


Zrozumieć mikroprocesory i mikrokontrolery
W artykule przypomniana jest krótko historia mikroprocesorów. W skrócie przedstawione są zasady budowy i działania na przykładzie pierwszych popularnych mikroprocesorów, jakie pojawiły się na rynku. To, z czym mierzymy się dzisiaj jest konsekwencją zdarzeń jakie miały miejsce w historii.
Trochę historii
Niewiele jest wynalazków, które przyniosły wręcz rewolucyjne zmiany dla ludzi. Jednym z nich jest właśnie mikroprocesor. Jego historia zaczyna się w burzliwych latach 70. XX wieku. Pierwszym, jaki wszedł do powszechnego użytku jest i4004 (fotografia 1, z zasobów en.wikipedia.org) opracowany w firmie Intel – tak przynajmniej brzmi oficjalna wersja wydarzeń.

Fotografia 1
Historia, jak to historia, często ma dwie twarze: tę oficjalną (niekoniecznie prawdziwą) oraz tę prawdziwą, która często pozostaje w ukryciu. Podobnie było też w przypadku wynalezienia mikroprocesora. Istnieje wersja, że pierwszym był układ opracowany jeszcze w latach 60. na potrzeby armii Stanów Zjednoczonych i natychmiast został utajniony (nie był w powszechnym użyciu). Pozostaje kwestią punktu widzenia, co należy uznać za początek ery mikroprocesorów (każdy może to widzieć w odmienny sposób). Z jednej strony rozwiązania opracowane dla wojska fizycznie były wcześniejsze, jednak nie były ono dostępne dla ogółu. Patrząc z innej strony: układ Intela był dostępny dla każdego, jednak jego narodziny były późniejsze. W każdym razie spór o pierwszeństwo z punktu widzenia elektronicznego nie ma żadnego znaczenia. Jest ewentualnie dobrym tematem dla historyków lub spekulantów roztrząsających elementy teorii spisowych.
Powstanie pierwszego mikroprocesora ujawniło jego ogromny potencjał w rozwiązywaniu wielu problemów technicznych. Z dzisiejszej perspektywy ten procesor to bardzo prymitywne rozwiązanie. Pomijając fakt, że był 4-bitowy, to nie dysponował przykładowo funkcjonalnością określaną dzisiaj jako przerwania. To zostało wprowadzone do popularnych mikroprocesorów trochę później. Mówiąc o przerwaniach zaczynamy zahaczać o typowe pojęcia ze świata mikroprocesorów. Te nowe elementy w wielu przypadkach powinny być zrozumiałe, wystarczy użyć własnej intuicji i skojarzeń. Niektóre z nich wymagają już pewnych wyjaśnień. Postaram się przybliżyć te zagadnienia, ilustrując niektóre przykładami.
Co to jest mikroprocesor
Właściwie należy zacząć od definicji mikroprocesora. Często odniesieniu do niego używa się skrótu CPU (ang. Central Processing Unit), co tłumaczy się jako „centralna jednostka obliczeniowa”, czasami używa się też skrótu MPU (ang. Micro-Processing Unit). Z punktu widzenia teorii układów cyfrowych mikroprocesor to bardzo wielostanowy automat synchroniczny. Sądzę, że ta definicja niewiele wniosła. Sam „automat” jest raczej intuicyjnie zrozumiały – to urządzenie, które samo wykonuje coś w jakimś cyklu. W teorii układów logicznych automatem jest rejestr (rejestrem jest coś, co pamięta, przechowuje informację, można go zbudować z przerzutników), który przechowuje swój stan. Przykładowo w rejestrze 4-bitowym może zapisać jedną z 16 możliwych kombinacji. Korzystając z takiego rejestru można zbudować automat 16-stanowy. Obok automatu wystąpiło słowo „synchroniczny”. Oznacza ono, że coś się zmienia (w tym automacie) w sposób zsynchronizowany z czymś innym. Tym czymś jest sygnał taktujący, sygnał zegarowy – ciąg impulsów o określonej częstotliwości, które determinują zachodzące w automacie zmiany. Skoro mikroprocesor zmienia swój stan zgodnie z sygnałem taktującym, a każda jego „czynność” wymaga określonej liczby taktów zegarowych – to częstotliwość taktująca wpływa na prędkość jego pracy. Im większa częstotliwość sygnału zegarowego, tym mikroprocesor szybciej wykonuje swoje działania. Nie można zwiększać jej dowolnie, gdyż każdy ma swoje ograniczenia (w dokumentacji jest podawana maksymalna częstotliwość sygnału zegarowego). Takim odpowiednikiem rejestru stanu automatu w mikroprocesorach jest rejestr nazwany licznikiem rozkazów PC (ang. Program Counter). Jest to rejestr (rysunek 2), który określa w jakim stanie jest mikroprocesor, czyli gdzie znajduje się aktualnie realizacja zadanego programu.
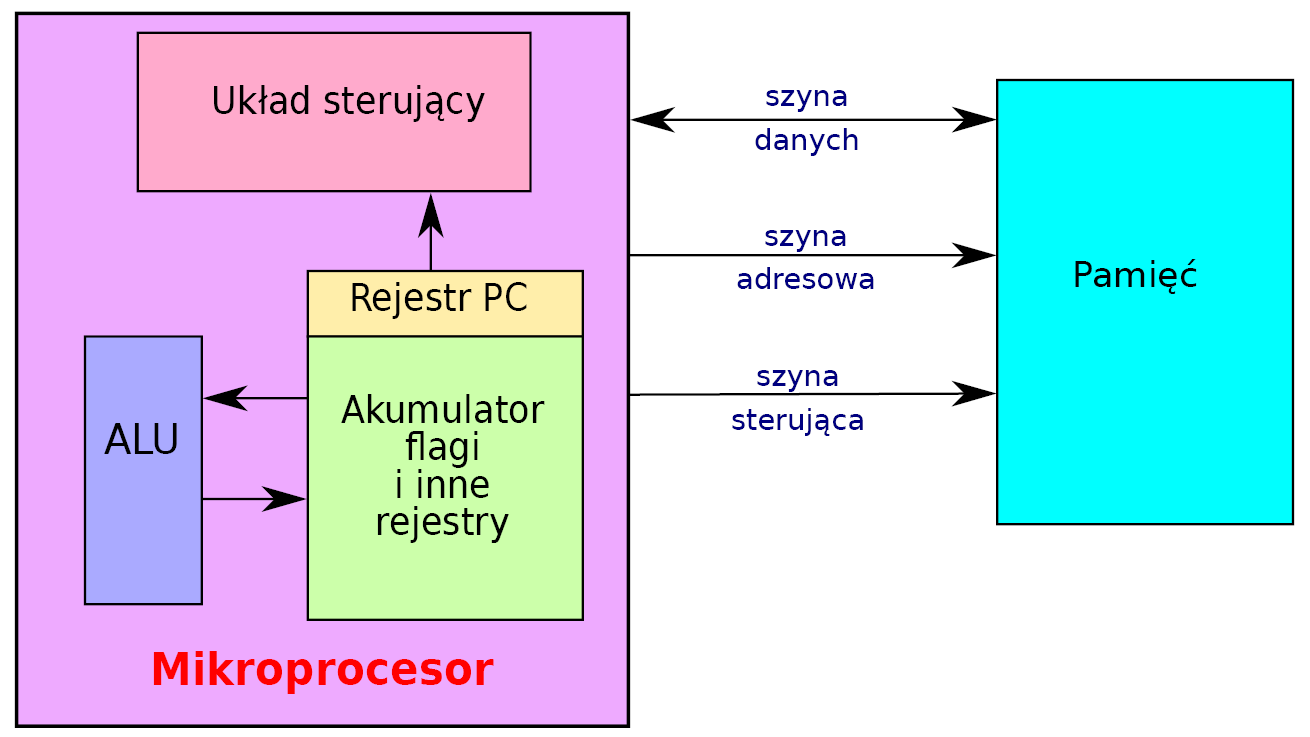
Rysunek 2
Stan tego rejestru można interpretować jako liczbę określaną jako adres – numer komórki w pamięci, gdzie aktualnie znajduje się realizacja programu, jak pokazuje rysunek 3.
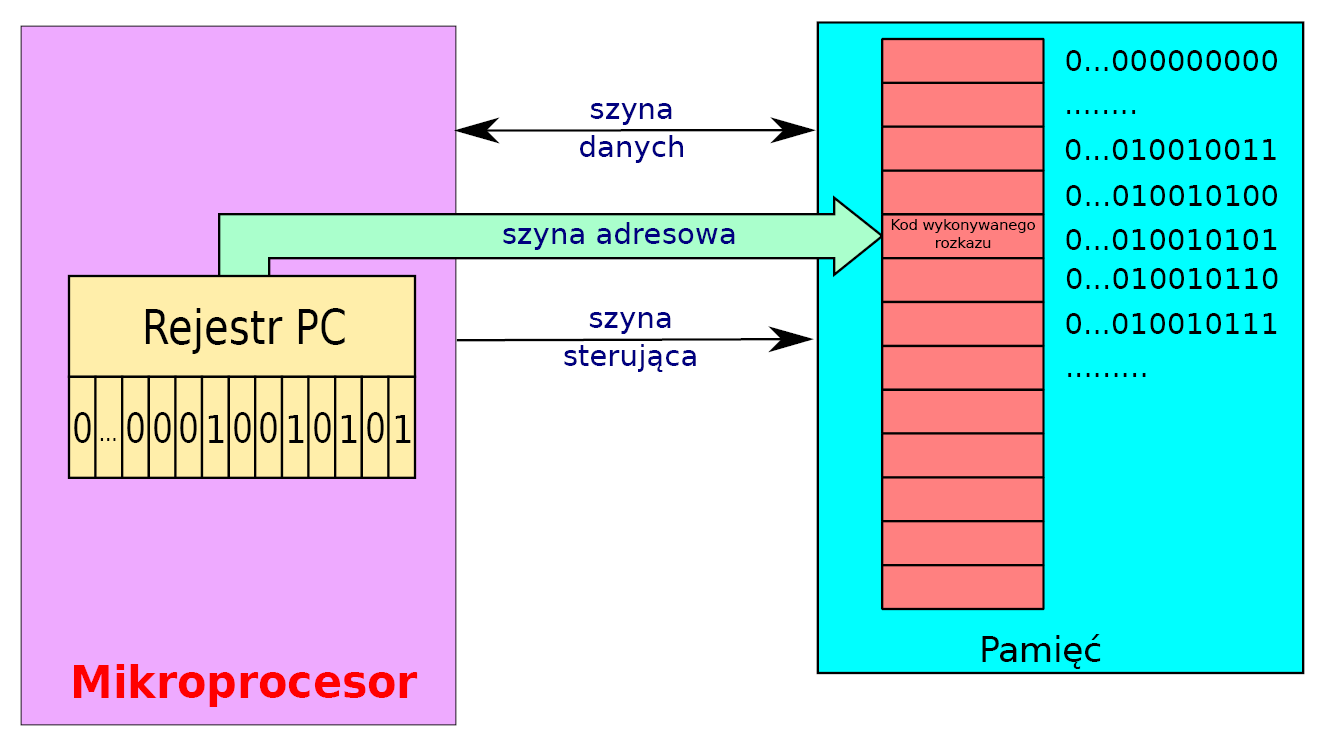
Rysunek 3
Adres w programie
Na ilustracji tej w rejestrze PC zapisany jest jakiś ciąg zer i jedynek. Odpowiada to oczywiście pewnej wielocyfrowej liczbie binarnej (binarnej – zbudowanej na bazie dwóch cyfr: zera i jedynki). Obowiązuje tu dokładnie ta sama idea, do jakiej jesteśmy przyzwyczajeni w codziennym świecie liczb dziesiętnych. Można przekształcić liczbę binarną i określić jej wartość. Ideę konwersji jako operacji zapisu danych do rejestru pokazuje rysunek 4.
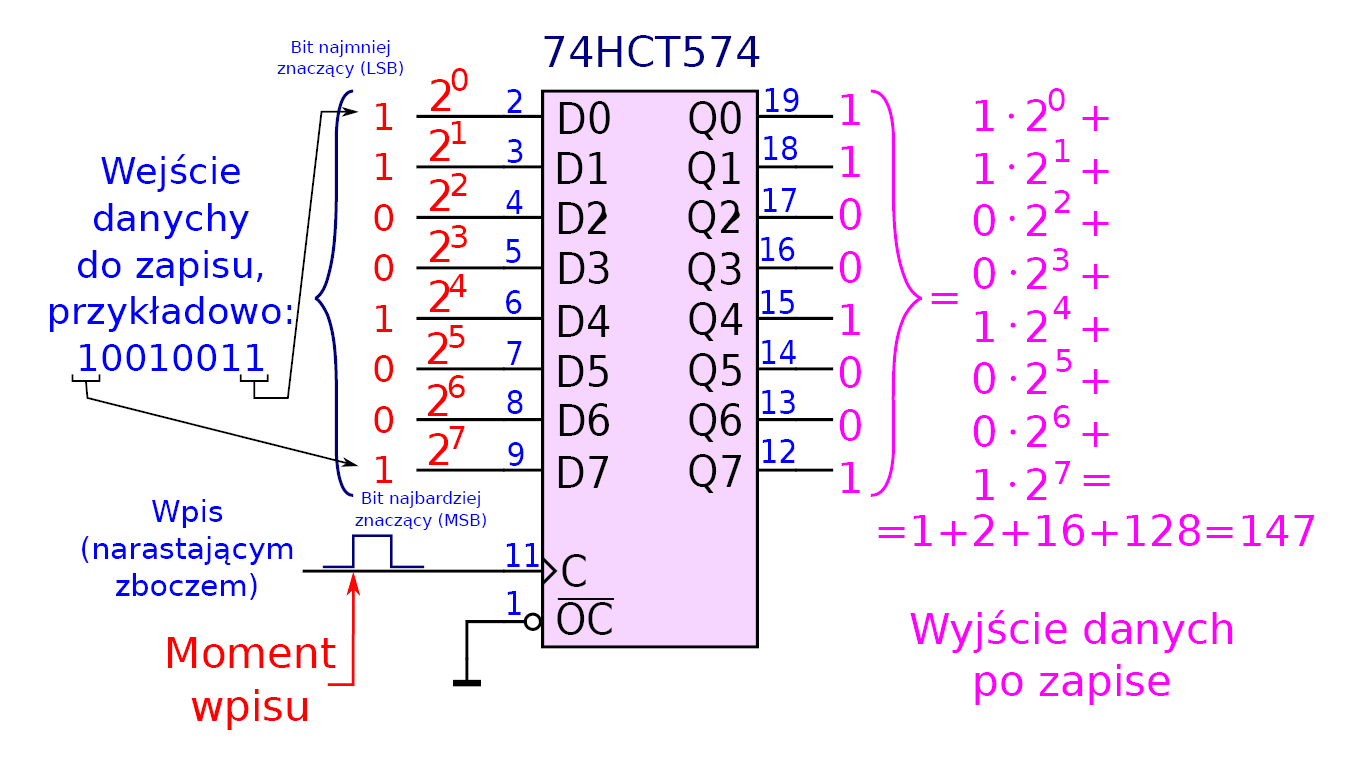
Rysunek 4
Program jako kod binarny
Wystąpiło tu kolejne nowe pojęcie: program. Jest to ciąg czynności jakie są przewidziane dla danego mikroprocesora do osiągnięcia określonego celu. Realizuje on je w sposób sekwencyjny, jedna po drugiej w ściśle określonej kolejności, a licznik rozkazów pokazuje położenie aktualnie wykonywanej operacji w całym programie (rysunek 3). Te polecenia, przeznaczone dla określonego mikroprocesora, są reprezentowane przez pewne kody tworzące program binarny (każda czynność, operacja to inny kod). Sformułowanie „binarny” doskonale określa ten program – jest to ciąg zer i jedynek i ma niewiele wspólnego z tym co napisał programista. Programista (czyli człowiek) posługuje się językiem programowania. Jest kilka języków niezależnych od modelu mikroprocesora (jak przykładowo język C) i jest język ściśle dedykowany dla danego mikroprocesora. Taki jest określany jako assembler danego mikroprocesora – podstawowy język jego programowania. Program stworzony przez człowieka nazywa się programem źródłowym. To co napisał człowiek (program źródłowy) jest absolutnie niezrozumiałe dla procesora. To co realizuje mikroprocesor (program binarny) jest raczej mało czytelne dla człowieka. Można powiedzieć, że na styku człowiek – mikroprocesor zawsze występuje problem „dogadania się”, gdyż każda ze stron posługuje się innym dialektem. By wszystko harmonijnie współgrało, niezbędna jest dodatkowa pomoc elementów trzecich. Tu na scenę wkracza kolejny element – kompilator w parze z linkerem jako programy narzędziowe najczęściej skrośne (przygotowujące program binarny na „obcy” procesor, kompilator uruchomiony przykładowo w komputerze PC [procesor z rodziny x86], generujący kod dla procesora MC6800 [Motorola]).
Zadaniem kompilatora jest przetłumaczenie jednego dialektu (program źródłowy) na język zrozumiały dla mikroprocesora (program binarny).Koncepcję pokazuje rysunek 5 dla mikroprocesora Z80 (Zilog, fotografia 6).
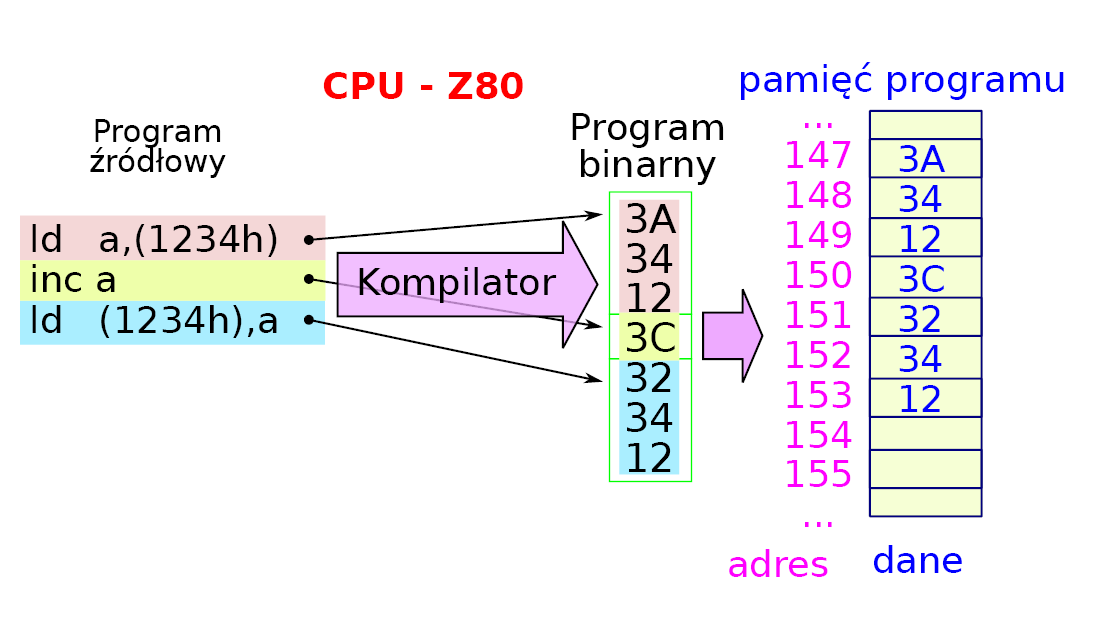
Rysunek 5

Fotografia 6
Program zwiększa tu o jeden zawartość komórki pamięci o adresie 1234 hex i składa się z operacji przesłania zawartości komórki pamięci do akumulatora, zwiększenia stanu akumulatora i przesłania wyniku do pamięci pod ten sam adres. Można dostrzec, że niektóre rozkazy zajmują 1 bajt w pamięci, inne muszą mieć więcej miejsca.
Właściwie to za utworzenie programu binarnego odpowiedzialny jest linker (program łączący). Często program źródłowy występuje w kilku „kawałkach”, które można niezależnie kompilować. Poza tym w grę wchodzą różne dodatkowe biblioteki. Zadaniem linkera jest zebranie wszystkich w jednym miejscu i połączenie w jedną całość – program binarny. Taki program (wyprodukowany przez linker) ma określoną wielkość (jako określoną liczbę poleceń do wykonania). Naturalnym jest, że wielkość programu nie może przekraczać maksymalnej wielkości przestrzeni adresowej mikroprocesora.
Architektury mikroprocesorów i mikrokontrolerów
Z przestrzenią adresową wiąże się kolejne pojęcie dotyczące architektury mikroprocesora: architektura von Neumanna albo architektura harwardzka.
W pierwszym przypadku przestrzeń adresowa jest przeznaczona na program i dane łącznie (rysunek 7). Jednostka sterująca pobiera z pamięci kod operacji do wykonania, gdzie ALU dokonuje obliczeń i wynik zapisuje do tej samej pamięci (przestrzeni adresowej). Nie można arbitralnie określić, która część pamięci jest przeznaczona do przechowywania kodu programu, a która przechowuje wyniki obliczeń. Możliwa jest nawet automodyfikacja programu, program może sam się zmodyfikować lub wykonać program „z danych”. Wręcz klasycznym przypadkiem jest załadowanie (z dowolnego nośnika zewnętrznego) kodu programu i wykonanie go tak, jak robią to typowe komputery. Z punktu widzenia programu ładującego (jakiegoś fragmentu systemu operacyjnego) ładowany program stanowi dane. Po zakończeniu ładowania możliwe jest jego uruchomienie (potraktowanie umieszczonych w pamięci danych jako ciągu poleceń do wykonania – wszystko jest kwestią interpretacji).
Rysunek 7
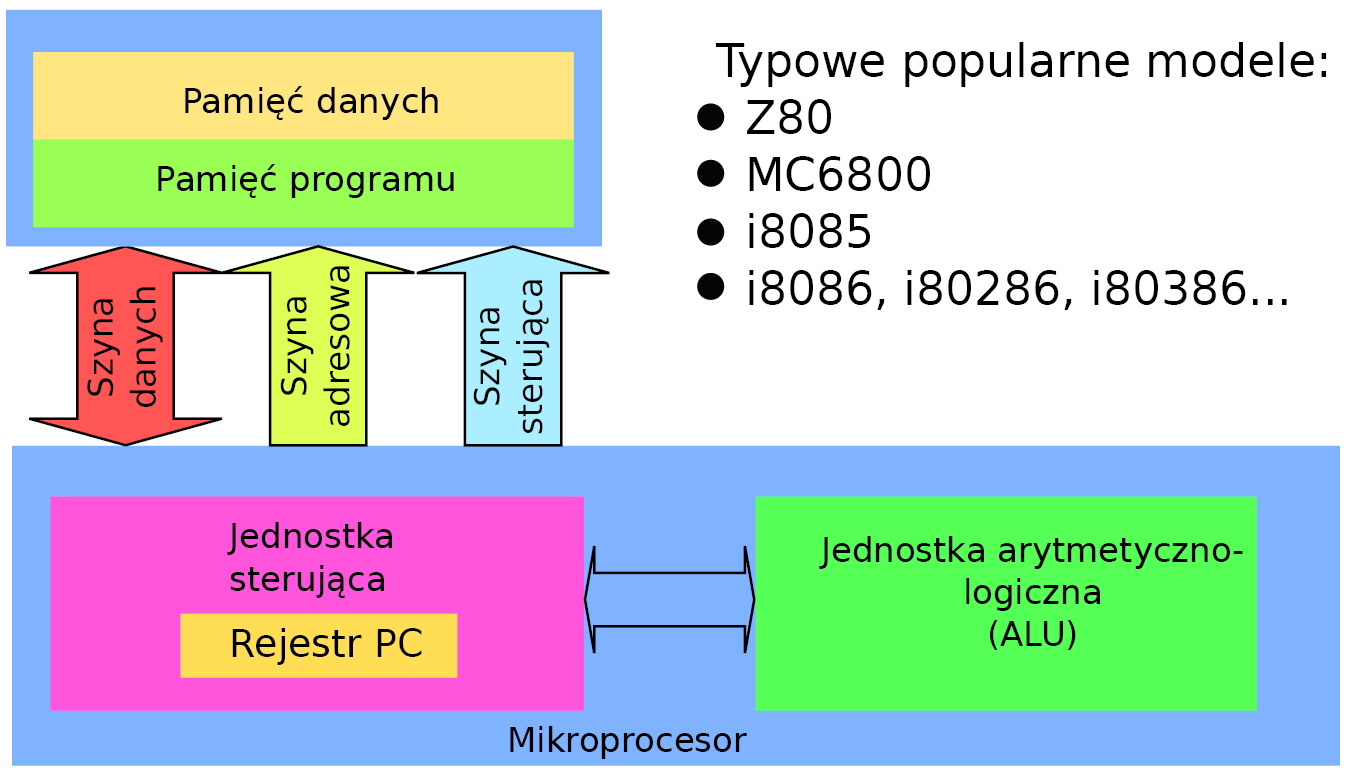
W architekturze harwardzkiej program oraz dane znajdują się w oddzielnych przestrzeniach (technicznie rozdzielonych). Pierwsze mikroprocesory bazowały na architekturze von Neumana. Jest to najprostsze rozwiązanie. Jeden układ elektroniczny realizuje każdy dostęp do pamięci. To może być zapis/odczyt danych lub odczyt kodu polecenia do wykonania. Rosnące zapotrzebowanie na moc obliczeniową mikroprocesorów doprowadziło do alternatywnego rozwiązania organizacji przestrzeni adresowych – architektura harwardzka (rysunek 8). Pozwala to na zwiększenie efektywności, gdyż przykładowo podczas zapisywania danych do pamięci (jako wynik operacji) przez jeden układ elektroniczny jednocześnie inny układ elektroniczny może pobierać z przestrzeni programu kolejny kod rozkazu do wykonania. Z punktu widzenia mikroprocesora pamięć danych tak jak i pamięć programu należy traktować jako elementy niezależne i zewnętrzne. Taki „wielodostęp” jest raczej domeną mikrokontrolerów, gdyż wymaga zdublowania szyny danych, szyny adresowej i szyny sterowań. Mikrokontroler jako element integrujący w jednej strukturze półprzewodnikowej mikroprocesor, pamięć, porty i inne podzespoły nie ma ograniczeń na liczbę „nóżek” między tymi elementami. Ten sam skład funkcjonalny podzielony na niezależne układy scalone wymaga stworzenia możliwości połączeń między nimi.
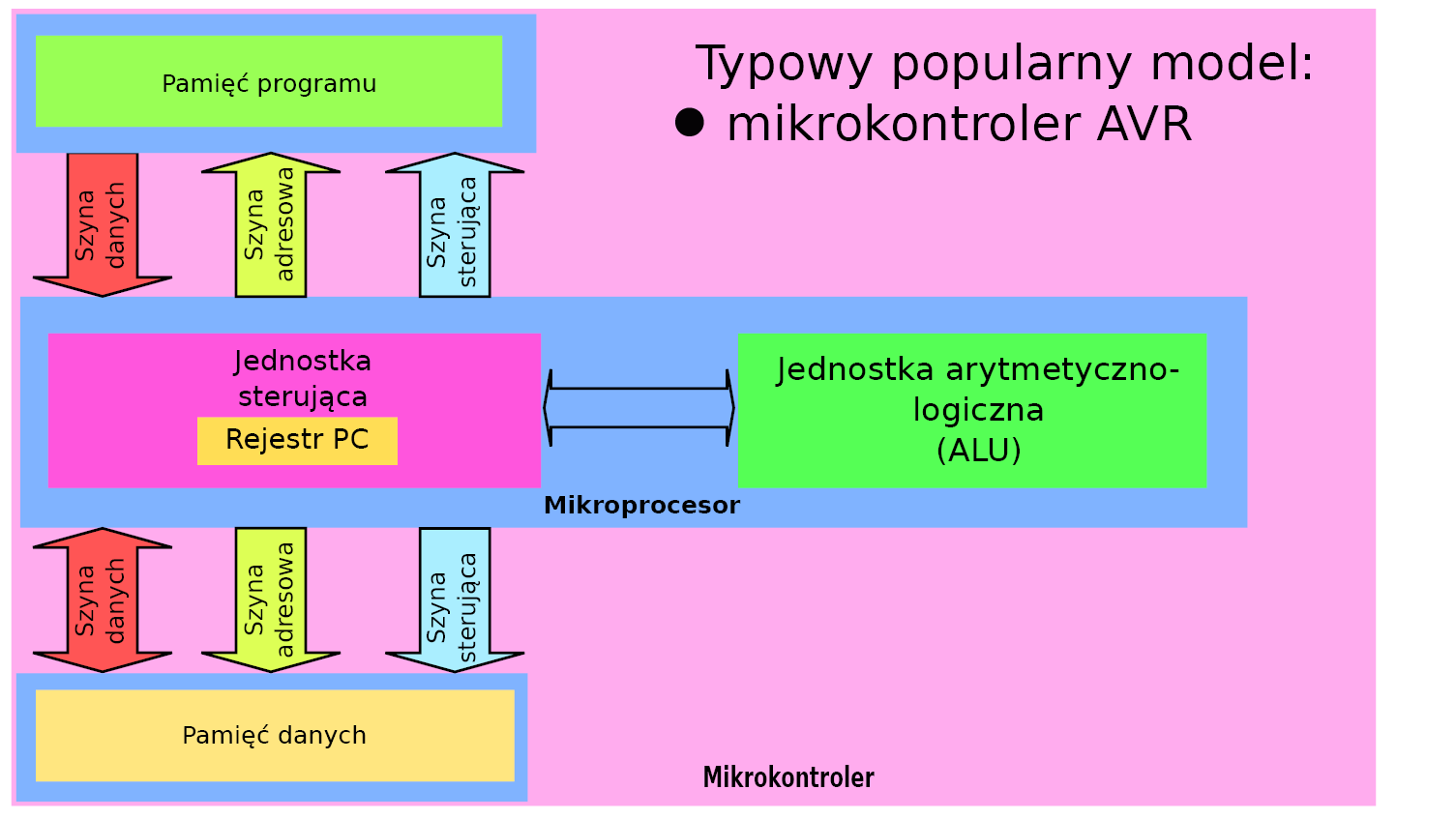
Rysunek 8
Cechą charakterystyczną architektury harwardzkiej jest brak możliwości automodyfikacji kodu programu. Przestrzeń programu jest tylko do odczytu (lista instrukcji procesora zawiera jedynie możliwość odczytu komórek z tej przestrzeni). Dodatkową implikacją tego faktu jest pewna komplikacja w programie, gdyż człowiek (programista) musi wyraźnie zaznaczyć w nim swoje zamiary. Kompilatory języków niezależnych od mikroprocesorów (jak przykładowo C) filozoficznie są przywiązane do architektury von Neumanna i „nie rozumieją”, że istnieją inne wymiary przestrzeni adresowych. Realizując dostęp do komórek pamięci zawsze mają na uwadze jedną przestrzeń adresową. Natomiast w językach typu assembler nie zachodzi konieczność „zmuszania” kompilatora do ściśle określonych zachowań. Te języki „oferują sformułowania” pozwalające rozróżnić, czy chodzi o pamięć programu, czy pamięć danych niemniej nadal programista musi świadomie wybrać właściwy wariant.
Oprócz wymienionych wariantów architektury został wypracowany kolejny, łączący cechy obu wyżej wymienionych. Ta architektura jest określana jako mieszana (rysunek 9).
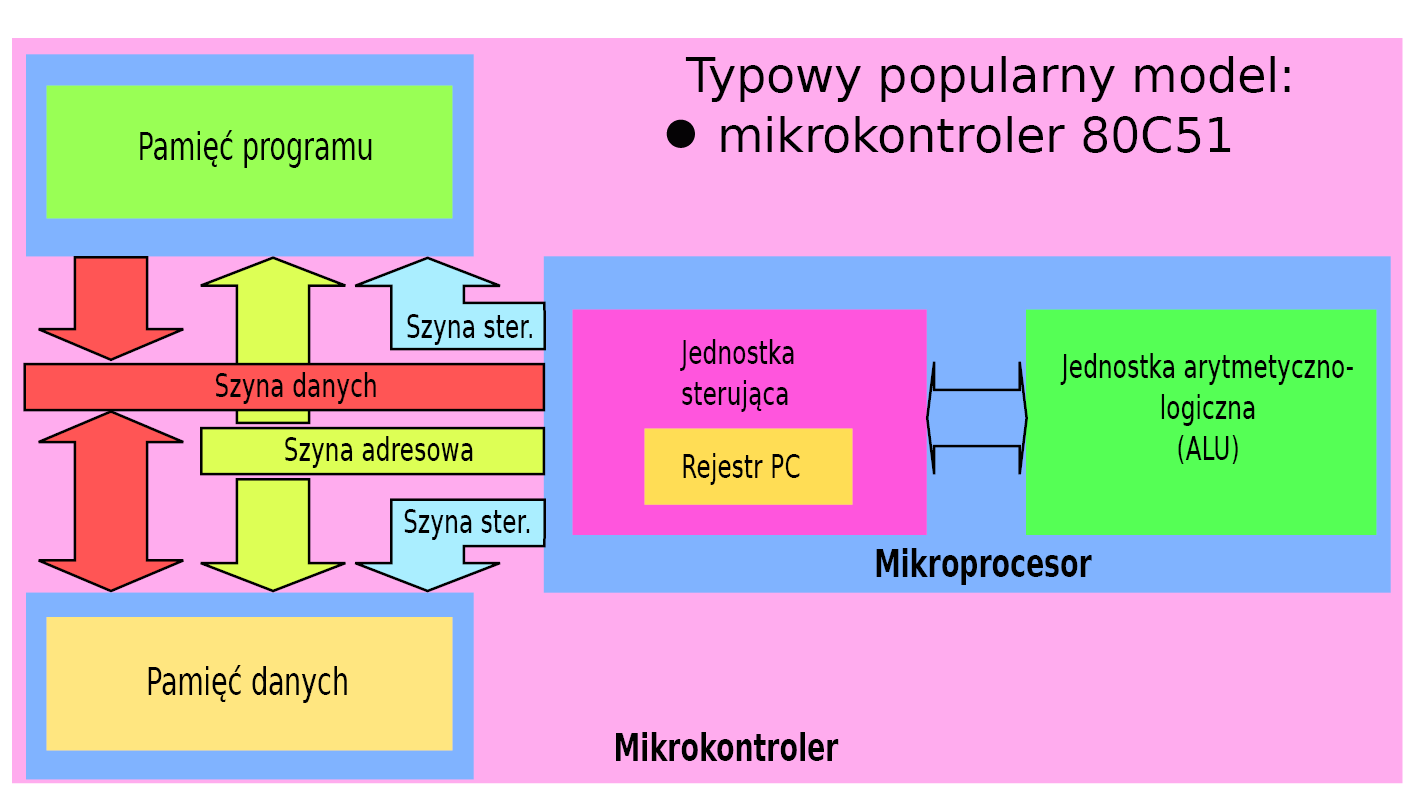
Rysunek 9
Łączy podwójną przestrzeń adresową, a jednocześnie używa jednej szyny adresowej i szyny danych. Szyna sterowań jest rozdzielona, gdyż układy obsługi pamięci (na zewnątrz mikroprocesora) muszą „wiedzieć” czy wystawiony na właściwej szynie adres odnosi się do pamięci programu czy pamięci danych. Typowym przedstawicielem takiego rozwiązania są mikrokontrolery z rodziny C51.
Andrzej Pawluczuk
apawluczuk@vp.pl



