Sieci komputerowe i Internet cz. 5
W poprzednim odcinku (DR004) mówiliśmy o małych, domowych, lokalnych sieciach komputerowych. Wiemy, że i w nich cała komunikacja opiera się na stosie protokołów TCP/IP, co jest zadaniem wieloetapowym i na pozór wydaje się porażająco skomplikowane i trudne. Protokoły istotnie są bardzo skomplikowane i ogólnie biorąc, są realizowane przez inteligentne, złożone programy (a niektóre przez bardzo skomplikowane specjalizowane układy scalone).
Tak, ale protokoły obejmują wszelkie aspekty związane z transmisją także w dużych sieciach komputerowych, w szczególności lokalizowanie adresata i zapewnienie niezawodnej transmisji w każdych warunkach. Dobra wiadomość jest taka: mnóstwo z tych zagadnień nie ma żadnego zastosowania, jeżeli chcemy zrealizować transmisję w małej domowej sieci lokalnej. Jeżeli pokażemy tylko podstawowy sens i przebieg tych etapów (i praktyczny sens warstw stosu), to cała sprawa okaże się zaskakująco prosta. Zacznijmy od najwyższej warstwy aplikacji, gdzie jak pamiętamy, można wykorzystywać różne protokoły, takie jak na przykład HTTP, SMTP, FTP, Telnet, SNMP, DNS, itd.
HTTP – hipertekstowy protokół
W kontekście automatyki domowej kluczowe znaczenie ma protokół HTTP (Hypertext Transfer Protocol), nieodłącznie związany z miliardami stron internetowych www.
Na początek załóżmy, że mamy jakiś komputer, który potrafi wykorzystywać protokół HTTP i będzie pełnił funkcję klienta. Załóżmy, że komputer ten jest na stałe połączony z urządzeniem do pomiaru wilgotności względnej, które też potrafi wykorzystywać protokół HTTP i które będzie pełnić funkcję serwera. Obrazowo można to przedstawić jak na rysunku 1a, natomiast ze strony informatycznej sytuację przedstawiamy jak na rysunku 1b, gdzie ze stosu TCP/IP dobrze widzimy tylko górną warstwę aplikacji z protokołem HTTP, a resztę na razie całkiem pomijamy, traktując jak czarną skrzynkę.
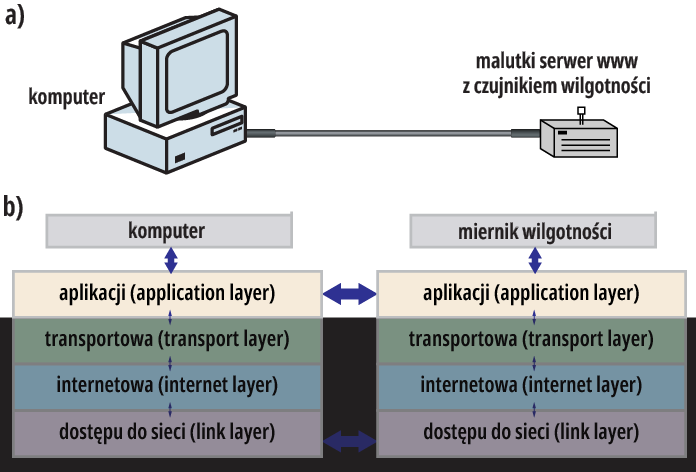
Rysunek 1
Mamy tu stałe połączenie dwóch punktów. Nie potrzebujemy żadnego adresowania, więc jeżeli za pomocą komputera (klienta) chcielibyśmy sprawdzić wilgotność, to z komputera-klienta wyślemy do serwera www zapytanie-żądanie: przyślij informację.
Jeśli mamy wykorzystać przeznaczony właśnie do takich celów protokół HTTP, to użyjemy jego najpopularniejszego polecenia (metody): GET, co możemy rozumieć jako: podaj, przyślij, a co niektórzy Czytelnicy zapewne przetłumaczyliby na zapodaj.
Oczywiście serwer ma przysłać do klienta informację o wilgotności, tylko w jakiej postaci?
Możliwości jest wiele. Mógłby przysłać jakiś obrazek (.jpg, .gif, .png). Mógłby przysłać zwykły tekst składający się ze znaków ASCII. Mógłby przysłać tekst unikodowy zakodowany np. w UTF-8. Owszem mógłby, ale protokół HTTP, zgodnie ze swoją nazwą (Hypertext Transfer Protocol), ma służyć przede wszystkim do przesyłania hipertekstu.
Najprościej mówiąc, hipertekst to coś o wiele „bogatszego”, lepszego od „zwykłego tekstu”. Może to być tekst po pierwsze sformatowany na różne sposoby, a do tego zawierający obrazki i inne „dodatki”. Koncepcję i zasady hipertekstu można sobie wyobrażać rozmaicie, jednak w sieciach komputerowych jest on realizowany za pomocą sposobu, kodu, języka, zwanego HTML.
Skrót HTML pochodzi od Hypertext Markup Language i oznacza język znaczników hipertekstowych. Opiera się na znacznikach, zwanych też tagami (ang. tags). Znów koncepcja jest zaskakująco prosta: plik html to zasadniczo zwykły tekst, tylko zawierający wspomniane znaczniki, które między innymi formatują to, co ma być wyświetlone, czyli zmieniają wielkość, rodzaj czcionki, kolor, itp. Niektóre znaczniki zdecydowanie rozszerzają możliwości prezentacji, bo na przykład zawierają linki do innych zasobów, w tym do obrazków. Rozwijający się od kilkudziesięciu lat język HTML dziś ma ogromne możliwości tworzenia efektownych stron (internetowych), ale jego podstawy są zaskakująco proste. Do HTML zapewne wrócimy, a na razie omówmy próbę użycia komputera do sprawdzenia wilgotności w układzie z rysunku 1. Komputer (klient) wyśle do serwera zapytanie (Request), korzystając z metody GET, a serwer wyśle mu informację w postaci pliku z rozszerzeniem .htm albo .html.
W najprostszym przypadku mogłoby to wyglądać mniej więcej tak: komputer (klient) wysyła zapytanie (Request) w postaci następującego tekstu, ciągu znaków ASCII:
GET /wilg.htm HTTP1.0
Na początku wiadomości mamy tu nazwę metody GET, obowiązkowo pisaną dużymi literami, następnie obowiązkowy ukośnik, potem nazwę pliku (albo ścieżkę do pliku) z informacją o wilgotności, który ma być przysłany (wilg.htm) i na końcu wersję protokołu HTTP (1.0 albo 1.1). W tym przypadku nie ma (nie potrzeba) żadnego adresu, bo założyliśmy, iż mamy stałe połączenie dwóch punktów.
Na takie żądanie serwer wyśle do klienta odpowiedź (Response), która w najprostszym przypadku mogłaby wyglądać tak:
HTTP/1.0 200 OK <html><body>RH=75%</body></html>
Taka odpowiedź w pierwszej linii zawiera informację o wersji protokołu (HTTP1.0), następnie trzycyfrową liczbę, która jest, powiedzmy, kodem błędu. W tym przypadku błędu nie ma, więc kod to 200 i jest on powtórzony słownie: OK. Druga linia odpowiedzi jest pusta, co oddziela jej nagłówek (header) od jej ciała (body). A tym ciałem jest… strona internetowa!
Tak! Serwer wysyła do klienta stronę internetową w postaci pliku HTML, w tym wypadku bardzo skromną:
<html><body>RH=75%</body></html>
Taka odpowiedź trafia w komputerze do przeglądarki, a ta wyświetla dostarczoną stronę (kod HTML) w postaci niezbyt imponującej, niemniej w pełni użytecznej, mniej więcej jak na rysunku 2.
Proste? Zaskakująco proste!
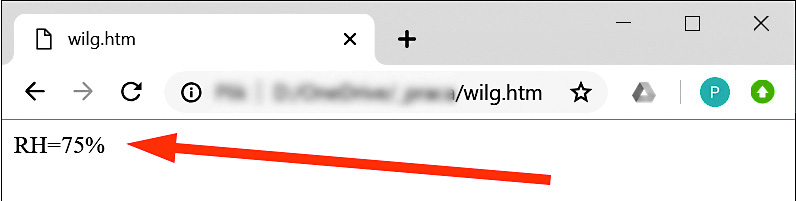
Rysunek 2
Oczywiście w praktyce zarówno zapytanie (Request), jak i odpowiedź (Response) mogą zawierać i najczęściej zawierają dodatkowe opcjonalne informacje, których wcale nie musisz rozumieć. A kod HTML zwykle nie jest aż tak skromny.
Gdyby kod HTML odpowiedzi był „bogatszy”, na ekranie komputera zobaczylibyśmy bardziej efektowny, zapewne dłuższy tekst, z czcionkami różnej wielkości i kroju, z kolorami, ewentualnie z jakimś obrazkiem czy obrazkami. To jednak są drugorzędne szczegóły.
Najważniejsze jest to, że wykorzystanie metody GET z protokołu HTTP jest naprawdę bardzo proste, co ma ogromne znaczenie dla elektronika. Otóż określenie serwer www zwykle kojarzy się z czymś ogromnie skomplikowanym. A oto okazuje się, że jego głównym zadaniem jest przygotowanie prościutkiej strony „hatemelowej”, z czym poradzi sobie nawet najskromniejszy mikroprocesor.
W naszym przykładowym żądaniu zawarta jest nazwa pliku (wilg.htm), ale nie musi to być i wcale nie jest gotowy, statyczny plik, przechowywany w jakiejś pamięci. W naszym przypadku potrzebny kod HTML zostaje na bieżąco stworzony przez mikroprocesor serwera www (przez program) z użyciem najświeższej, odczytanej z czujnika wartości wilgotności.
Najogólniej biorąc, kluczowym zadaniem serwera www jest przygotowanie odpowiedzi (Response) w postaci najzwyklejszego tekstu. W najprostszym przypadku może to polegać na dodaniu dwóch cyfr aktualnego wyniku pomiaru do stałego łańcucha znaków ASCII. Przy stałym połączeniu według rysunku 1, bez konieczności adresowania, mogłoby to być jedyne zadanie serwera, banalnie proste. W rzeczywistości aż tak prosto nie jest.
Kwestia adresowania
Konieczność adresowania i wykorzystania stosu protokołów TCP/IP niewątpliwie komplikuje sytuację, ale znów elektronik zainteresowany wykorzystaniem sieci komputerowej w inteligentnym domu wcale nie musi znać wszystkich szczegółów. Musi rozumieć tylko podstawowe zasady adresowania, a potem te zasady wykorzystać w praktyce.
W poprzednim odcinku dowiedzieliśmy się, że każda domowa lokalna sieć komputerowa ma „swój numer”. Z reguły dwie pierwsze liczby numeru-adresu takiej sieci IP to 192.168. Trzecia liczba może być dowolna w zakresie od 0…255. Czwarta liczba w numerze sieci to zawsze 0. Bardzo często domowe sieci mają „niskie” numery 192.168.0.0…192.168.10.0. W każdej takiej małej sieci lokalnej (która ma maskę 255.255.255.0) możemy mieć ponad 250 urządzeń.
Jeżeli przykładowo sieć ma numer 192.168.1.0, to wszystkie pracujące w niej urządzenia mają (muszą mieć) adresy IP w zakresie 192.168.1.1…192.168.1.254.
Wróćmy teraz do wcześniejszego przykładu starej prostej sieci LAN, gdzie dodajemy prosty serwerek www obsługujący czujnik wilgotności według rysunku 3.
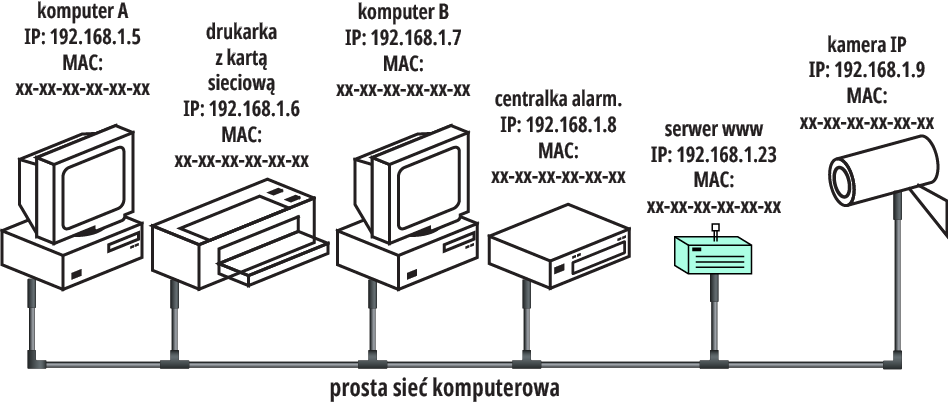
Rysunek 3
Jak w każdej sieci komputerowej, także i tu każde dołączone urządzenie ma przydzielony adres-numer IP. Dodany właśnie serwer www niech ma numer 192.168.1.23 – dobry jak każdy inny. Każde z urządzeń sieciowych pracujących w ethernetowej sieci LAN ma też jakiś „fabryczny” numer-adres MAC. Jak mówiliśmy wcześniej, w danej sieci LAN mamy powiązania sprzętowego numeru MAC z logicznym numerem IP. W naszym prościutkim przypadku adresy MAC teoretycznie nie byłyby konieczne, bo komunikacja zasadniczo odbywa się w oparciu o adresy IP, ale z różnych względów nawet w najmniejszych i najprostszych sieciach komputerowych wykorzystujemy wszystkie warstwy stosu TCP/IP, więc trzeba posługiwać się parami adresów IP + MAC.
Najprościej biorąc, w przypadku z rysunku 3, gdybyśmy chcieli za pomocą komputera A sprawdzić wilgotność, to oczywiście musiałby on wysłać zapytanie GET, ale trzeba byłoby też dodać informacje adresowe. Omawiamy to w następnym odcinku (DR006).
Piotr Górecki