Sieci komputerowe i Internet cz. 2
W poprzednim artykule (DR001) na przykładzie oscyloskopu z wymiennymi modułami – wkładkami omówiliśmy podstawową koncepcję wykorzystaną w sieciach komputerowych przy przesyłaniu danych: Ponieważ zadanie okazuje się bardzo obszernie dzielimy je na „standardowe moduły”. Nie są to moduły sprzętowe, fizyczne, tylko oddzielne zadania. Zadania realizowane według ustalonych standardowych reguł – protokołów. Określona jest też kolejność wykonywania tych zadań. W sumie przyjęte rozwiązania ilustruje się pojęciem warstw (zadań) i stosu (kompletu zadań) realizowanych według zestawu, suity protokołów. A teraz tytułowe matrioszki.
Matrioszki
Wiadomo, że w sieciach komputerowych wykorzystuje się szeregowe przesyłanie danych cyfrowych. Jednak bity i bajty przeznaczone do przesłania nie są przekazywane „w całości”. Z różnych względów korzystne, a wręcz konieczne, okazuje się podzielenie ich na „nieduże paczki”, przesłanie tych „paczek” oddzielnie, a u odbiorcy ponowne złożenie ich w całość. Aby to było możliwe, każda taka paczka oprócz części „właściwych danych”, zawiera też informacje dodatkowe, pomocnicze, najogólniej mówiąc „adresowe i porządkowe”.
Cechą charakterystyczną omawianego rozwiązania jest to, że w urządzeniu wysyłającym informacje dana warstwa stosu (program realizujący protokół), przekazując „niedużą paczkę danych” do niższej warstwy, zawsze na jej początku (i czasem na końcu) dodaje do tej paczki „swoje” informacje pomocnicze, charakterystyczne dla danej warstwy. Z kolei w urządzeniu odbierającym informacje dana warstwa, przekazując „niedużą paczkę danych” w górę stosu, odczytuje, wykorzystuje i usuwa przeznaczone dla niej informacje pomocnicze należące do tej właśnie warstwy. Przypomina to popularne matrioszki – rosyjskie drewniane lalki, wkładane jedna w drugą, pokazane na fotografii tytułowej.
Nieduża paczka właściwej informacji wędrując u nadawcy w dół stosu, obrasta więc w informacje pomocnicze, a potem u odbiorcy, wędrując w górę, na powrót kolejno traci te informacje pomocnicze. W przypadku stosu TCP/IP można to zilustrować w bardzo dużym uproszczeniu i też niezbyt ściśle jak na rysunku 9. Dokładniej biorąc, poszczególne warstwy – protokoły określają między innymi, jakie dodatkowe informacje dodawane są w poszczególnych warstwach i jak te informacje wykorzystać do zrealizowania potrzebnych funkcji.
Rysunek 9
Ale po co taka zabawa z oddzielnymi informacjami pomocniczymi poszczególnych warstw? Czy nie lepiej dodać/usunąć te wszystkie informacje pomocnicze za jednym zamachem, w jednym miejscu, na przykład na koniec procesu przetwarzania?
Nie! Otóż jeśli nawet koncepcja z rysunku 9 wymaga znacznie więcej pracy i zabiera więcej miejsca, okazuje się zdecydowanie lepsza, bowiem zapewnia to elastyczność i uniwersalność: wymienność modułów.
Choćby tylko dlatego, że w danej warstwie, zależnie od potrzeb, mogą być wykorzystane różne protokoły dotyczące (należące do) danej warstwy, podobnie jak w modułowym oscyloskopie, zależnie od potrzeb, można stosować wymienne wkładki o różnych możliwościach.
„Wymienne” protokoły
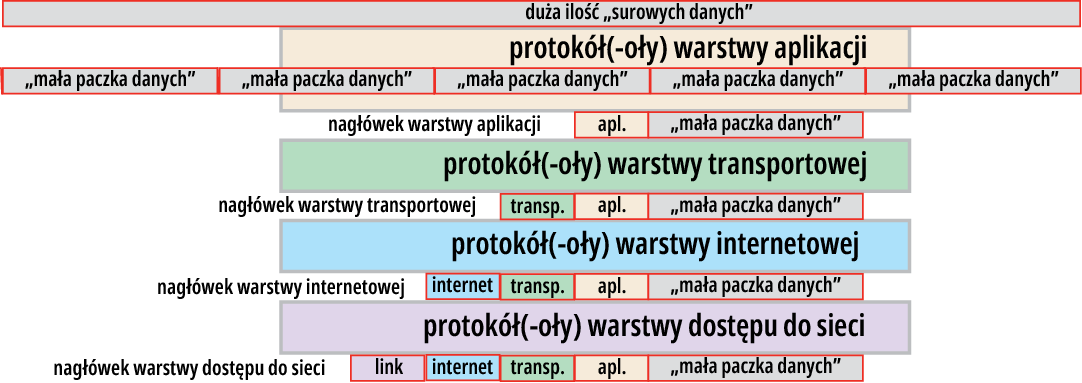
W stosie TCP/IP mamy cztery warstwy, ale wykorzystywanych protokołów jest wielokrotnie więcej. I to jest ogromna zaleta koncepcji (kilku) warstw i (wielu możliwych „wymiennych”) protokołów. Pewne pojęcie o dodatkowych informacjach daje rysunek 10, do którego będziemy jeszcze wracać. Jest to bardzo interesujący temat (i też wcale nietrudny), ale my chcemy omówić tylko szkielet koncepcji i w te interesujące szczegóły na razie wgłębiać się nie będziemy. Ale trzeba przynajmniej z grubsza wyjaśnić sprawę „wymiennych wkładek”, czyli grup protokołów poszczególnych warstw.

Rysunek 10
Warstwa aplikacji. Biorąc rzecz w największym uproszczeniu, „surowe dane cyfrowe”, które aplikacja chce przesłać przez sieć komputerową, zostają w tej pierwszej górnej warstwie, czyli przez wybrany protokół górnej warstwy, poddane wstępnej obróbce. Obróbka ta, z grubsza biorąc, obejmuje doprowadzenie ich do postaci, powiedzmy, standardowej, jednolitej „przed wysłaniem ich w świat”. I odwrotnie, po odebraniu danych trzeba z „jednolitej postaci” przekształcić je do formy, jaka jest właściwa dla danej aplikacji.
Najprawdopodobniej spotkałeś skróty HTTP, HTTPS (strony internetowe), FTP, NFS (przesyłanie plików), POP3, SMTP, IMAP (poczta e-mail), DNS (adresy internetowe), SST (szyfrowanie wiadomości), IRC, NTP, itd. To są nazwy – skróty protokołów górnej warstwy i dana aplikacja w komputerze, chcąc wysłać albo odebrać dane, wykorzystuje co najmniej jeden z nich do przygotowania danych do transmisji.
Warstwa transportowa. Dane wstępnie przetworzone i „ujednolicone” w warstwie aplikacji zostają przekazane „niżej” do warstwy transportowej, czyli do innego protokołu (programu realizującego protokół). Najprościej biorąc, protokół warstwy transportowej rozpoczyna i kończy połączenie sieciowe. Dba też o to, by dane zostały podzielone na odpowiednio małe „paczki” i bardziej lub mniej stanowczo troszczy się o poprawny przekaz.
Także w warstwie transportowej można wykorzystać różne protokoły. Najpopularniejszy protokół tej warstwy to TCP (Transmission Control Protocol), który na bieżąco kontroluje, czy nie zaginęły jakieś „paczki danych”, a gdyby zaginęły, dba o ich ponowne przesłanie. Inny, też bardzo popularny protokół tej warstwy, to UDP (User Datagram Protocol), który jest niejako „jednokierunkowy”, bardziej podatny na błędy, nie wymaga bowiem ponownego przesyłania zaginionych „paczek”. Jeszcze inne, zdecydowanie mniej popularne protokoły warstwy transportowej, to DCCP, RSVP, SCTP, CUDP, RDP, SPX, SST.
Warstwa internetowa. Warstwa transportowa przekazuje „paczki danych uzupełnionych o informacje transportowe” do warstwy internetowej (międzysieciowej), gdzie wykorzystywany jest protokół IP (Internet Protocol). Ściślej jest to protokół w wersji IPv4 (nowszy, „zdecydowanie pojemniejszy” IPv6 jest pomału szykowany do wprowadzenia do powszechnego użytku). Inne skróty protokołów tej warstwy, jak ICMP czy IGMP, wskazują nie tyle na odrębne, inne protokoły, tylko na odmianę albo jakieś funkcje pomocnicze absolutnie dominującego protokołu IP.
Najprościej mówiąc, warstwa internetowa z protokołem IP zapewnia właściwe adresowanie „paczek danych” i między innymi dodaje do nich kolejne informacje dodatkowe, w tym adresy nadawcy i odbiorcy (co widać na rysunku 10).
Doszliśmy do bardzo ważnego szczegółu: adres IP w podstawowej postaci jest liczbą dwójkową trzydziestodwubitową, czyli czterobajtową w zakresie 00000000000000000000000000000000 do 11111111111111111111111111111111. W praktyce, dla ułatwienia, adres IP zapisujemy najczęściej w postaci czterech liczb dziesiętnych, rozdzielonych kropkami: x.x.x.x, gdzie x to liczba z zakresu 0…255. Jednak dla zrozumienia pewnych ważnych szczegółów trzeba czasem rozpisać go do postaci dwójkowej.
Może już wiesz, że każde urządzenie w sieci internetowej musi mieć indywidualny, niepowtarzalny adres – numer IP. Zapewne słyszałeś też, że brakuje adresów IP, ponieważ jest ich tylko nieco ponad 4 miliardy (232 = 4 294 967 296) i dostępna pula już jakiś czas temu została rozdzielona i wykorzystana. W zasadzie tak, ale to nie jest nasze zmartwienie.
Dobra wiadomość jest taka, że w małych sieciach lokalnych powszechnie wykorzystywane są adresy IP, od zawsze przydzielone nie do „dużego Internetu”, tylko dla niedużych sieci lokalnych. Mianowicie z reguły wykorzystuje się adresy, których dwie pierwsze liczby to 192.168.x.x. I tu trafna okazuje się analogia klasycznej telefonii: numery – adresy IP muszą być niepowtarzalne tylko w danej sieci lokalnej (lokalnej centrali). Numer – adres IP każdego urządzenia musi być niepowtarzalny w danej sieci lokalnej, np. Twojej sieci domowej, ale oczywiście może się powtórzyć w innej sieci lokalnej, choćby w domowej sieci Twojego sąsiada, a nawet w sieciach domowych wszystkich Twoich sąsiadów. O adresach internetowych, czyli adresach IP, będziemy jeszcze dużo mówić. A teraz wracamy do stosu.
Na pierwszy rzut oka, wszystko powinno być jasne. Najprościej biorąc, po przejściu przez linię transmisyjną i po dotarciu do odbiorcy przesyłana porcja informacji trafia do stosu protokołów, gdzie w kolejności odwrotnej niż przy nadawaniu, w kolejnych warstwach – protokołach, przetwarzane i ostatecznie usuwane są informacje dodatkowe kolejnych warstw. Finalnie u odbiorcy „na górze stosu” otrzymujemy zrekonstruowaną z kawałków, oryginalną informację.
A wcześniej przy wysyłaniu, oryginalne dane zostały „ustandaryzowane” (warstwa aplikacji), zostały też podzielone na „paczki” i uzupełnione o dodatkowe informacje zapewniające kontrolę transmisji, likwidację błędów (warstwa transportowa), a także odpowiednio zaadresowane (warstwa internetowa). I tu dochodzimy do niespodzianki: wydawałoby się, że już po przejściu przez warstwę internetową dane są kompletne, że nic im nie brakuje i że zawarte w nich zera i jedynki będą już teraz zamienione na przykład na impulsy napięcia, a potem przesłane choćby przez linię przewodową do urządzenia odbiorczego, którym jest drugi komputer. Wielu początkujących wyobraża sobie, że najniższa warstwa dostępu do sieci to opis sprzętu. Czasem nawet najniższa warstwa stosu jest nazywana warstwą fizyczną.
Niestety, tak dobrze nie jest!
Jeżeli chodzi o najniższą warstwę dostępu do sieci, to już jej nazwa jest dość tajemnicza, natomiast jej rola i działanie mogą mocno zaskoczyć.
Warstwa dostępu do sieci. Najniższa warstwa stosu TCP/IP to też warstwa zawierająca protokoły. Dane, wcześniej przygotowane w warstwie internetowej, są przekazywane do najniższej warstwy dostępu do sieci (ang. network access layer albo link layer). A tam… dodawane są kolejne informacje, co dopiero wtedy tworzy wreszcie porcję danych (zbiór zer i jedynek) gotową do przesłania przez linię transmisyjną, jak wskazują rysunki 9, 10. Najniższa warstwa omawianego czterowarstwowego stosu okazuje się zaskakująco skomplikowana, a pewne wykorzystane w niej koncepcje budzą zdziwienie, a nawet niedowierzanie. Czasem nazywana bywa warstwą fizyczną, a przynajmniej z warstwą fizyczną i ze sprzętem się kojarzy. Trzy wyższe warstwy stosu TCP/IP kojarzą się z procedurami, ogólnie z operacjami przetwarzania danych, wykonywanymi przez procesor komputera. Natomiast najniższa warstwa początkującym często kojarzy się z konkretnym fizycznym łączem. W zasadzie słusznie!
Ale po pierwsze ta najniższa warstwa stosu TC-IP to nie są ani „druciki” przekazujące impulsy prądu i napięcia, ani impulsy radiowe w sieci bezprzewodowej. Zgodnie z wcześniejszym opisem znów chodzi o jakiś protokół lub protokoły, czyli reguły i realizację tych reguł. Jednak sprawa się komplikuje. Owszem, w grę wchodzą protokoły, czyli zestawy reguł, opisujące działanie i parametry realnego, fizycznego łącza (wykorzystującego przewody albo promieniowanie elektromagnetyczne). Czyli protokoły określające wartości napięć, prądów, częstotliwości oraz długość i inne parametry impulsów. Tak, takie specyfikacje wchodzą w skład dolnej, czwartej warstwy, ale nie tylko one.
I tu dochodzimy do wiadomości, które dla wielu są zaskoczeniem.
Otóż okazuje się, dolna warstwa obejmuje też inne protokoły, których działanie w dużym stopniu przypomina, a wręcz dubluje, powtarza działanie protokołów warstwy drugiej (internetowej) i trzeciej (transportowej)! Wskazuje na to już rysunek 10, gdzie oprócz adresów IP z warstwy internetowej, mamy „inne adresy” – adresy MAC. „Zdublowane adresowanie” i inne szczegóły początkującym poważnie mącą obraz sprawy oraz budzą liczne pytania i wątpliwości. Co istotne, dotyczy to też małych sieci lokalnych, które są głównym obiektem naszego zainteresowania. Dlatego musimy przyjrzeć się tym kwestiom nieco dokładniej. Robimy to w następnym artykule (DR003).
Piotr Górecki