Sieci komputerowe i Internet cz. 1
Współcześni absolwenci szkół o profilu elektronicznym często są bardziej informatykami niż elektronikami. Ale istnieje też ogromna grupa elektroników, którzy informatykami nie są i nie będą. Znaczna część z nich opanowała programowanie mikroprocesorów, a przynajmniej rozumie, jak działa mikroprocesor i na czym polega programowanie. Niemniej dla bardzo wielu elektroników czarną magią nadal są zagadnienia związane z sieciami komputerowymi. Tymczasem temat jest bardzo atrakcyjny, ponieważ współczesna elektronika pozwala także hobbystom realizować godne podziwu rozwiązania, wykorzystujące sieci komputerowe, Internet i możliwość komunikacji z układem elektronicznym z dowolnego miejsca na Ziemi.
Niestety, dla wielu elektroników barierą jest nieznajomość pewnych podstawowych pojęć informatycznych i brak ogólnej wiedzy o działaniu i konfiguracji sieci. Zagadnienia te wcale nie są tak trudne, jak się wydaje. Największym problemem jest to, że informatyka to bardzo obszerna dziedzina, a zagadnienia związane z sieciami też są ogromnie rozbudowane. Ale tak naprawdę elektronikowi wystarczą drobne okruchy wiedzy informatycznej, by z powodzeniem wykorzystywać sieci komputerowe i Internet. Na nieszczęście te drobne potrzebne okruchy są w podręcznikach i skryptach pomieszane z ogromem informacji potrzebnych tylko specjalistom. Problemem dla nieinformatyków jest: jak to ugryźć i od czego zacząć?
Z uwagi na to, że temat sieci komputerowych jest tak bardzo obszerny, spróbujemy podejść do tematu kilkakrotnie z różnych stron, by stopniowo przedstawić tylko to, co najważniejsze. Maksymalnie, na ile i gdzie to możliwe, uprościmy temat. Ale wszystkiego uprościć się nie da i w niektóre kluczowe zagadnienia trzeba się będzie wgryźć trochę głębiej.
Sieci komputerowe
Jeżeli mowa o sieciach komputerowych, większości osób od razu kojarzy się to z Internetem, czyli ogólnoświatową siecią komputerową. Niestety, w przypadku elektroników, chcących programować mikrokontrolery, takie podejście nie pomaga, ale poważnie przeszkadza i straszy. Nadmiar wzajemnie niepowiązanych okruchów informacji tworzy zamęt w głowie i mocne przeświadczenie: to dla mnie za trudne. Dlatego proponuję: zapomnij na chwilę o Internecie i o stronach www.
Zastanówmy się najpierw nad małymi, domowymi, lokalnymi sieciami do przesyłania danych cyfrowych – sieciami, które NIE MAJĄ DOSTĘPU DO INTERNETU. Na ich przykładzie można znacznie prościej uchwycić podstawowe zasady. A później dużo łatwiej będzie zrozumieć szczegóły związane z dostępem do Internetu, czyli do ogólnoświatowej sieci informatycznej.
Czy można inaczej?
Chcemy mówić o małych sieciach lokalnych, na przykład w obrębie mieszkania czy niewielkiego budynku, gdzie odległości między urządzeniami nie przekraczają, powiedzmy, dziesięciu metrów. Tymczasem sieci komputerowe kojarzą się z Internetem, globalną siecią, której rozmiary są rzędu tysięcy kilometrów. Czy wobec tego w małych domowych lokalnych sieciach też trzeba stosować „wielkie i skomplikowane rozwiązania internetowe”? A może wystarczyłyby znacznie prostsze sposoby?
Czy na przykład w małej sieci domowej nie można byłoby przekazywać danych choćby za pomocą łącza szeregowego (RS232) albo łącza I2C?
To zależy. W małych i powiedzmy, specjalizowanych sieciach – jak najbardziej można. Przykładowo system automatyki domowej może być zrealizowany na wiele sposobów i można wykorzystać różne łącza, w tym RS232 lub lepiej RS485 albo nawet I2C (TwoWire) oraz różne, w tym zupełnie niestandardowe łącza radiowe. Takie sieci specjalizowane do konkretnego zadania mogą być zrealizowane rozmaicie, według kaprysu swego twórcy. Każda z takich sieci może dobrze spełniać swoje zadanie, ale zależnie od umiejętności i doświadczenia tego twórcy będzie mieć gorsze lub lepsze właściwości, w tym niezawodność, trwałość, podatność na zakłócenia i błędy oraz elastyczność i możliwość rozbudowy czy modyfikacji. Ponadto różne takie sieci własnego pomysłu zapewne będą wzajemnie niekompatybilne pod różnymi względami.
Owszem, małą domową „specjalizowaną” sieć można zbudować w niemal dowolny sposób. Jeżeli jednak chcemy zbudować małą sieć o „standardowych” możliwościach, powinniśmy pamiętać o specyfice poszczególnych rozwiązań: o ich zaletach, wadach i ograniczeniach. I tak na przykład wspomniane łącze szeregowe RS232 z zasady łączy tylko dwa punkty/urządzenia i samo w sobie nie daje możliwości adresowania, więc tak naprawdę nie ułatwia budowy sieci. Aby zbudować sieć, należałoby dodać jakieś urządzenia pośredniczące i wprowadzić możliwość adresowania. W grę wchodzi RS485 ze swoimi zaletami i wadami.
W przypadku łącza I2C już w standardzie mamy adresowanie nawet ponad 100 urządzeń (różnego rodzaju układów scalonych), ale podstawowym problemem jest to, że przewidziana długość łącza to metr, najwyżej kilka metrów; są też inne istotne problemy. Można zwiększyć odległości za pomocą różnych rozwiązań, ale uzyskamy rozwiązanie niestandardowe, niekompatybilne z innymi.
Aby stworzyć wartościową, elastyczną, uniwersalną sieć transmisji danych cyfrowych, trzeba spełnić szereg warunków. Między innymi zapewnić niezawodny przekaz przez wprowadzenie skutecznej kontroli oraz korekcji błędów. Trzeba zrealizować skuteczny sposób adresowania, wyszukiwania adresów oraz zestawiania i kończenia połączenia. Bardzo pożądane byłoby, żeby przesyłanie informacji można było realizować z wykorzystaniem różnych łączy, zarówno przewodowych, jak i bezprzewodowych, np. radiowych i świetlnych (światłowody, podczerwień).
Już widać, że stare prymitywne łącze szeregowe RS232 czy nawet nowocześniejsze I2C, nawet jeśli byłyby użyte przy tworzeniu sieci, to stałyby się tylko maleńką cząstką całego systemu. Trzeba byłoby dodać do tego wiele funkcjonalności. I niewątpliwie system musi być w sumie bardzo skomplikowany, bo musi spełnić szereg warunków i wymagań.
Aby sieć komputerowa, nawet stosunkowo mała, lokalna, była naprawdę niezawodna i uniwersalna, musi wykorzystywać liczne bardzo zaawansowane rozwiązania i powiedzmy: zabezpieczenia. W grę wchodzą po pierwsze kwestie sprzętowe, dotyczące fizycznie realizowanego łącza przewodowego czy bezprzewodowego. Po drugie trzeba skutecznie rozwiązać szereg kwestii programowych.
Z uwagi na wiele problemów do rozwiązania, stworzenie, a nawet tylko zrozumienie, dobrej i uniwersalnej sieci transmisji danych to zadanie naprawdę bardzo skomplikowane. Nie sposób jej w prosty sposób opisać i objaśnić. Nie wystarczą tu wcześniej znane przykłady i analogie, bo okazują się i zbyt ubogie, i po prostu nietrafne, a nawet wprowadzające w błąd. Takim znanym przykładem mogłaby być klasyczna przewodowa sieć telefoniczna, gdzie skutecznie rozwiązano problem adresowania oraz nawiązywania i kończenia połączeń. Lokalna sieć telefoniczna ma postać gwiazdy. Jest tu lokalna centrala, do której podłączeni są abonenci. Każdy abonent ma przydzielony numer. Jest to numer niepowtarzalny, indywidualny, ale tylko w obrębie sieci lokalnej, czyli powiedzmy w obrębie jednej centrali/miasta. W innych sieciach lokalnych (w innych miastach) inni abonenci mogą mieć ten sam numer, ale nie ma problemu, bo dzwoniąc do innego miasta, musimy wybrać numer kierunkowy (np. dla Warszawy 22, dla Olsztyna 89). Analogicznie w innych krajach mogą występować takie same numery lokalne i kierunkowe miast, ale znów nie ma problemu identyfikacji, bo dzwoniąc do innego kraju, musimy podać prefiks tego kraju, dla Polski to 48. Zasada „geograficznego” trzystopniowego adresowania (numer lokalny, kierunkowy miasta i kierunkowy kraju) jest prosta i jasna. Ale tak było/jest tylko w starych, zanikających już sieciach telefonii przewodowej.
W nieporównanie nowocześniejszych sieciach telefonii komórkowej mamy system adresowania dwustopniowy. Abonent ma (dziewięciocyfrowy) numer, który nie jest przypisany ani „geograficznie”, ani do konkretnego urządzenia, ani nawet do konkretnego operatora „komórkowego”. Numer komórkowy jest niepowtarzalny w danym kraju. W innych krajach mogą być abonenci o takim samym numerze, ale aby się do nich dodzwonić, trzeba podać numer kierunkowy (prefiks) kraju. Numer „komórkowy” jest unikalny w „dużej sieci lokalnej” – w skali kraju.
Aż się prosi, żeby te zrozumiałe przykłady odnieść do sieci komputerowych i Internetu.
Niestety, sieci komputerowe i Internet działają inaczej. Bardzo podobny jest tylko jeden element: też mamy liczne sieci lokalne, numer-adres urządzenia musi być niepowtarzalny, unikalny, tylko w obrębie danej sieci lokalnej, a może się powtórzyć w innych sieciach lokalnych. Natomiast pozostałe aspekty nie są podobne, zwłaszcza do analogowej telefonii przewodowej, bowiem w sieciach komputerowych do przesyłania danych cyfrowych wykorzystuje się nieporównanie bardziej skomplikowane koncepcje. Tak skomplikowane, że nie można ich w prosty sposób opisać i na znanych przykładach wyjaśnić ich działania (aż prosi się powiedzieć, iż krokodyl jest zupełnie inny).
Jak już słusznie czujemy, omawiając sieci komputerowe trzeba uwzględnić szereg aspektów, czyli spojrzeć na nie z kilku różnych punktów widzenia. Oto jeden z nich: gdybyśmy chcieli w miarę prosto zobrazować graficznie proces przesyłania danych między punktami A, B, moglibyśmy spróbować to zrobić jak na rysunku 1. Kolorowe fragmenty każdego pudełka reprezentują różne aspekty związane z tworzeniem sieci i transmisją danych, zarówno sprzętowe, jak programowe, takie jak adresowanie, wyszukiwanie adresata, nawiązywanie i kończenie połączenia, wykrywanie błędów, naprawianie błędów, a przy braku takiej możliwości ponowne przesyłanie brakującej informacji. Reprezentują też aspekty fizycznej budowy łączy i związanych z nimi parametrów. Tworzy się mozaika mocno skomplikowana, którą trudno zrozumieć, a całość może przyprawić o zawrót głowy.
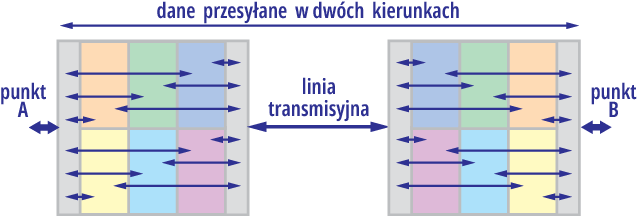
Rysunek 1
Ten problem występuje nie tylko przy tworzeniu sieci do cyfrowej transmisji danych, ale wszędzie tam, gdzie mamy do czynienia z bardziej skomplikowanymi systemami. Problem dostrzeżono już dawno. Jednym z dobrych sposobów jego rozwiązania jest podział dużego skomplikowanego systemu na standardowe moduły. Łatwo zrozumiałym porównaniem, bliskim sercu elektronika, są klasyczne, analogowe oscyloskopy wysokiej klasy. Każdy taki oscyloskop do skomplikowane urządzenie, które musi zrealizować szereg zadań i funkcji. Najczęściej wszystkie te funkcje są scalone w jednym przyrządzie. Ale można niejako podzielić zadanie na części i te poszczególne części zrealizować za pomocą oddzielnych, autonomicznych bloków – modułów. Produkowano takie modułowe oscyloskopy – przykład na fotografii 2 to stary 1-gigahercowy Tektronix 7104.

Fotografia 2
Użytkownik takiego cacka kupował podstawowy, bazowy moduł, a do tego szereg wkładek o różnych możliwościach, które mają standardowe wejścia/wyjścia. Oscyloskop o potrzebnych możliwościach jest składany z gotowych, oddzielnych, standardowych klocków – modułów według aktualnych potrzeb.
W przypadku sieci komputerowych też mamy szereg oddzielnych zadań do wykonania i też można stworzyć rozwiązania, gdzie jeden „duży element” zawierałby specjalizowane „wymienne” elementy rozwiązujące według potrzeb poszczególne problemy i realizujące wszystkie pożądane funkcje. W każdym razie też mamy „wymienne wkładki” o różnych funkcjach, ale sprawa jest znacznie bardziej skomplikowana niż w przypadku oscyloskopu, bo w grę wchodzą kwestie sprzętowe, fizyczne, ale przede wszystkim różne aspekty programowe. Niemniej przesyłanie danych też w pewnym sensie przypomina wymienne moduły – wkładki, które możemy/powinniśmy dobrać i zestawić według potrzeb.
Trudno to wszystko przybliżyć i zobrazować graficznie. Niemniej całą bardzo skomplikowaną sprawę transmisji danych i adresowania na pewno można i warto podzielić na odrębne moduły/bloki/zadania. W przypadku transmisji danych można byłoby to zobrazować i zrealizować według rysunku 3.
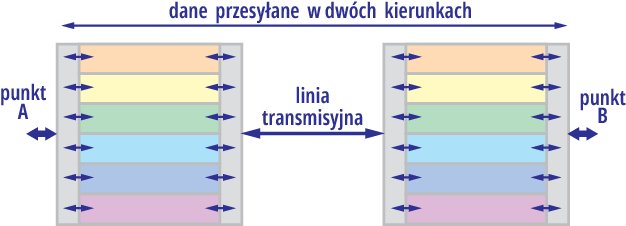
Rysunek 3
Jednak z różnych względów najlepiej by było, gdyby te zadania były wyraźniej oddzielone, autonomiczne i by były realizowane w określonej kolejności niejako szeregowo, co można zobrazować mniej więcej jak na rysunku 4. Przetwarzanie jest niejako „szeregowe” i poszczególne bloki przekazują dane tylko do bloków sąsiednich.
Pionowe kolorowe paski reprezentują tu kolejne, oddzielne zadania – funkcje. Są to głównie zadania programowe.
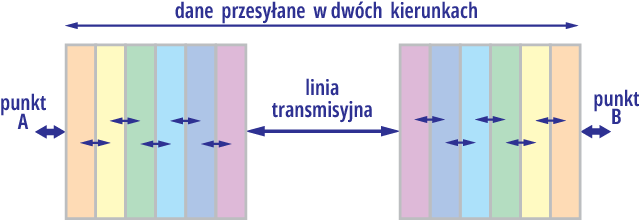
Rysunek 4
W podręcznikach jest to przedstawiane odrobinę inaczej, w postaci „poziomych warstw” tworzących stos, podobnie jak na rysunku 5. Warstwy tego stosu reprezentują poszczególne, oddzielne fragmenty złożonego zadania. Warstwy w stosach zawsze ułożone są w określonej kolejności.
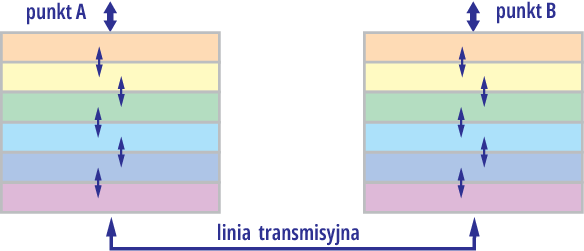
Rysunek 5
Rysunek 5 z dwoma stosami jest bardzo uproszczony i odwraca uwagę od istotnej części zagadnienia, jaką jest adresowanie i wyszukiwanie adresata spośród wielu innych. W związku z tym nieco bardziej odpowiednie, ale też niepełne, byłoby przedstawienie tego na przykład jak na rysunku 6, gdzie dodatkowo pokazana jest droga przepływu danych po „zestawieniu indywidualnego połączenia”.
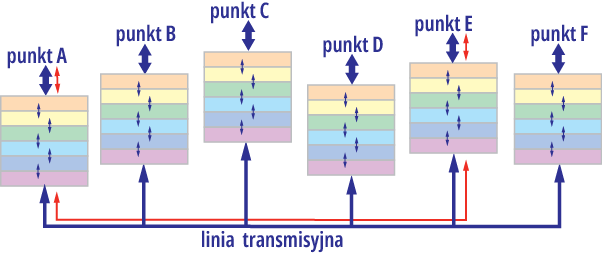
Rysunek 6
Z grubsza rzecz biorąc, mniej więcej tak realizowany jest proces transmisji danych we wszystkich typowych cyfrowych sieciach komputerowych. Bardzo skomplikowane zadanie zostaje podzielone na szereg odrębnych, standardowych zadań – modułów, które są realizowane „szeregowo” i które odpowiadają za poszczególne funkcje, między innymi: nawiązywania i kończenia połączenia, adresowania i kontroli błędów transmisji. I tak doszliśmy do ważnego tematu: stosu (stack) i do poszczególnych warstw (layers).
Stack & layers
Ponieważ całość jest bardzo skomplikowana i na razie omawiamy tylko jeden aspekt tematu sieci komputerowych, nie chciałbym Ci mieszać w głowie nadmiarem szczegółów, jednak musimy wspomnieć o modelu OSI. Aby przekazać informacje z punktu A do punktu B, cały skomplikowany proces dzielimy na moduły – warstwy. W latach osiemdziesiątych rozważano skomplikowaną problematykę cyfrowej transmisji danych i właśnie ze względu na stopień skomplikowania zaproponowano, by twórcy takich systemów realizowali je w uporządkowany, jednolity sposób, co byłoby wszechstronnie korzystne. W roku 1984 ISO i CCITT (ITU-T) zaproponowały wspólnie opracowany tak zwany model OSI (Open System Interconnection), który był wynikiem analizy wcześniejszych rozwiązań „sieciowych”, praktycznie stosowanych już od początku lat siedemdziesiątych. Mianowicie zaproponowano podzielenie zadań realizowanych podczas transmisji danych na moduły, a raczej warstwy. Jak pokazuje rysunek 7, w modelu OSI mamy siedem warstw.
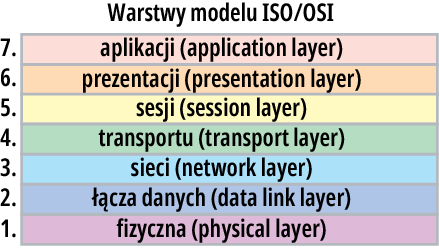
Rysunek 7
Elektronicy przyzwyczajeni są do tego, że współczesny sprzęt zazwyczaj zbudowany jest z oddzielnych fizycznych modułów, jednak w przypadku transmisji cyfrowej i modelu OSI nie chodzi o sprzęt, tylko o oddzielne zadania (moduły) programowe. Model OSI generalnie nie dotyczy więc sprzętu (choć dolne warstwy są z nim ściśle związane, o czym jeszcze będziemy mówić). Model OSI pokazuje tylko przepływ i obróbkę przesyłanych danych.
Idea podziału skomplikowanej całości na zestaw modułów jest prosta, łatwa do zrozumienia i zaakceptowania. Tylko nasuwa się pytanie: czym tak naprawdę są te warstwy?
Otóż słowo–klucz, stanowiące podstawę odpowiedzi brzmi: sa to…
protokoły.
A co to jest protokół?
W tym przypadku słowo protokół nie oznacza sprawozdania, tylko zespół reguł i zasad umożliwiających porozumienie. Według Wikipedii: Protokół komunikacyjny – zbiór ścisłych reguł i kroków postępowania, które są automatycznie wykonywane przez urządzenia komunikacyjne w celu nawiązania łączności i wymiany danych.
Nie wgłębiając się w szczegóły: w sieciach komputerowych wykorzystuje się cztery rodzaje, grupy (warstwy) protokołów. Najprościej biorąc, jeżeli program (aplikacja) w komputerze chce wysłać albo otrzymać informacje od (jakiejś aplikacji z) innego komputera, to ten program wcale nie musi określać wszystkich szczegółów, tylko korzysta ze standardowych protokołów. Stos z rysunku 7 jest więc w istocie stosem, zestawem, pakietem protokołów.
W wielu podręcznikach podkreśla się, że w informatyce mamy do czynienia z pojęciami czysto abstrakcyjnymi, które nie mają postaci fizycznej, realnej. Owszem, ale w przypadku warstw stosu wcale nie musimy ich traktować jako czystej abstrakcji. Słowo–klucz to protokoły, czyli zbiory reguł i zasad. Ale w sieciach informatycznych te reguły są realizowane przez standardowe „kawałki programów”. Można sobie nawet wyobrazić, że warstwy to oddzielne, pracujące w ukryciu programy, które ściśle realizują reguły i zasady określone w znormalizowanych, ściśle ustalonych protokołach. Kluczowe jest to, że dana warstwa stosu, czyli program realizujący dany protokół, wykonuje tylko ściśle określone zadania.
Poszczególne warstwy modelu OSI mają realizować poszczególne oddzielne zadania. Jeśli chcesz, zarówno w podręcznikach, jak i na stronach internetowych, znajdziesz liczne mniej i bardziej zrozumiałe opisy poszczególnych warstw modelu OSI. Dla początkujących znaczącym utrudnieniem okazuje się fakt, iż skądinąd przejrzysty i sensowny model OSI niestety ma związek z wierszem Na wyspach Bergamutach Jana Brzechwy. Proponuję dla odprężenia poszukać i przypomnieć sobie cały tekst tego przewrotnego wierszyka, a ja zacytuję tylko początek i koniec:
Na wyspach Bergamutach,
Podobno jest kot w butach,
(…)
Jest słoń z trąbami dwiema
i tylko… wysp tych nie ma.
Podobnie jest ze znakomitym, przejrzystym modelem OSI z roku 1984… Jest bardzo dobry, wręcz znakomity, jasny i przejrzysty.
Ale tak naprawdę to go nie ma – praktycznie nie jest wykorzystywany w oryginalnej formie siedmiu oddzielnych warstw.
Natomiast bardzo popularna jest, opracowana kilkanaście lat wcześniej, na potrzeby Internetu, idea „szeregowego” połączenia czterech oddzielnych warstw i przekazywania informacji między nimi.
I tak oto doszliśmy do jak najbardziej praktycznego, dominującego dziś modelu: do czterech warstw stosu TCP-IP, standardowo wykorzystywanego w większych i mniejszych sieciach komputerowych. Rysunek 8 pokazuje schemat tego powszechnie stosowanego czterowarstwowego stosu (stack), zwanego TCP/IP. Czasem spotykana jest ładniejsza nazwa; zamiast mówić o stosie (stack), używa się określenia suite – zestaw, pakiet, komplet.
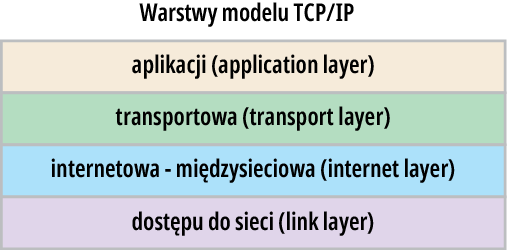
Rysunek 8
Tyle w pierwszym odcinku. Wyjaśniliśmy (mam nadzieję) podstawy koncepcji warstw. Natomiast do tytułowych matrioszek i innych aspektów zagadnienia wracamy w drugiej części artykułu (DR002).
Piotr Górecki