Sieci komputerowe i Internet cz. 8
W poprzednim odcinku (DR007) zauważyliśmy dublowanie adresów IP: ten sam adres IP umieszczony był i w warstwie aplikacji (w metodzie GET) i w warstwie sieciowej (w ramce protokołu TCP). Musimy wyjaśnić, że nie jest to niepotrzebne dublowanie.
Otóż nasz wcześniejszy prościutki przykład metody GET dotyczy sieci lokalnej, natomiast generalnie protokół HTTP i jego podstawowa metoda GET opracowane zostały przede wszystkim na potrzeby ogromnej sieci, jaką jest ogólnoświatowy Internet. W metodzie GET zazwyczaj nie podajemy numeru -adresu IP.
I tu znów dla elektronika przyzwyczajonego do sprzętu i „konkretów” jest pewien problem, bo trzeba się przyzwyczajać do abstrakcji: otóż ktoś kiedyś wpadł na genialny pomysł, żeby stworzyć jednolity, czyli zunifikowany system identyfikacji „różnych rzeczy” – zasobów. Poszczególne „różne rzeczy” otrzymują zunifikowane identyfikatory, zwane URI (Uniform Resource Identifier = Ujednolicony Identyfikator Zasobów). Koncepcja taka wykorzystywana jest w Internecie, gdzie trzeba było wprowadzić nie tylko konieczność identyfikacji, czyli rozróżnienia rozmaitych zasobów: nie tylko stron internetowych, ale i plików PDF, obrazków, klipów muzycznych i filmowych, itp. Trzeba było też wykorzystać skuteczny system lokalizacji – znajdowania takich różnorodnych zasobów, co z kolei nazywa się URL (Uniform Resource Locator).
I właśnie w większości przypadków w metodzie GET podajemy nie numer-adres IP, tylko URI, czyli Uniform Resource Identifier, Ujednolicony Identyfikator Zasobów, a właściwie URL. Taka informacja o lokalizacji zasobu w ogólnoświatowym Internecie składa się z trzech części. Oto przykład:
http://piotr-gorecki.pl/images/obrazek.png
Na początku mamy nazwę protokołu, którym się posłużymy (http). Druga część „namiarów lokalizacyjnych”, czyli piotr-gorecki.pl, to docelowo będzie adres IP serwera, gdzie umieszczone są zasoby (właśnie zasoby!) mojej strony. Trzecia część (/ images/obrazek.png) to ścieżka, pokazująca „drogę do zasobu na danym serwerze”.
Jak widać, identyfikator URL w poleceniu GET nie musi wskazywać pliku, w tym przypadku .htm, a może na przykład dotyczyć uruchomienia jakiegoś programu/skryptu, ale to już są trudniejsze, niepotrzebne nam teraz szczegóły.
W każdym razie w warstwie aplikacji, w metodzie GET zazwyczaj mamy/podajemy adres internetowy nie w postaci numeru IP, tylko w dużo przystępniejszej dla człowieka postaci nazwy domenowej. Przykładowo Twoja przeglądarka nie wie, jaki jest numer IP serwera, na którym „stoi” moja strona (ja też nie wiem i nie chce mi się sprawdzać). Dlatego zanim przeglądarka standardowo wyśle zapytanie GET do serwera obsługującego moją stronę, najpierw musi dowiedzieć się, jaki jest jego adres-numer IP. W tym celu z wykorzystaniem transportowego protokołu UDP wysyła zapytanie do tak zwanego serwera nazw, wykorzystując specjalnie do tego celu stworzony protokół DNS (Domain Name System).
Serwer nazw grzecznie odpowiada, podając 32-bitowy numer IP serwera, gdzie „postawiona jest” moja strona.
Dopiero po otrzymaniu z serwera nazw 32-bitowego numeru IP, numer ten zostanie wstawiony właśnie do nagłówka warstwy sieciowej według rysunku 3 jako adres docelowy.
W „normalnym” Internecie przewidziany jest taki właśnie, „okrężny” sposób lokalizacji zasobów, bo człowiek nie zapamięta liczb-adresów IP, a łatwiej mu zapamiętywać nazwy domenowe. I dlatego potrzebne są protokół i usługa DNS oraz serwery nazw, zawierające aktualne przypisania, powiązania nazw domenowych z numerami IP serwerów, gdzie zawarte są odpowiednie zasoby.
Tego problemu nie ma w sieci lokalnej, gdzie nie ma nazw domenowych, gdzie wykorzystujemy wyłącznie numery IP. Dlatego ja już w zapytaniu GET wpisałem numer IP. W zapytaniu wpisaliśmy tam też /wilg.htm, czyli zażądaliśmy zasobu w postaci strony HTML o nazwie wilg.htm.
Jeżeli jednak rozbudujemy nasz serwerek o czujnik pomiaru temperatury, to moglibyśmy też przewidzieć dostęp do „dwóch zasobów”, na przykład:
GET /wilg.htm HTTP1.0 GET /tempr.htm HTTP1.0
co oczywiście będzie wymagać odpowiedniego zaprogramowania części „internetowej” naszego serwerka.
W takich rozwiązaniach raczej nie komplikujemy systemu, a raczej próbujemy go uprościć, co może wiązać się ze skróceniem zapytania GET do bardzo krótkiej postaci:
GET / HTTP1.0
gdzie po obowiązkowym ukośniku nie mamy żadnej nazwy czy ścieżki. Na takie lakoniczne zapytanie nasz serwerek odpowie w jedyny znany sobie sposób, zapewne wysyłając hipertekstową stronę internetową, czyli kod HTML.
Sporo już wiemy, ale do pełni szczęścia brakuje nam jeszcze informacji o paru szczegółach dotyczących portów i gniazd.
Porty i gniazda
Znów idea jest prosta. Dla rozróżnienia licznych procesów (i sesji) zarówno po stronie klienta, jak i serwera potrzebne są dodatkowe numery pomocnicze – numery portów w zakresie 1…65535. Jeżeli z okna przeglądarki wysyłamy zapytanie GET, nie podajemy żadnego numeru portu. Ale ten komunikat HTTP jest przekazywany do programu realizującego protokół TCP warstwy transportowej. I ten program wie, że w polu: Port źródłowy (patrz rysunek 2) musi wpisać losowo wybrany numer portu.
Tak, numer wybrany losowo, ale najogólniej biorąc, nie mniejszy niż 1024. W komputerze numer ten na żądanie programu-przeglądarki przydzielany jest przez system operacyjny, który dba, żeby każdy proces w komputerze (każda otwierana sesja) otrzymał inny numer portu.
Podkreślmy: rozpoczynając sesję, program realizujący TCP wpisuje w pole Port źródłowy losowo wybrany dowolny numer portu (na pewno większy niż 1023). A co ma wpisać w pole Port docelowy?
Sprytnie wymyślono, że tu zawsze trzeba wpisać ściśle określony numer, umownie i na stałe przyjęty dla danego protokołu warstwy aplikacji. I tak dla HTTP ustalono numer portu 80.
Dla innych protokołów przyjęto inne „stałe” numery portów. Są one nazywane „portami dobrze znanymi” (well known ports) i dla nich zarezerwowano numery portów 1…1023. Oto niektóre:
Port Protokół
53 DNS
20 FTP – przesyłanie danych
21 FTP – przesyłanie poleceń
67 DHCP – serwer
68 DHCP – klient
80 HTTP (proxy najczęściej 8080)
443 HTTPS (HTTP na SSL)
143 IMAP
220 IMAP3
110 POP3
995 POP3S (POP3 na SSL)
25 SMTP
22 SSH
23 Telnet
69 TFTP
161 SNMP
Serwer www zgodnie z nazwą serwuje (udostępnia) strony www, wykorzystując przeznaczony do tego protokół HTTP z „portem charakterystycznym” numer 80. Oznacza to, że na początek sesji od wszystkich klientów do serwera www będą przysyłane wyłącznie segmenty, mające ustawiony port docelowy 80.
Dlatego mówi się, że serwer www nasłuchuje na porcie 80.
Cała wymiana informacji z serwerem mogłaby się opierać wyłącznie na porcie 80 bez obawy o pomyłki, ponieważ sesja jest identyfikowana nie przez dwie, tylko przez cztery liczby. Mianowicie przez dwa adresy: IP klienta i serwera oraz dwa numery portów: klienta i serwera. Jednak na marginesie warto wspomnieć, że serwer www po odebraniu pierwszego segmentu z przeznaczonym dla niego portem 80 może niejako zmienić swój port z 80 na numer wyższy niż 1023, losowo wybrany dla danego zapytania i wtedy dalsza komunikacja odbędzie się z „indywidualnymi” numerami portów po obu stronach. Po zakończeniu sesji wykorzystane numery portów są zapominane.
Dla nas istotne jest, że nasz serwerek www ma przyjmować i obsługiwać segmenty z przeznaczonym dla niego domyślnym numerem portu 80. Jednak możliwe jest, że wyznaczymy dowolny inny numer portu, na który ma reagować nasz serwer. Wtedy ktoś korzystający z przeglądarki i domyślnego portu 80 „nie dogada się” z naszym serwerkiem. Tylko wtajemniczeni, wpisując w wyszukiwarkę numer IP i dodatkowo „nasz prywatny” numer portu, pobiorą informację z serwera. To jednak jest nieco wyższa szkoła jazdy.
Na razie omówiliśmy z grubsza, jak mają być tworzone nagłówki kolejnych warstw. Wymaga to programów/procedur o pewnej inteligencji, ale w sumie nie jest bardzo trudne, bo poniekąd polega na wypełnianie pewnych pól szablonu. Tym bardziej że nie musimy pilnować wszystkich szczegółów, ponieważ zrobią to za nas „gotowce”.
Takimi „gotowcami” jest oprogramowanie, opisywane w cyklu Infinity Andrzeja Pawluczuka. Dla najbardziej dociekliwych Czytelników jest to też cenne, znakomite źródło wiedzy, jak te procedury można zrealizować samodzielnie, praktycznie od zera.
Oczywiście analiza tych artykułów oraz opisywanych w nich programów i procedur do najłatwiejszych nie należy. Właśnie dlatego omawiamy teraz te zagadnienia w dużym uproszczeniu, żeby osoby mniej zaawansowane mogły wracać, i to może nie jeden raz, ale kilkakrotnie, do analizy szczegółów.
A dla osób, które nie mają siły albo chęci do wnikania w szczegóły, mam dobrą wiadomość: w systemie Arduino mamy i gotowe moduły ethernetowe z gniazdkiem „internetowym”, i gotowe biblioteki do obsługi stosu TCP/IP praktycznie na zasadzie szablonu. Do ich wykorzystania wystarczą podstawowe wiadomości, które teraz sobie stopniowo przyswajamy.
Na razie mamy wyobrażenie, jak tworzone są komunikaty HTTP, segmenty TCP i pakiety IP. Można się słusznie domyślać, że analogicznie jest z najniższą warstwą dostępu do sieci, gdzie też mamy stosowny nagłówek, pozwalający stworzyć finalną ramkę ethernetową.
Rysunek 4 pokazuje budowę przykładowej ramki (są też nieco inne odmiany ramek najniższej warstwy, w tym jeszcze prostsze). I znów mamy tu kilka, w sumie zaskakująco niewiele pól, z których najważniejsze dla naszych rozważań to dwa adresy MAC: urządzenia źródłowego i docelowego.
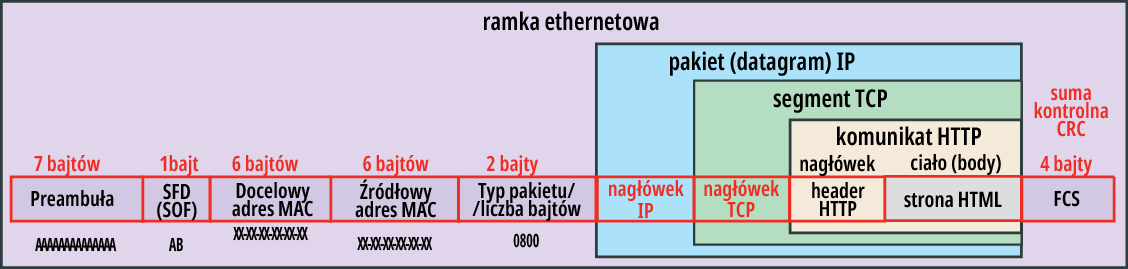
Rysunek 4
Już wcześniej sporo mówiliśmy o powiązaniu logicznych adresów IP ze sprzętowymi, „fabrycznymi” adresami MAC. Wykorzystywaliśmy analogię powiązania między (logicznym) numerem telefonu i fizycznym, sprzętowym numerem IMEI. Taka analogia mogłaby wystarczyć. Można byłoby rozumieć to bardzo prosto: w sieciach internetowych podstawą komunikacji i adresowania są logiczne numery IP, ale „na najniższym etapie sprzętu” pod adresy IP są podstawiane sprzętowe adresy MAC.
Można działanie sieci komputerowej rozumieć w ten sposób, bo takie wyobrażenie jest bliskie prawdy. Jednak w naszych współczesnych sieciach lokalnych, także tych domowych, nie można mówić o przyporządkowaniu adresów IP:MAC na zasadzie 1:1. Zagadnienie ma różne aspekty. Najprościej biorąc, można stwierdzić, iż w sieci komputerowej LAN adresów MAC może być więcej niż numerów IP. Dla wielu zagadką jest też związek urządzeń Wi-Fi z Internetem. Te kwestie mogą być dużym problemem dla elektroników, którzy chcą rozbudowywać swoje domowe sieci LAN o samodzielnie realizowane serwery www. Na życzenie Czytelników możemy zająć się takimi zagadnieniami związanymi ze stroną sprzętową sieci LAN.
Piotr Górecki