobitowe rejestry o nazwach: EEARH, EEARL (EEPROM Adress Register), tworzące „podwójny” rejestr adresowy, określający, której komórki EEPROM dotyczy operacja, rejestr danych EEDR (EEPROM Data Register), gdzie umieszczane są dane do zapisania w EEPROM lub odczytane z zaadresowanej komórki oraz bity w rejestrze sterującym EECR (EEPROM Control Register). Ilustruje to rysunek 21, fragment karty katalogowej ATmega328PB. Adresy rejestrów 0x3F…0x42 to numery komórek RAM (numery kolejne tych rejestrów w podstawowej przestrzenni I/O są o 0x20 mniejsze, czyli wynoszą 0x1F…0x22).
Rysunek 21
Mówiąc najprościej, operacja odczytu komórki pamięci nieulotnej EEPROM polega na wpisaniu adresu-numeru tej komórki do pary rejestrów EEARH, EEARL i zmianie stanu „bitu odczytu” (EERE) w rejestrze EECR – wtedy w rejestrze danych EEDR pojawi się zawartość odczytana z tej komórki. W przypadku zapisu jest podobnie: najpierw trzeba wpisać adres i dane do zapisania, a potem zmienić stan odpowiednich bitów w rejestrze EECR. Jest to nieco bardziej skomplikowane, ponieważ zapis trwa nieporównanie dłużej niż odczyt i trzeba też uwzględnić dodatkowe czynniki.
Podsumowanie
Poświęciliśmy sporo czasu na omówienie rozkazów asemblera i odpowiadających im kodów maszynowych. Omówiliśmy różne tryby adresowania pamięci FLASH, RAM i EEPROM. Jeszcze raz podkreślam, że gdybyś miał programować w asemblerze, musiałbyś dużo dokładniej poznać te wszystkie zagadnienia. Natomiast pisząc programy w języku C, nie musisz rozumieć wszystkich tych szczegółów: Ty napiszesz tylko „w skrócie”, co chcesz zrobić, a o dobór odpowiednich wersji rozkazów maszynowych i o inne liczne drobiazgi zadba kompilator. Co prawda Ty nie będziesz wiedział, jak kompilator „rozpisze” Twoje „skrótowe” polecenie na elementarne rozkazy kodu maszynowego, ale ogólnie biorąc, kompilator języka C robi to zdecydowanie lepiej niż kompilator BASCOM-a (program wpisywany do procesora jest krótszy i „szybszy”). Tylko wtedy, gdyby czas wykonywania poszczególnych fragmentów programu był sprawą krytyczną, a Ty chciałbyś mieć stuprocentową kontrolę nad sytuacją, do programu pisanego w C możesz dodać tzw. wstawki asemblerowe. Ale to wyższa szkoła jazdy. Na razie nie musisz zawracać sobie tym głowy.
Niemniej zachęcam, żebyś wrócił jeszcze raz do pierwszej części artykułu o asemblerze (UR033), by uporządkować i powiązać podane informacje. Zachęcam, byś samodzielnie nieco bliżej zapoznał się z omówionymi zagadnieniami. Nie musisz zgłębiać i rozumieć wszystkich szczegółów, ale zajrzyj do kart katalogowych procesorów AVR oraz na strony internetowe, omawiające te zagadnienia. A my w nastepnym artykule (UR035) zaczniemy omawiać sprzętowe tajemnice Arduino.
Piotr Górecki


