Sieci komputerowe i Internet cz. 7
W poprzednim odcinku (DR006) omówiliśmy metodę GET protokołu HTTP, powszechnie wykorzystywaną do przesyłania stron internetowych, które okazały się hipertekstem. Wspomnieliśmy o języku znaczników HTML, który pozwala tworzyć hipertekstowe strony internetowe. Co najważniejsze, dowiedzieliśmy się, na czym polega rola prostego serwera www i co musi on przygotować jako odpowiedź na zapytanie GET.
Wiemy, że taka odpowiedź serwera www może być stosunkowo prosta, ale musi zawierać wszystkie elementy, wymagane przez poszczególne warstwy – protokoły stosu TCP/IP. Omówiliśmy też nadmiernie uproszczony przykład wykorzystania szablonu do przygotowania potrzebnej ramki ethernetowej. Idea szablonu jest słuszna i atrakcyjna, jednak zbyt prosta i nie można jej wykorzystać bezpośrednio. Przyczyną są podstawowe reguły działania niższych warstw.
Dodatkowe problemy
Przypomnijmy, że w systemie według rysunku 1 na prościutkie żądanie:
GET /wilg.htm HTTP1.0 host: 192.168.0.23
nasz prosty serwer www mógłby wysłać następującą odpowiedź:
HTTP/1.0 200 OK <html><body>RH=75%</body></html>
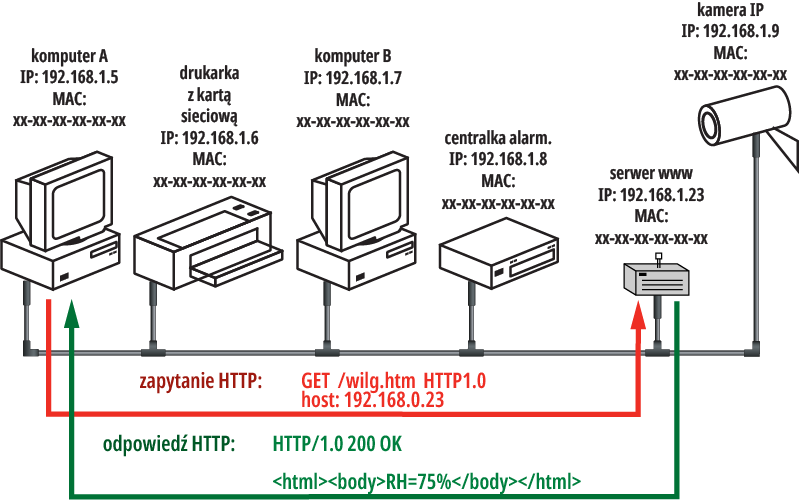
Rysunek 1
Tak, tylko do kogo wysłać? W odpowiedzi nie ma żadnego adresu. W tak prostej sieci każda wiadomość trafia do wszystkich urządzeń, ale na pewno dla kamery i dla drukarki taka informacja jest „niestrawna” i bezwartościowa.
Wiadomość powinna być spożytkowana tylko przez klienta, który wysłał zapytanie… W naszej sieci mamy dwa komputery, a zapytanie było wysłane z komputera A. Odpowiedź powinna być w jakiś sposób zaadresowana do komputera A.
Ale są jeszcze inne możliwości i problemy. Mianowicie może się zdarzyć, że najpierw zapytanie do serwera wyśle komputer A, a po chwili identyczne zapytanie wyśle komputer B. Czy serwer www powinien odesłać jedną odpowiedź, czy dwie odpowiedzi?
A co wtedy, gdyby zapytania z dwóch komputerów zostały wysłane jednocześnie?
Rysunek 1 pokazuje przykład tzw. domeny (sieci) kolizyjnej, gdzie w danej chwili tylko jedno urządzenie może nadawać. Jeśli w jednym czasie nadaje więcej niż jedno, to przekaz staje się błędny. Ale nie ma tu mechanizmów zapobiegających jednoczesnemu nadawaniu. Problem można rozwiązać na kilka sposobów, ale przyjmijmy następujący. Urządzenia nie tylko wysyłają dane, lecz też na bieżąco sprawdzają, czy przekaz jest prawidłowy. Gdy jednocześnie próbują nadawać dwa urządzenia (lub więcej), to po chwili oba stwierdzą, że przekaz jest błędny, co świadczy o kolizji. Wtedy oba przestają nadawać i oba ponawiają próbę, ale po upływie losowo wybranego czasu, różnego dla każdego urządzenia i każdej próby. Problem dotyczy też naszego prościutkiego serwera www, który może nadawać wtedy, gdy próbuje nadawać któreś inne urządzenie. Tu widać, że tylko z tego powodu także w naszym serwerze www nie można wykorzystać wspomnianej wcześniej prostej zasady: „uzupełnij szablon i wyślij”. Serwer www musi mieć opisany mechanizm, wykrywający kolizje i zapewniający ponowienie transmisji po jej wykryciu. A to wymaga pewnej komplikacji programu procesora.
Nie jest to jedyny problem.
TCP – Porty i gniazda
Być może do naszego serwera www dwa zapytania, jedno tuż po drugim, przyślą oba komputery z sieci.
Po pierwsze, nasz serwerek nie powinien zignorować, „zapomnieć” tego wcześniejszego. Powinien odpowiedzieć na oba. A to też wymaga pewnej komplikacji programu serwera. Po drugie, treść obu zapytań GET będzie (może być) identyczna. A w samym zapytaniu protokołu HTTP wykorzystującym metodę GET nie ma adresu nadawcy! Ale adres nadawcy jest w niższych warstwach, w zasadzie w warstwie sieciowej jako adres IP, ale sprawa jest znacznie bardziej skomplikowana, zwłaszcza w dużo większych sieciach, gdzie jest wiele komputerów i wiele „dużych serwerów”.
Problem powstaje „na dwóch końcach łącza”. Otóż często w przeglądarce mamy otwartych szereg okien (stron) i z poszczególnych okien wysyłamy różne zapytania do tego samego serwera www. Wysyłamy zapytania GET, więc przekaz zawiera też informację o naszym adresie IP. Serwer prawidłowo obsługuje te zapytania i odsyła odpowiedzi na adres IP naszego komputera. Ale czy trafią one do właściwych okien przeglądarki, skąd je wysłaliśmy?
A co wtedy, gdy z komputera wysyłamy zapytania GET do kilku serwerów i wszystkie odsyłają nam odpowiedzi na ten sam adres IP? Jak trafią do właściwych okien przeglądarki (do właściwych procesów w komputerze)?
Problem jest i po stronie serwera. Mianowicie mogą do niego docierać zapytania z tym samym adresem IP, z tego samego komputera, ale z innych okien przeglądarki (od różnych procesów). Niektóre wymagają tylko króciutkiej, „jednorazowej” odpowiedzi, ale inne wymagają „odpowiedzi dłuższej”. Nie wchodząc w szczegóły, przypomnijmy, że dłuższe przekazy trzeba dzielić na „mniejsze kawałki”.
Do bałaganu nie dopuszcza protokół warstwy transportowej (TCP albo UDP). Wcześniej wspomnieliśmy, że protokół UDP jest poniekąd „jednokierunkowy”, a TCP jest niezawodny, bo wymaga potwierdzania otrzymania danych, które w przypadku zagubienia są przesyłane ponownie. To błogosławieństwo niezawodności jest jednak okupione komplikacją transmisji.
Po pierwsze wprowadzono pojęcie sesji (ang. Session). Aby uniknąć bałaganu i odróżnić jedną sesję od drugiej, wprowadzono też pojęcie portu (Port) i gniazda (Socket). O tym za chwilę.
Można powiedzieć, że przez większość czasu w sieci komputerowej nic się nie dzieje, a ruch w sieci to zwięzłe zapytania i odpowiedzi: albo krótkie, albo dłuższe, ale składające się z „niedużych kawałków”. Gdy klient wysyła do serwera zapytania, wtedy otwierana, rozpoczynana jest sesja. Ta sesja jest kończona, gdy serwer odeśle kompletną odpowiedź. Sesja jest jednoznacznie identyfikowana przez wspomniane porty i gniazda. Już tu widać, że nasze wcześniejsze wyobrażenie o prostym wysłaniu zapytania GET do serwera i o szablonie do przygotowania odpowiedzi było naiwne, ponieważ nie uwzględniało specyfiki protokołu transportowego TCP.
Nie wchodząc w szczegóły: po pierwsze, protokół TCP na początku sesji wstępne nawiązuje kontakt między klientem i serwerem, co jest określane jako potrójny uścisk dłoni (3-way handshake). Można to sobie wyobrazić, że zanim nastąpi przesłanie zapytania GET, wcześniej następuje „wstępna wymiana uprzejmości” przez przesłanie trzech krótkich komunikatów wstępnych. Serwer oprócz przygotowania „właściwej odpowiedzi” musi najpierw potwierdzić nawiązanie sesji.
Po drugie, jak już się zorientowaliśmy, w komputerze lub serwerze, który ma jeden konkretny adres IP, może być realizowanych wiele procesów, które wysyłają zapytania i odpowiedzi, otwierając i zamykając liczne sesje. Najprościej biorąc, jeśli klient otwiera sesję, to wykorzystuje pomocniczą liczbę – identyfikator. Ale informatycy nie mówią o „pomocniczych liczbach”, tylko o… portach.
I tu elektronik ma problem, bo określenie port kojarzy mu się z czymś konkretnym, z urządzeniem. A teraz mówimy o abstrakcyjnych portach, które są… pomocniczymi liczbami. Liczbami 16-bitowymi z zakresu od 1 do 65535, pomagającymi odróżniać sesje i procesy.
Znów mówiąc najprościej, podczas danej sesji mamy dwie pary liczb. Taka para to adres IP i numer portu (liczba pomocnicza do identyfikacji sesji/procesu). Do tego jest informacja o użytym protokole transportowym: TCP albo UDP.
I kolejna kłoda pod nogi elektronika: taką „trójkę”: nazwę protokołu, numer IP i numer portu informatycy nie bardzo wiadomo dlaczego nazywają… gniazdem (Socket).
Okazuje się, że oprócz adresu MAC i adresu IP, do komunikacji klient-serwer muszą zostać wykorzystane te liczby – porty. Co prawda bez świadomego udziału człowieka, ale program nawet najprostszego serwerka www musi sobie z nimi poradzić.
Po trzecie, protokół transportowy (TCP) dba o to, żeby „właściwe dane” o dużej objętości były przesyłane w porcjach, przy czym numerowane są nie tylko kolejne porcje, ale poszczególne bajty przekazu. W protokole TCP otrzymanie każdej porcji jest potwierdzane i można łatwo upomnieć się o „zaginione porcje”. Serwer www musi więc sobie poradzić, gdy otrzyma wiadomość, że coś zaginęło i trzeba powtórzyć przekaz.
Dzielenie na porcje jest konieczne przy przesyłaniu większych ilości danych. W najprostszych przypadkach i zapytanie, i odpowiedź zmieściłyby się w jednej porcji. Tak, ale jeśli już wykorzystujemy niezawodny protokół TCP, to nawet przy przesyłaniu pojedynczych porcji są stosowane jego reguły, w tym potrójny uścisk dłoni i potwierdzanie oraz wykorzystywane są numery portów. W związku z tym nawet w najprostszym serwerze www trzeba zrealizować kluczowe wymagania protokołu TCP.
Zawodowi informatycy muszą znać wszystkie szczegóły, a elektronik korzystający z „gotowców” powinien tylko z grubsza rozumieć koncepcję sesji, gniazd i portów.
Idea znów jest prosta: gdy klient z pomocą protokołu HTTP wysyła zapytanie GET, czyli komunikat z warstwy aplikacji, zapytanie to zostaje przekazane do niższej warstwy transportowej i wtedy program „transportowy” musi do tego komunikatu dodać nagłówek warstwy transportowej. W takich przypadkach wykorzystywany jest niezawodny protokół TCP, więc po dodaniu nagłówka powstanie segment.
Rysunek 2 pokazuje budowę (szablon) nagłówka segmentu TCP. Mamy tu przede wszystkim dwa „numery pomocnicze”, czyli porty: port źródłowy i port przeznaczenia – docelowy. Mamy też dwa 32-bitowe numery: sekwencyjny i potwierdzenia, wykorzystywane do numerowania kolejnych przesyłanych bajtów i komunikatów. Mamy bity pomocnicze (flagi), w tym ACK, SYN, FIN. Oprócz tego sumę kontrolną i dodatkowe informacje.

Rysunek 2
W małym serwerku program (procedura), realizujący wymagania protokołu TCP, musi przede wszystkim numerować kolejne komunikaty, odczytywać i wpisywać numery portów oraz obsługiwać flagi ACK, SYN, FIN, wykorzystywane do nawiązania i zakończenia sesji. Zadanie nie jest bardzo skomplikowane i po części wracamy do koncepcji szablonu.
Podobnie jest z następną warstwą sieciową, gdzie segment TCP zostaje uzupełniony o adres IP, dodaje pakiet IP. W tej warstwie też działanie programu jest w dużym stopniu korzystaniem z szablonu, pokazanego na rysunku 3.

Rysunek 3
I znów: informatyk musi wiedzieć wszystko o nagłówku IP, a elektronik realizujący serwer z użyciem „gotowców” – prawie nic. Wystarczy wiedzieć, że mamy tu dwa 32-bitowe numery, adresy IP: źródłowy i docelowy. I koniecznie trzeba też zrozumieć inny szczegół: na pewno tutaj, w warstwie sieciowej mamy docelowy adres IP. Ale my adres IP umieściliśmy w warstwie aplikacji. Mianowicie już komunikacie GET pojawił się adres IP (hosta) odbiorcy, naszego serwerka www (192.168.0.23). Czy to niepotrzebne dublowanie? NIE!
Wyjaśniamy to w następnym odcinku DR008.
Piotr Górecki