


Mikroprocesorowa ośla łączka, część 6
Manipulowanie pinami portów to jedno z podstawowych działań w mikrokontrolerach, gdyż trudno sobie wyobrazić program, który nie realizuje interakcji z otoczeniem zarówno w sensie wejścia jak i wyjścia. Czas wejść w tematykę głębiej i… elastyczniej.
Kolejna część cyklu jest nadal poświęcona operacjom dotyczącym manipulowaniem wyprowadzeniami portów mikrokontrolera. Tym razem zaistnieją operacje odczytu pinów, czyli w rzeczywistości odczytamy informacje, jakie ma nam do przekazania otoczenie mikrokontrolera. To może być przycisk lub zespół przycisków udający klawiaturę czy jakiś układ cyfrowy/logiczny przyłączony do mikrokontrolera. Dodatkowo zaczniemy używać zmiennych w programie – to nowy i ogromnie istotny element programowania.
Zmienne w programie
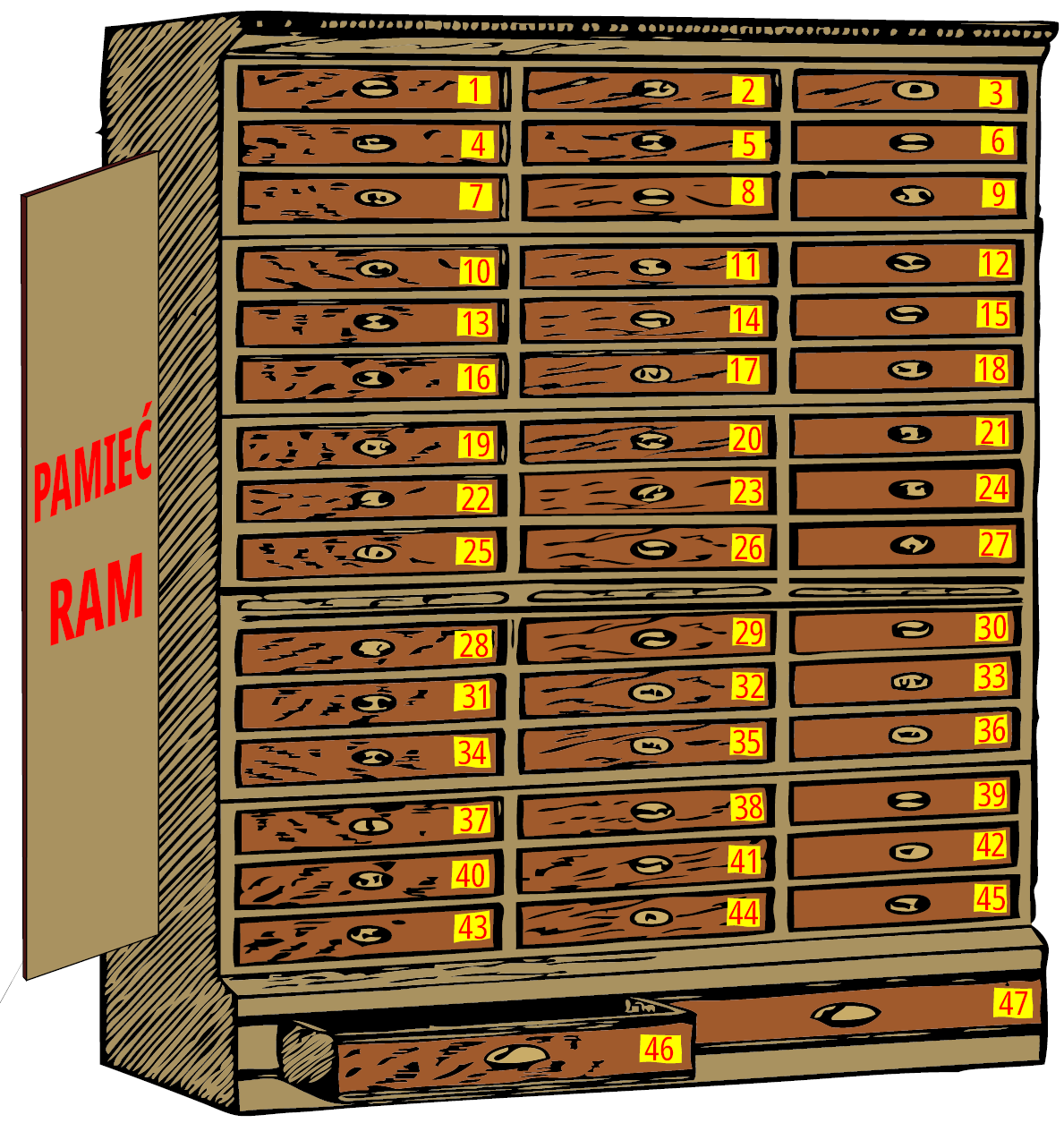
Zmienne w programie to są komórki lokowane w pamięci RAM (wewnętrzny element mikrokontrolera) przeznaczone do szeroko pojętego przechowywania informacji roboczych. Określenie RAM (ang. Random Access Memory) oznacza pamięć o dostępie swobodnym, jest to jej charakterystyczna cecha pozwalająca na szybki dostęp do odpowiedniej komórki. Jest całe mnóstwo rodzajów pamięci (jak choćby pamięć o dostępie szeregowym), jednak obecnie nie będziemy się nimi zajmować, interesuje nas jedynie wewnętrzna pamięć RAM. W dokumentacji do używanego mikrokontrolera można znaleźć informację, że ma on ponad 2000 bajtów pamięci RAM (bajtów, czyli komórek mogących przechowywać dane 8-bitowe). Aby je rozróżniać, mikrokontroler posługuje się dodatkową informacją określaną jako adres. Żeby w pełni zrozumieć istotę pamięci posłużę się pewną analogią. Wyobraźmy sobie komodę z dużą liczbą szufladek – taką, jak na rysunku 1.
Rysunek 1
Jak wspomniałem wyżej, mikrokontroler ma ich ponad 2000, na rysunku widać małe kilkadziesiąt. Każda z tych szufladek zawiera kartkę, na której można zapisać ołówkiem ośmiobitową informację. Po otwarciu odpowiedniej szufladki jest możliwość „poznania”, co jest zapisane na kartce. Jest to operacja odczytu danych. Analogicznie istnieje możliwość zapisu informacji. Po otwarciu odpowiedniej szuflady oraz posiłkując się gumką należy usunąć to, co jest tam zapisane i ołówkiem w to miejsce wpisać nowe dane. Zapis nowych danych całkowicie usuwa stare.
Użyłem tu określenie „odpowiednią szufladkę”. Aby je jednoznacznie identyfikować, szufladki mają przymocowane numerki (każda ma inny). Sięgając do konkretnej szufladki, trzeba znać jej numerek. W oprogramowaniu jest dokładnie tak samo: szufladki (komórki pamięci) są identyfikowane przez swój numerek – adres komórki w przestrzeni pamięci. Te numerki (adresy komórek) są z góry ustalone – rzemieślnik, który wykonał komodę przybił do każdej szufladki blaszkę z jej unikalnym numerkiem. Podobnie, w procesie produkcji mikrokontrolera, jego elektroniczne rozwiązania będą zawsze identyfikować komórki pamięci bazując na jej adresie: wielobitowej unikalnej informacji przydzielonej każdej komórce. W przypadku ATMEGA328 mającej 2 kB pamięci RAM ten adres składa się z 11 bitów.
Tu może zrodzić się dosyć istotne pytanie: skąd wiadomo, co jest w jakiej komórce?
W trakcie całego procesu generowania programu binarnego, programy wchodzące w skład Atmel Studio analizując nasz program źródłowy dostrzegają zapisy deklarujące zmienne w programie. Każda zmienna jest identyfikowana przez swoją nazwę (siłą rzeczy nazwa musi być unikalna, aby identyfikacja była jednoznaczna). To powoduje, że oprogramowanie rezerwuje w przestrzeni pamięci RAM miejsce (o odpowiedniej wielkości) na daną zmienną, przykładowo jako pierwsze wolne miejsce z puli pamięci RAM. Z tej rezerwacji wynika jej adres, a wskazanie na początek puli wolnych miejsc jest przesunięte o wielkość zarezerwowanego obszaru. Każde odwołanie w dowolnym miejscu programu do zmiennej (poprzez jej unikalną nazwę) powoduje, że kompilator wygeneruje rozkazy odczytu/zapisu do pamięci RAM, posiłkując się jej adresem przydzielonym na etapie rezerwacji.
Jednocyfrowy siedmiosegmentowy wyświetlacz LED
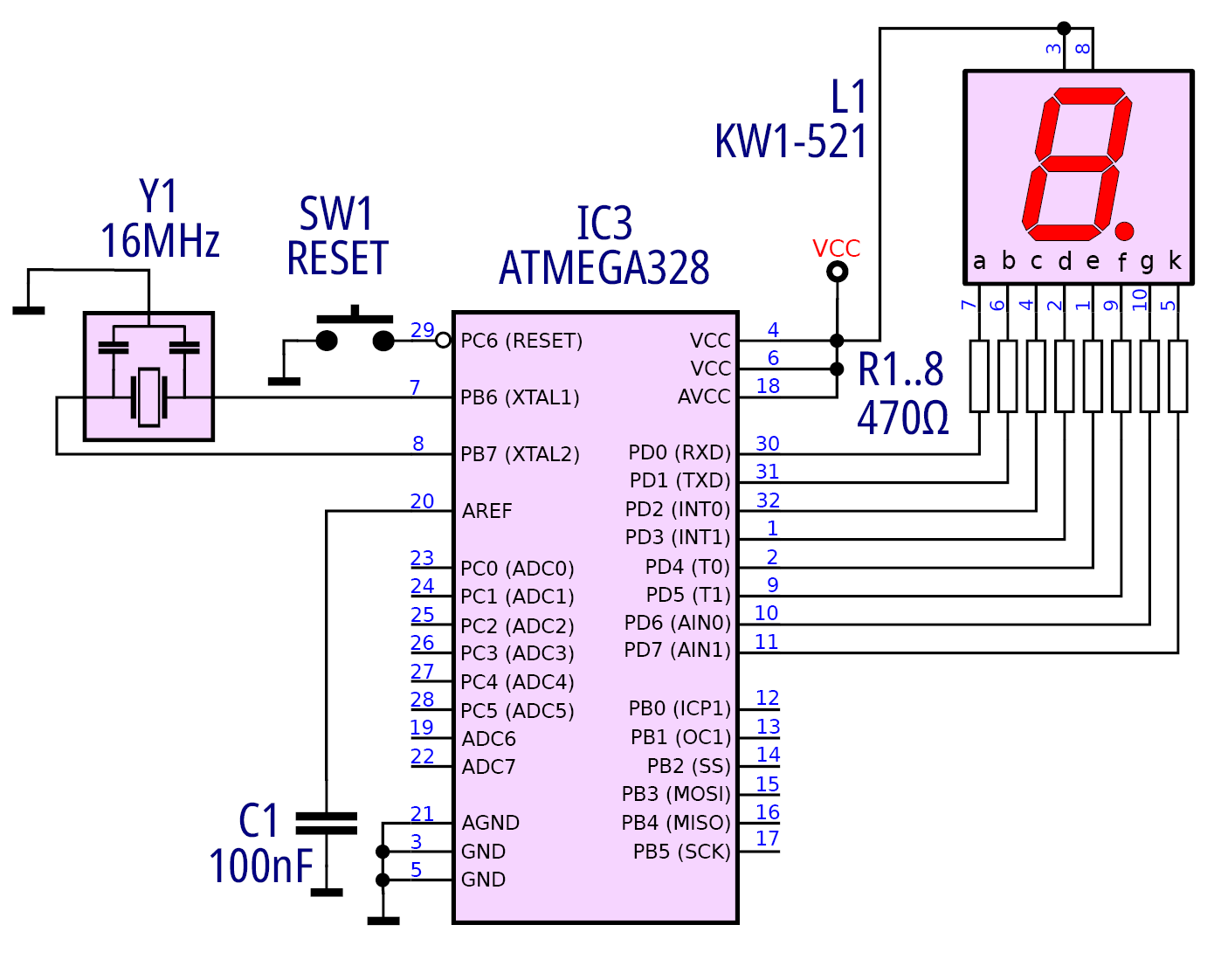
Zbudujemy układ do obsługi klasycznego 7-segmentowego wyświetlacza LED (na razie składającego się z jednej cyfry). Z punktu widzenia elektronicznego (i ograniczając się do istotnych szczegółów), schemat rozwiązania pokazuje rysunek 2.
Rysunek 2
Do prostego sterowania wyświetlaczem wymaganych jest osiem pinów (zajmie cały port): siedem segmentów cyfry oraz segment kropki. Może to być dowolny wyświetlacz o wspólnej anodzie (przyłączony do napięcia zasilającego: +5 V) z wyprowadzonymi wszystkimi segmentami, które poprzez szeregowo włączone rezystory o wartości 470 Ω są przyłączone do wyprowadzeń PORTD. Wartość ich rezystancji nie jest krytyczna, ale nie powinna być mniejsza od 220 Ω (będzie zbytnio obciążać wyjścia portu) oraz nie większa niż 1 kΩ (będzie słabo świecić). Dla ułatwienia zbudowania niezbędnego środowiska do testów, sposób połączenia modułu z wyświetlaczem jest przedstawiony na rysunku 3.
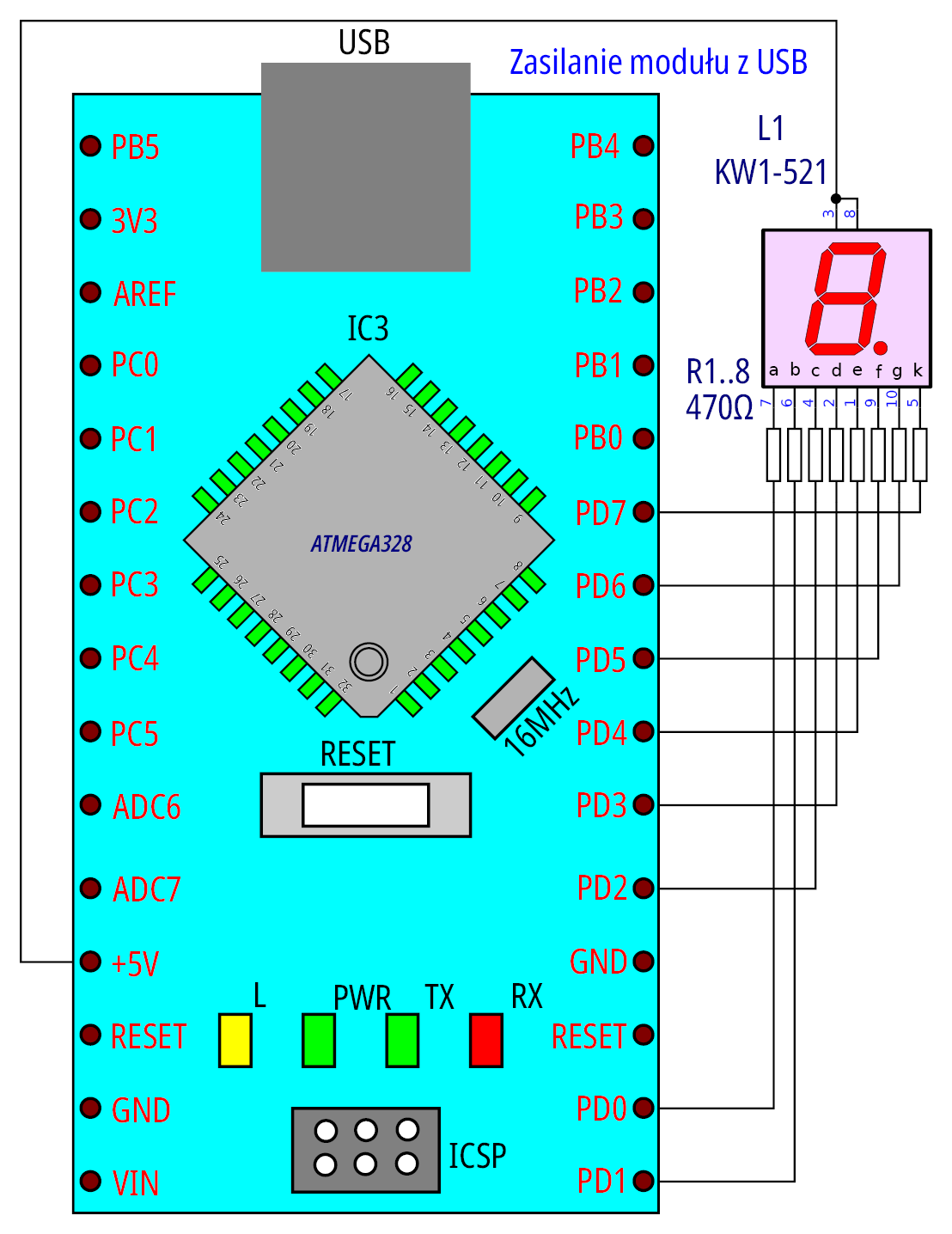
Rysunek 3
W pierwszym wariancie niech program pokazuje dane przechowywane w zmiennej (o nazwie Counter) zwiększanej w każdym obrocie pętli o jeden. Aby całość nie zadziałała „zbyt szybko”, w programie wykorzystane są znane z poprzedniej części funkcje do generowania opóźnień. Program pokazuje listing 1:
#define F_CPU 16000000UL
#include <avr/io.h>
#include <util/delay.h>
#define DisplayPort PORTD
#define DisplayConfig DDRD
uint8_t Counter ;
void Setup ( void )
{
Counter = 0 ;
DisplayCofig = 0xFF ;
DisplayPort = 0xFF ;
}
void Loop ( void )
{
_delay_ms ( 1000 ) ;
Counter ++ ;
DisplayPort = Counter ;
}
int main ( void )
{
Setup ( ) ;
while ( 1 )
Loop ( ) ;
}
Dla uzyskania większej elastyczności port obsługujący wyświetlacz jest parametryzowany przez #define DisplayPort, jak również port określający kierunek pracy #define DisplayConfig. Tym razem cały program jest napisany w „konwencji” Arduino, czyli w funkcji main jest wywołana jednorazowo funkcja Setup oraz dalej w nieskończonej pętli wywoływana funkcja Loop. Obie funkcje są bezparametrowe. Wywołanie funkcji to przejście z wykonywaniem programu do wskazanego miejsca (identyfikowanego przez nazwę), wykonanie tam występujących instrukcji aż do napotkania nawiasu zamykającego funkcję i powrót za miejsce wywołania. W identyczny sposób wywoływana jest druga funkcja, z tym, że ta operacja jest cykliczna. Schematycznie prezentuje to rysunek 4.
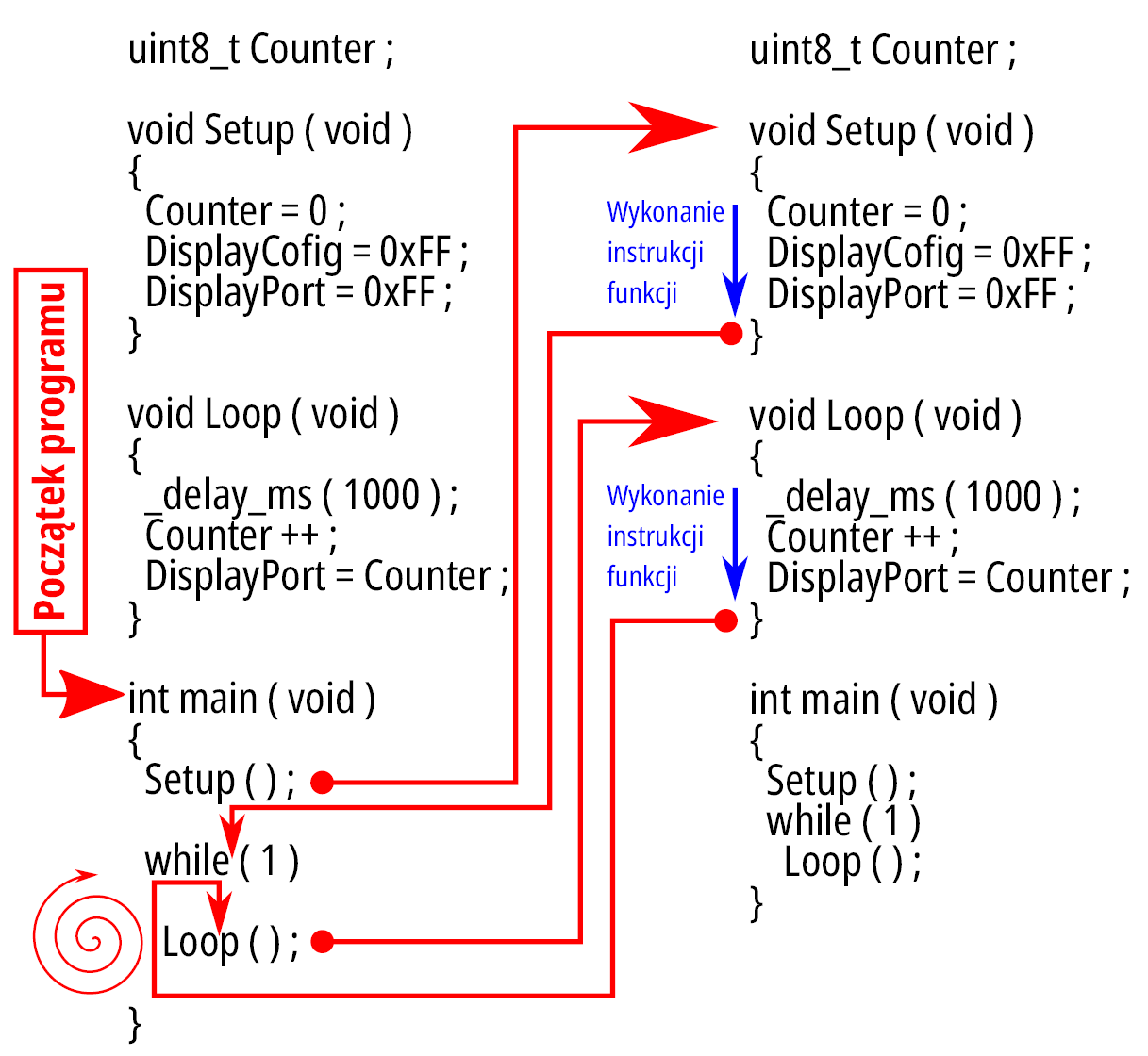
Rysunek 4
W tym programie wystąpiły dwa nowe elementy: utworzenie zmiennej (poprzez zapis uint8_t Counter) o nazwie Counter, która jest typu uint8_t. W ogólnym przypadku zapis pokazuje listing 2:
<identyfikator typu> <nazwa zmiennej>, <nazwa zmiennej>, … , <nazwa zmiennej>;
<identyfikator typu> określa wszystkie szczegóły związane ze „sposobem widzenia” zmiennej (zajętości miejsca w pamięci, sposobu traktowania jej wartości). Przykładem takiego identyfikatora typu jest uint8_t. Zmienna tego typu zajmuje w przestrzeni pamięci RAM jeden bajt i może przyjmować wartości całkowite z przedziału od 0 do 255 włącznie (liczby całkowite bez znaku). Odmianą tego typu jest int8_t (bez literki „u” na początku) jako liczby całkowite ze znakiem (dodatnie jak i ujemne). Zmienne tego typu zajmują w pamięci również jeden bajt, z tym, że mogą przyjmować wartości –128…+127 (również 256 możliwych kombinacji: 128 liczb ujemnych, jedno zero oraz 127 liczb dodatnich – łącznie 256 możliwych kombinacji). Z innymi typami zmiennych zapoznamy się przy kolejnych programach. Za identyfikatorem typu występuje lista nazw zmiennych rozdzielonych znakiem przecinka oraz na samym końcu znak średnika (jak kropka na końcu zdania). Lista zmiennych może składać się z jednego elementu (wtedy bez znaku przecinka, bo lista jest jednoelementowa).
Drugim nowym elementem jest instrukcja Counter ++ ; (w ogólnym przypadku <nazwa zmiennej> ++ ;). Instrukcja ta oznacza zwiększenie zawartości komórki pamięci identyfikowanej przez <nazwa zmiennej> o jeden. Dokładnie identyczne działanie uzyskamy zapisując: Counter +=1 ; lub Counter = Counter + 1 ;. Posługiwanie się odpowiednim wariantem należy postrzegać w kategorii własnych upodobań, działanie w każdym przypadku jest identyczne.
Tu może zrodzić się pewne pytanie o charakterze „filozoficznym”, a mianowicie: jaki jest stan początkowy zmiennej. Włączenie zasilania generuje przypadkową zawartość pamięci (sygnał zerowania Reset, generowany po włączeniu zasilania ustawia odpowiednie stany dla rejestrów mikrokontrolera – pamiętamy, że przykładowo porty inicjują się jako wejścia), ale nie dotyczy to pamięci RAM. W przypadku zmiennych (komórek lokowanych w przestrzeni RAM) niektóre są zerowane (przez program w fazie startowej – nie jest to nasza funkcja Setup) inne już nie (obecnie sygnalizuję jedynie taką problematykę, o której będzie więcej później). Nigdy nie zaszkodzi wyzerowanie zmiennej (poprzez wpisanie do zmiennej liczby zero), jej stan początkowy jest często bardzo istotny. Taka operacja jest wykonana w funkcji Setup (Counter = 0 ; listing 1), jak również ustalenie, że port, który obsługuje wyświetlacz jest portem wyjściowym, oraz na jego wyjściach wystąpią jedynki logiczne. Analizując schemat (rysunek 2), łatwo zauważyć, że segment wyświetlacza nie świeci, jeżeli na wyjściu odpowiedniego pinu jest stan wysoki.
Działanie programu (cykliczne wywołanie funkcji Loop, listing 1) sprowadza się do „zatrzymania” programu na jedną sekundę, następnie zwiększenia zawartości zmiennej o jeden i przesłania jej do portu (do wysterowania wyświetlaczem). Zmienna występująca w programie jest ośmiobitowa bez znaku, toteż po osiągnięciu stanu 255 (maksymalna liczba do zapisania na ośmiu bitach) sama przejdzie do stanu zera (programiści mówią, że zmienna się przekręciła).
Pozostało skompilować program i załadować uzyskany kod do pamięci Flash mikrokontrolera. Tu czeka nas pewna niespodzianka, program działa inaczej, niż nam się wydawało (jednak zgodnie z tym, co sami zapisaliśmy). Przykład jego działania przedstawia fotografia 5.

Fotografia 5
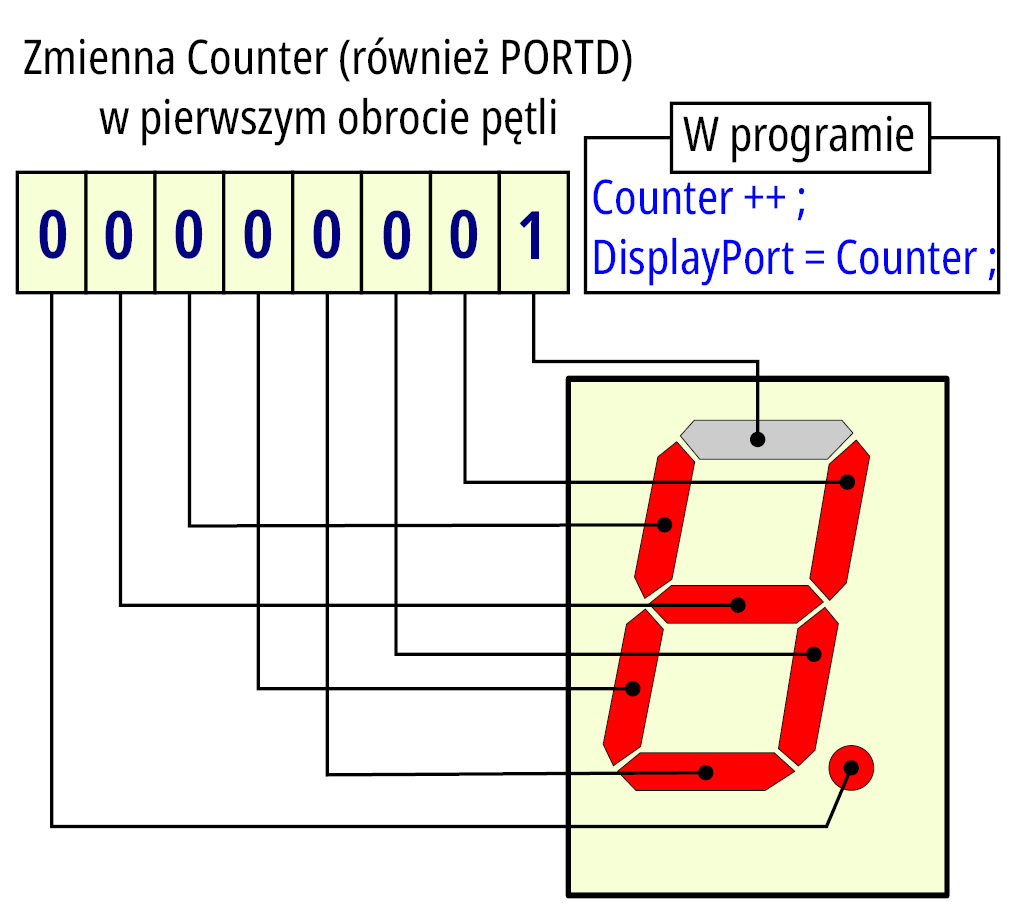
Zauważmy, że stan ośmiobitowej zmiennej jest bezpośrednio przesłany do ośmiobitowego portu. Wystąpienie na odpowiednim bicie zera oznacza, że skojarzony z bitem segment wyświetlacza będzie świecić. Po wyzerowaniu zmiennej (w funkcji Setup), w pierwszym obrocie pętli zostanie „wyświetlona” binarnie liczba jeden (jak widać na rysunku 6).
Rysunek 6
Nie należy traktować tego programu jako „porażki”, gdyż najbardziej wartościowa wiedza wynika z analizy i naprawy własnych błędów. Można tu też dostrzec ciekawe zjawisko. Z pozoru bezładne włączanie segmentów ma swoją logikę. Wyobraźmy sobie „rozwinięcie” segmentów w jednej linii, w kolejności od segmentu górnego zgodnie z ruchem wskazówek zegara kończąc na segmencie środkowym i segmencie kropki. Traktując segmenty świecące jako zera utworzą nam się kolejne liczby binarne (powstanie taki licznik binarny). Pokazana na fotografii 5 wartość odpowiadałaby liczbie 11001100 bin=CC hex=204 dec.
Z tego programu płynie jeszcze jeden istotny wniosek: świat mikrokontrolerów jest trochę inny niż świat ludzi. Nasze symbole (a znaki cyfr są takimi) są odmienne od mikroprocesorowych. Aby zaistniała „nić porozumienia” program należy rozbudować żeby rezultat jego działania był dla nas czytelny. Przed wyświetleniem liczby musimy dokonać konwersji z postaci mikroprocesorowej na taką postać, by wysterowanie poszczególnymi segmentami złożyło się na rozpoznawalną cyfrę. Chwilowo generuje to pewne ograniczenia, gdyż dysponując jednocyfrowym wyświetlaczem można jedynie pokazać liczby z przedziału od 0 do 9 (to ograniczenie zniknie przy obsłudze wyświetlaczy kilkucyfrowych, które będą omówione w następnych częściach).
Konwersja liczb
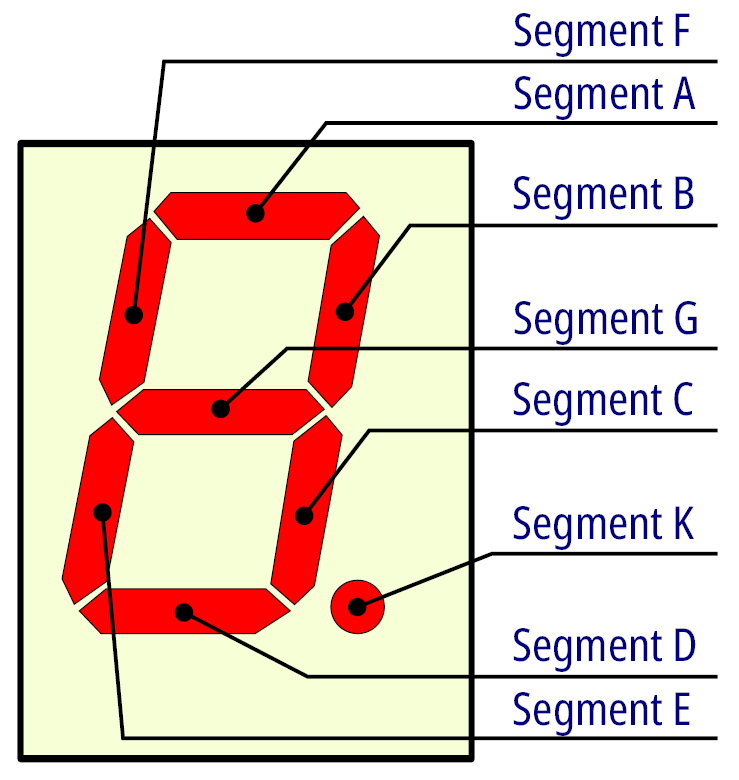
Przed wyświetleniem liczby należy dokonać konwersji z postaci binarnej cyfry na taką postać, by wyświetlacz pokazał dobrze znane nam symbole. Program musi „wiedzieć” jak reprezentowane są na wyświetlaczu cyfry dziesiętne oraz jakie piny portu są odpowiedzialne za sterowanie poszczególnymi segmentami wyświetlacza. Określenie segmentów w wyświetlaczu pokazuje rysunek 7.
Rysunek 7
Dobrym rozwiązaniem jest parametryzacja podłączenia wyświetlacza. Rozpatrzmy fragment programu widoczny na listingu 3:
#define SegmentAPin PD0 #define SegmentBPin PD1 #define SegmentCPin PD2 #define SegmentDPin PD3 #define SegmentEPin PD4 #define SegmentFPin PD5 #define SegmentGPin PD6 #define SegmentKPin PD7 #define SegmentA ( 1 << SegmentAPin ) #define SegmentB ( 1 << SegmentBPin ) #define SegmentC ( 1 << SegmentCPin ) #define SegmentD ( 1 << SegmentDPin ) #define SegmentE ( 1 << SegmentEPin ) #define SegmentF ( 1 << SegmentFPin ) #define SegmentG ( 1 << SegmentGPin ) #define SegmentK ( 1 << SegmentKPin )
Mamy tu poprzez #define SegmentAPin PD0 do #define SegmentKPin PD7 określony sposób przyłączenia poszczególnych segmentów do portu mikrokontrolera. W zapisach występują elementy PD0 do PD7. W rzeczywistości są to liczby od 0 do 7, które są zdefiniowane (przez #define) w pliku określającym indywidualne cechy mikrokontrolera (znane kompilatorowi w wyniku dołączenia do programu odpowiedniego pliku #include <avr/io.h>). Równie dobrze można zamiast PD0 napisać 0 (i podobnie w kolejnych). W następnych wierszach #define SegmentA (1<<SegmentAPin) do #define SegmentK (1<<SegmentKPin) są „wypracowane” kombinacje bitowe do wysterowania poszczególnych segmentów. Podobny „chwyt” był już stosowany w poprzednim artykule i powstaje zbiór wartości sterujących segmentami wyświetlacza – tę ideę przedstawia rysunek 8.

Rysunek 8
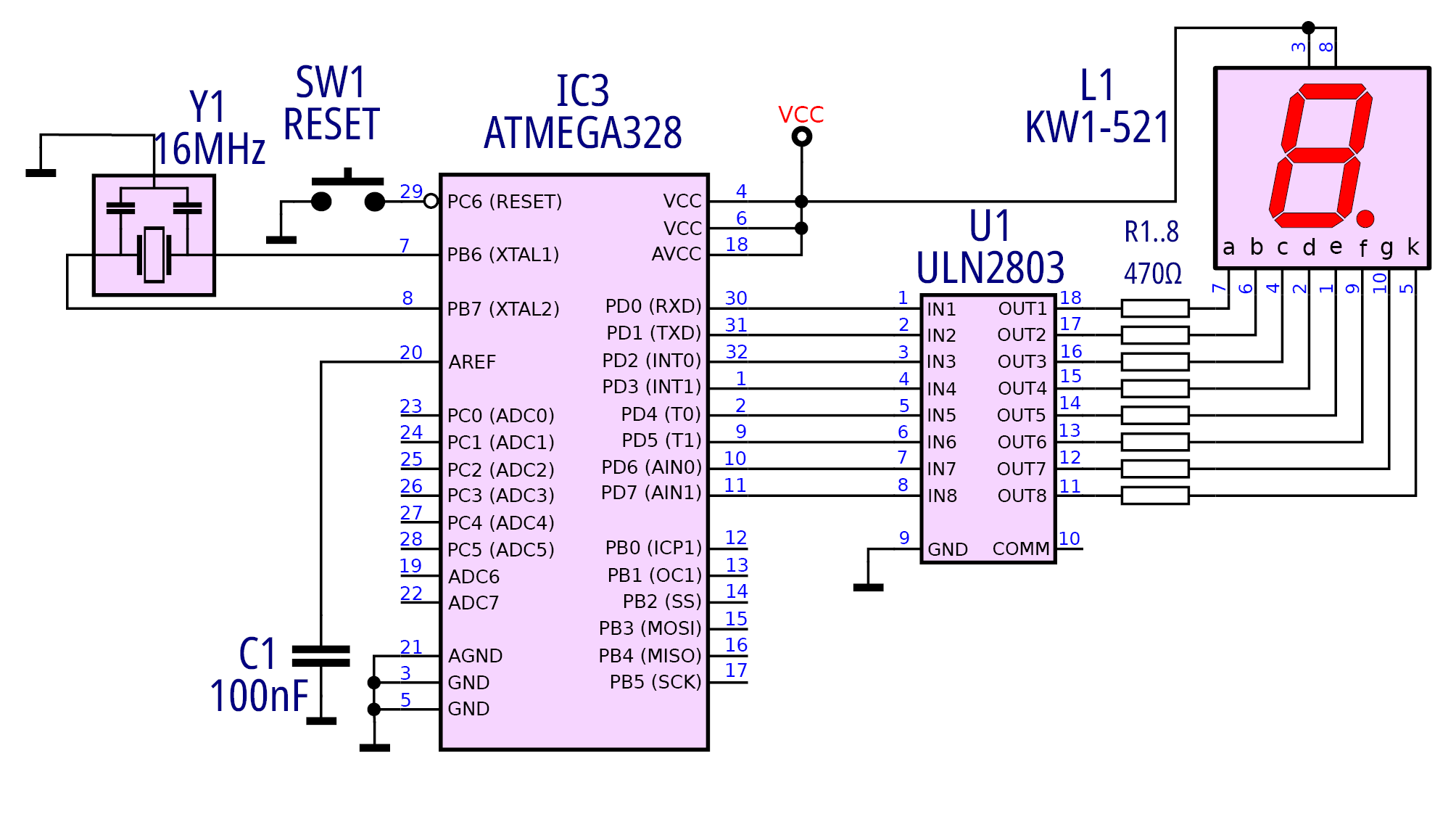
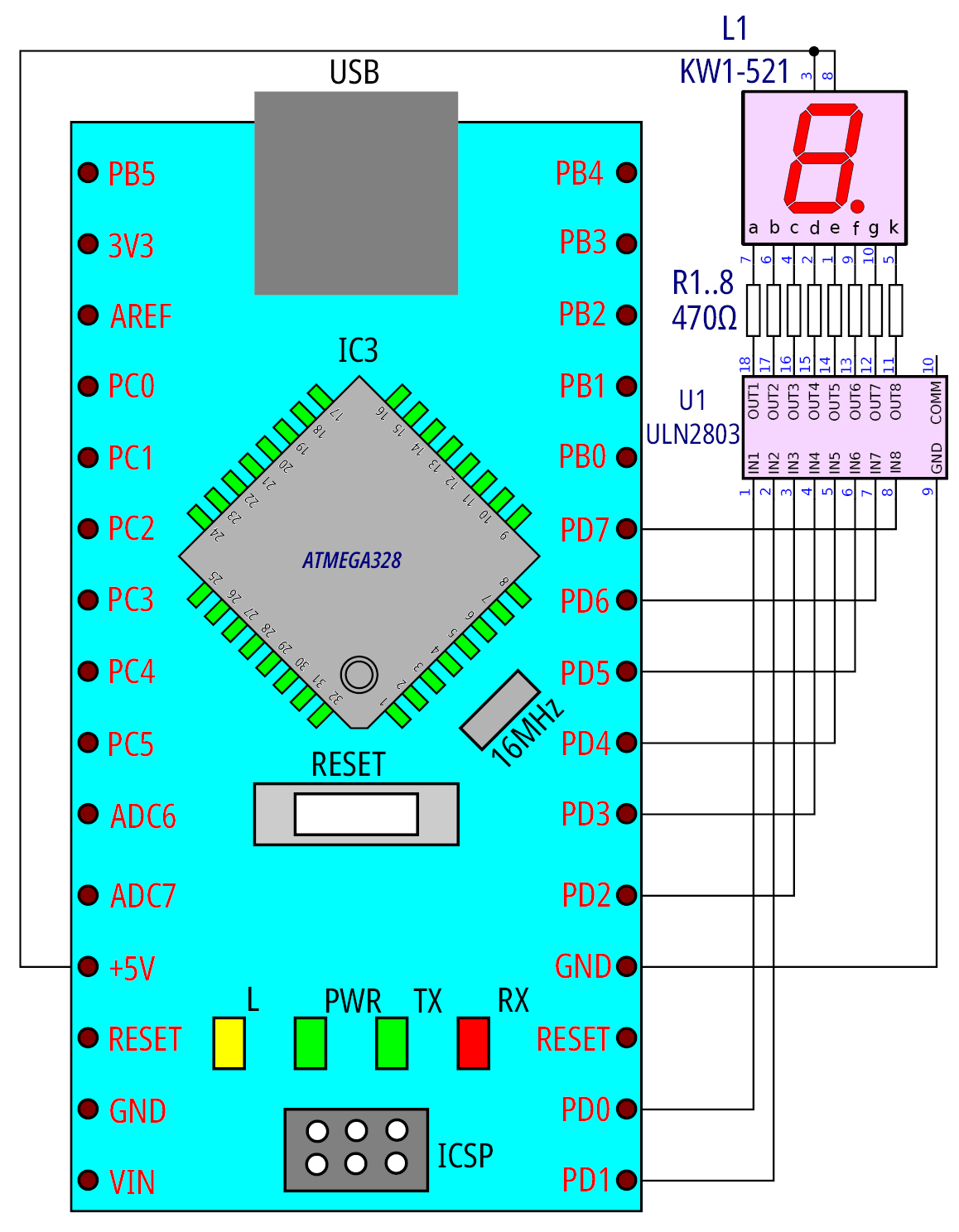
Uważny Czytelnik zapewne zauważył, że tak utworzone stałe nie zadziałają, gdyż 0 – włącza segment, 1 – wyłącza segment (stałe są jakby zanegowane). Wyjaśnienie jest dosyć proste, gdyż uzyskane stałe są jedynie „półproduktem”. Możliwy jest inny sposób przyłączenia wyświetlacza na przykład z wykorzystaniem popularnego układu ULN2803, jak pokazuje rysunek 9 i 10. Takie rozwiązanie jest nawet zalecane, gdyż zmniejsza obciążenie prądowe portów mikrokontrolera, jednak jego cechą charakterystyczną jest negacja sygnału (by dany segment świecił, na wyjściu portu musi wystąpić jedynka logiczna).
Rysunek 9
Rysunek 10
Spróbujemy „połączyć” w jedno te dwa sprzeczne wymagania, gdyż w jednym przypadku do portu należy wysłać dane składające się z wypracowanych kombinacji sterujących poszczególnymi segmentami lub w drugim wysłać je w postaci zanegowanej logicznie.
Do obsługi wyświetlacza zostaje utworzona specjalna funkcja (o nazwie Display) z jednym parametrem jak pokazuje we fragmencie listing 4 (pełne postacie zaprezentowanych programów są dostępne jako materiały dodatkowe do artykułu):
void Display ( uint8_t Ch )
{
uint8_t PortData ;
/*------------------------*/
switch ( Ch )
{
case 0 :
PortData = NegOperator ( SegmentA | SegmentB | SegmentC |
SegmentD | SegmentE | SegmentF ) ;
break ;
case 1 :
PortData = NegOperator ( SegmentB | SegmentC ) ;
break ;
case 2 :
PortData = NegOperator ( SegmentA | SegmentB | SegmentD |
SegmentE | SegmentG ) ;
break ;
case 3 :
PortData = NegOperator ( SegmentA | SegmentB | SegmentC |
SegmentD | SegmentG ) ;
break ;
( . . . )
default :
PortData = NegOperator ( SegmentG ) ;
} ;
DisplayPort = PortData ;
}
Tym parametrem jest informacja typu uint8_t (liczba 8-bitowa bez znaku) identyfikowana nazwą Ch. Można ją traktować jako zmienną obowiązującą jedynie w obrębie funkcji, której wartość została nadana w chwili jej wywołania. Ideę ilustruje rysunek 11.
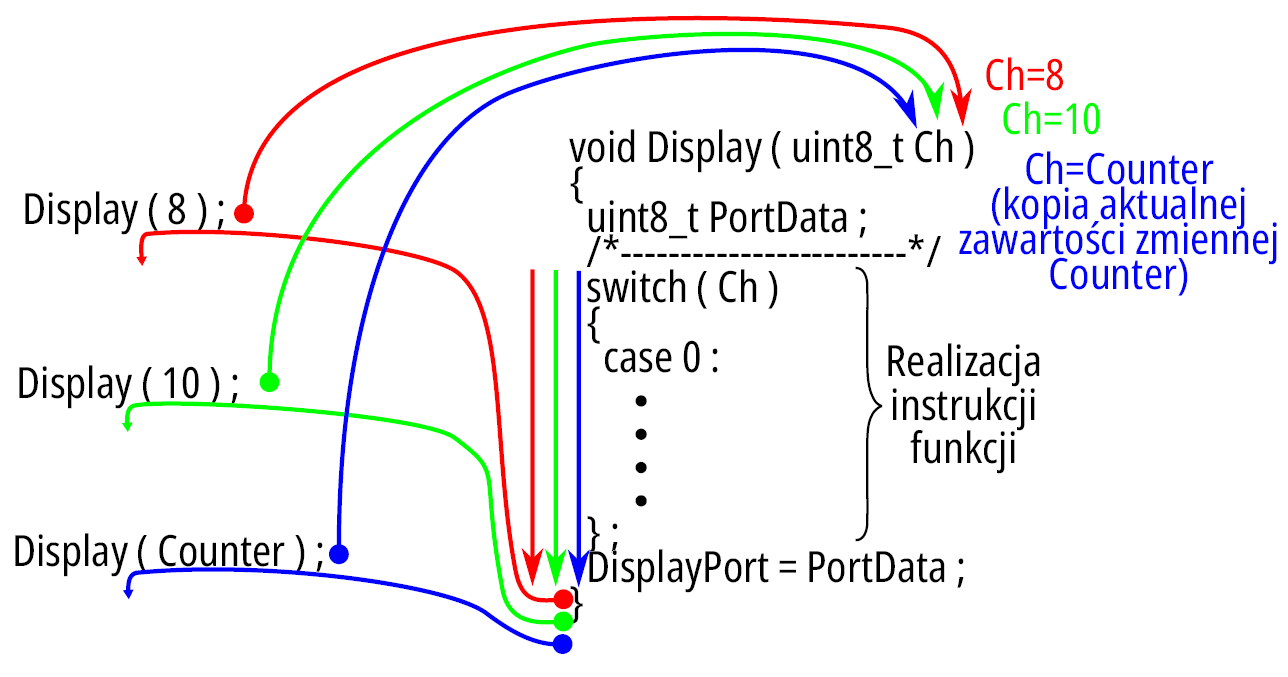
Rysunek 11
W programie w kilku miejscach wywoływana jest funkcja Display, raz z parametrem o wartości 8 (aby zostały włączone wszystkie segmenty wyświetlacza, co pozwoli stwierdzić, że nic się nie rozłączyło, nie uszkodziło), z parametrem o wartości 10 (co stanowi już wartość niedopuszczalną, gdyż nie ma wśród cyfr arabskich znaku odpowiadającego tej wartości, co przy okazji pozwala poznać wariant default w instrukcji switch, o czym za chwilę), oraz z parametrem będącym kopią zmiennej Counter.
Zadaniem funkcji Display jest bazując na wartości parametru Ch wniesionego do funkcji, wypracować takie kombinacje sterujące wyświetlaczem, by została tam zobrazowana odpowiednia cyfra dziesiętna. Do tego celu można wykorzystać instrukcję switch. To dosyć złożona instrukcja (w sensie zapisu), jej postać pokazuje listing 5 (słowa występujące w tej instrukcji: switch, case, default, break są słowami kluczowymi – mają swoje ustalone znaczenia i nie mogą być użyte w innych celach):
switch ( <wyrażenie> )
{
case <wariant 1> :
<instrukcje wariantu 1> ;
case <wariant 2> :
<instrukcje wariantu 2> ;
( . . . )
case <wariant n> :
<instrukcje wariantu n> ;
default :
<instrukcje wariantu : każdy inny> ;
}
Występujący tu element <wyrażenie> może być dowolnym wyrażeniem (jak w każdej instrukcji podstawienia) w szczególności zredukowanym do jednej zmiennej, <wariant 1>, <wariant 2>, … <wariant n> są stałymi, jakie może przyjmować wartość wyrażenia (ujętego w nawiasach za słowem kluczowym switch). Oczywiste jest, że warianty nie mogą się powtarzać. Również w kategorii wariantu występuje słowo default, oznaczające wariant każdy inny niż wymienione. Działanie tej instrukcji sprowadza się do obliczenia (w ogólnym przypadku) wartości <wyrażenie> i w przypadku, gdy ta wartość jest równa stałej <wariant 1> przejść do wykonywania instrukcji zapisanych po case <wariant 1>. W przypadku, gdy wartość obliczonego wyrażenia jest równa stałej <wariant 2>, to tym razem następuje przejście do instrukcji zapisanych po case <wariant 2>, i tak dalej. Nie ma obowiązku wypisania wszystkich możliwych wariantów, jakie przyjmie wartość <wyrażenie>. Jeżeli zaistnieje taki przypadek, że nie wystąpi odpowiedni wariant, to switch nie wybierze żadnego, chyba że w zapisie został zastosowany wariant o znaczeniu każdy inny, który jest identyfikowany słowem kluczowym default. Specyfiką instrukcji switch jest to, że wykonanie programu przenosi się do miejsca oznaczonego przez case <stała> (lub default) i instrukcje są wykonywane od tego miejsca do końca instrukcji switch (do nawiasu zamykającego „}”) lub do napotkania instrukcji break, która nakazuje „wyjście” z instrukcji switch, skok poza nawias zamykający. Takie rozwiązanie pozwala na łączenie wariantów. Ideę działania instrukcji switch prezentuje rysunek 12.
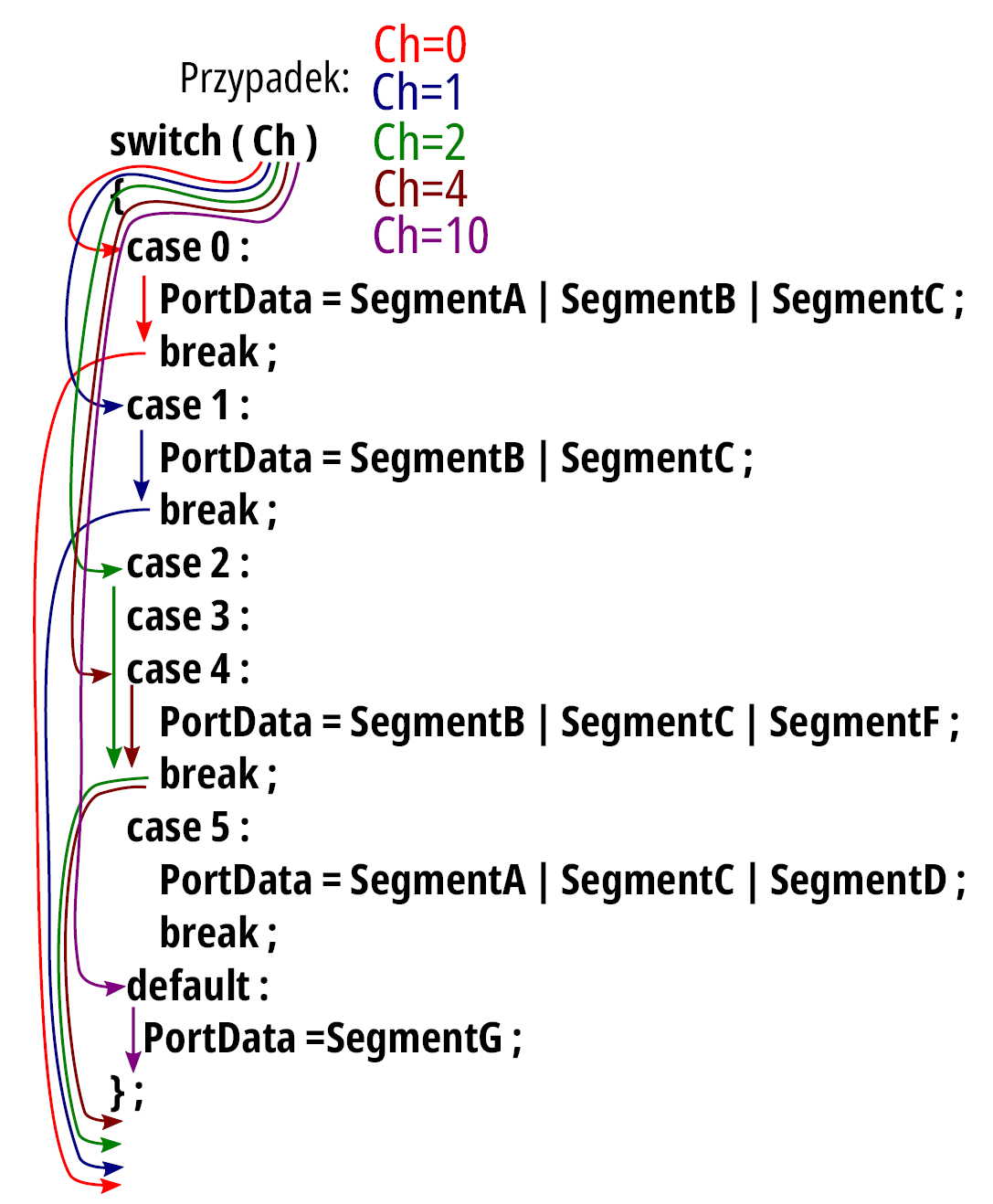
Rysunek 12
Po zrozumieniu znaczenia zastosowanych instrukcji, pora na wyjaśnienie działania samej funkcji Display (listing 4). Występuje tam element o nazwie NegOperator, który jest zdefiniowany wcześniej jako #define NegOperator ~ lub jako zakomentowany wariant //#define NegOperator (jeden z nich musi być aktywny, drugi zakomentowany). Kompilator, analizując instrukcje funkcji Display zamieni wyraz NegOperator na znak „~” lub na puste. W pierwszym przypadku (ze znakiem „~”) złożone sterowanie segmentami zostanie zanegowane i zapisane do lokalnej zmiennej (obowiązuje ona jedynie w obrębie funkcji Display) i już poza instrukcją switch stan zmiennej jest wpisany do portu sterującego wyświetlaczem. W drugim przypadku nie nastąpi negowanie bitów. Działanie ilustruje rysunek 13.
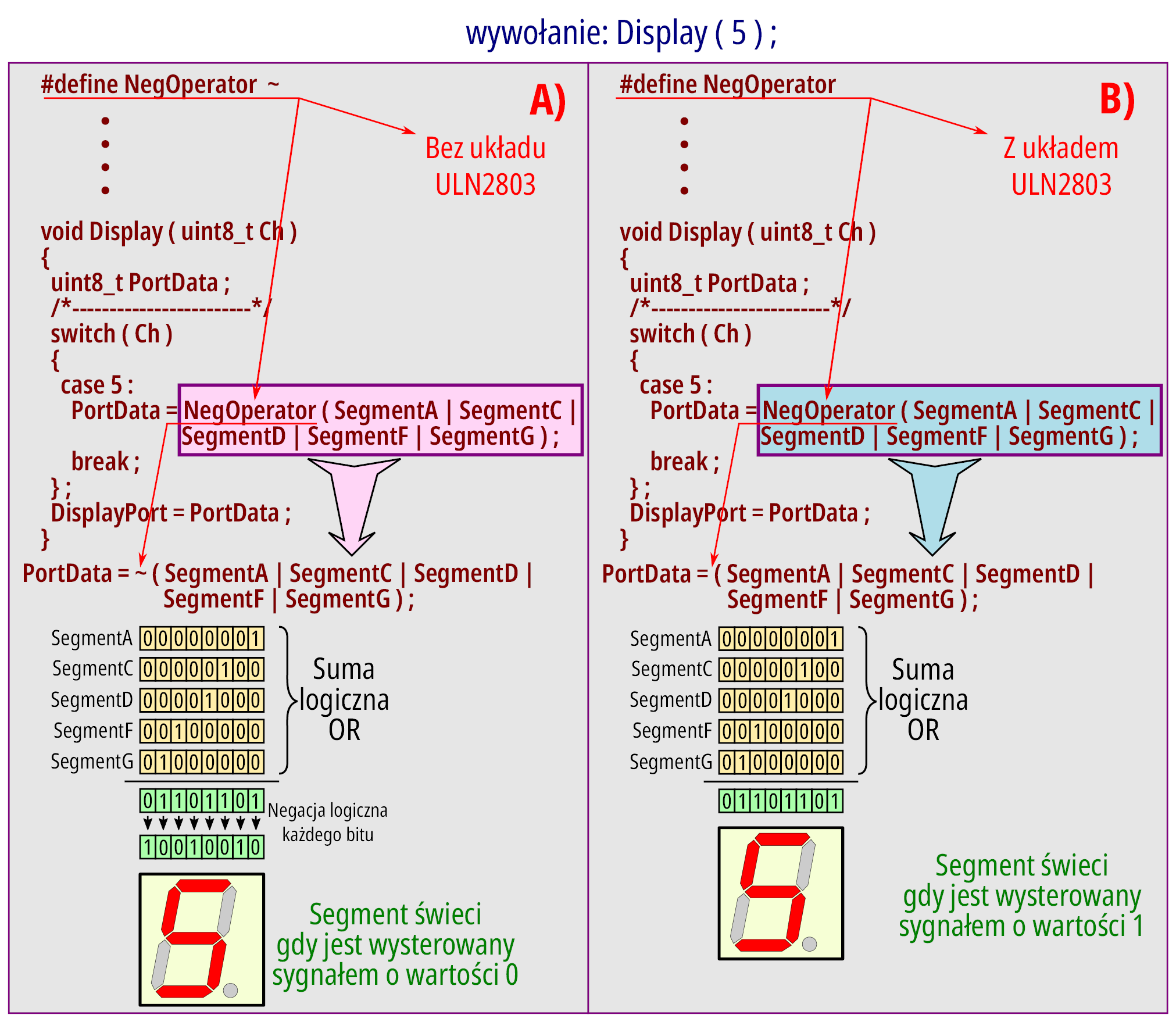
Rysunek 13
Tu warto zwrócić uwagę na istotny szczegół, całe wyrażenie zawarte po symbolu NegOperator musi być ujęte w nawiasy, gdyż operator ~ „obejmuje swym zasięgiem” jedynie jeden element (lub całe wyrażenie ujęte w nawiasach). W przypadku, gdy NegOperator jest pusty, nadmiar nawiasów nie ma znaczenia.
Działanie programu
Po wstępnych działaniach inicjujących pracę programu, jego normalna praca zawarta jest w funkcji Loop, jak pokazuje to listing 6:
void Loop ( void )
{
Counter ++ ;
if ( Counter >= 10 )
Counter = 0 ;
Display ( Counter ) ;
_delay_ms ( 1000 ) ;
}
Tu pojawiła się kolejna nowa instrukcja if. Jest to instrukcja warunkowa. Za słowem kluczowym if w nawiasach podany jest warunek i w zależności od tego, czy warunek jest spełniony, wykonana jest instrukcja kolejna (jedna instrukcja, jeżeli potrzebujemy kilku, należy je ująć w nawiasy { } tworząc w ten sposób jedną instrukcję złożoną). W przypadku, gdy warunek nie jest spełniony, kolejna instrukcja jest pominięta (lub cały ciąg instrukcji ujętych w { }). Wyrażenie określające warunek to wyrażenie logiczne, takie, dla którego można przypisać wartość Tak (true) lub Nie (false). W zastosowanej instrukcji (listing 6) zawartość zmiennej porównywana jest ze stałą liczbową. Między tymi elementami występuje operator relacji. W ogólnym przypadku po obu stronach operatora relacji mogą wystąpić całe wyrażenia, których wartość jest porównywana ze sobą (to oczywiście wymaga, aby typy obu wyrażeń były zgodne). Możliwe operatory relacji to:
- operator większe „>”, warunek jest prawdziwy, jeżeli wartość wyrażenia po lewej stronie operatora jest większa od wartości wyrażenia po prawej stronie,
- operator większe lub równe „>=”, warunek jest prawdziwy, jeżeli wartość wyrażenia po lewej stronie operatora jest większa lub równa z wartością wyrażenia po prawej stronie,
- operator mniejsze „<”, warunek jest prawdziwy, jeżeli wartość wyrażenia po lewej stronie operatora jest mniejsza od wartości wyrażenia po prawej stronie,
- operator mniejsze lub równe „<=”, warunek jest prawdziwy, jeżeli wartość wyrażenia po lewej stronie operatora jest mniejsza lub równa z wartością wyrażenia po prawej stronie,
- operator równe „==” (dwa znaki), warunek jest prawdziwy, jeżeli wartości obu wyrażeń są równe,
- operator nie równe „!=”,, warunek jest prawdziwy, jeżeli wartości obu wyrażeń są różne.
Tu należy zwrócić szczególną uwagę na operator równe („==”). Warunek w przykładowym zapisie if ( Counter == 10) jest prawdziwy, jeżeli zmienna Counter zawiera liczbę 10. Zapis if ( Counter = 10 ) jest również poprawny w sensie „gramatyki” języka C, jednak działanie jest znacząco inne. W tym przypadku nastąpi podstawienie (Counter = 10) i jeżeli wynik tego podstawienia jest różny od zera, to warunek jest spełniony (dokładnie, jest spełniony zawsze) więc instrukcja występująca po if ( warunek ) będzie wykonana (można powiedzieć, że bezwarunkowo). Ten wariant można zapisać następująco (jako dwie instrukcje): Counter = 10 ; if ( Counter != 0 ) i teraz wyraźnie widać, że warunek jest spełniony zawsze.
Działania realizowane w funkcji Loop dotyczą inkrementacji zmiennej (zwiększania o jeden) i sprawdzenia, czy po inkrementacji zmienna Counter przechowuje liczbę 10 lub większą. Jeżeli warunek jest spełniony, to następuje podstawienie Counter = 0, w przeciwnym wypadku ta instrukcja jest pominięta. Łatwo dostrzec, że w zmiennej Counter będą jedynie wartości od 0 do 9. Równie dobrze można zapisać if ( Counter == 10 ), gdyż realizując inkrementację jedyną możliwością „wyjścia” poza przedział 0…9 jest „przejście” przez 10. Ograniczenie zakresu do przedziału 0…9 wynika z tego, że dysponujemy pojedynczym wyświetlaczem i możliwe jest zobrazowanie liczb z tego przedziału. Po inkrementacji połączonej z ewentualnym „zawróceniem” na początek, aktualny stan zmiennej Counter jest pokazany na wyświetlaczu (w wyniku wykonanie instrukcji Display ( Counter ) ;). Aby wszystko toczyło się w sensownym tempie, działanie programu jest zatrzymane na jedną sekundę w wyniku wywołania znanej już funkcji _delay_ms.
Pozostało skompilować program oraz zaprogramować pamięć Flash mikrokontrolera uzyskanym kodem binarnym. Teraz można cieszyć się nową zabawką (fotografia 14).

Fotografia 14
Dodajemy przycisk
Bazując na uzyskanej obsłudze wyświetlacza, do układu zostanie dodany przycisk, którego naciśnięcie będzie oznaczało inkrementację zmiennej połączoną z jej wyświetleniem. Teraz to my decydujemy o działaniu układu zamiast narzuconej nam przez mikrokontroler koncepcji działania. Naciskamy przycisk —> program zwiększy wyświetlaną liczbę o jeden, nie naciskamy przycisku —> nic się nie dzieje.
Wymaga to rozbudowania środowiska o kolejny element, jakim jest przycisk wraz z „podciągającym” rezystorem (rysunek 15 i 16).
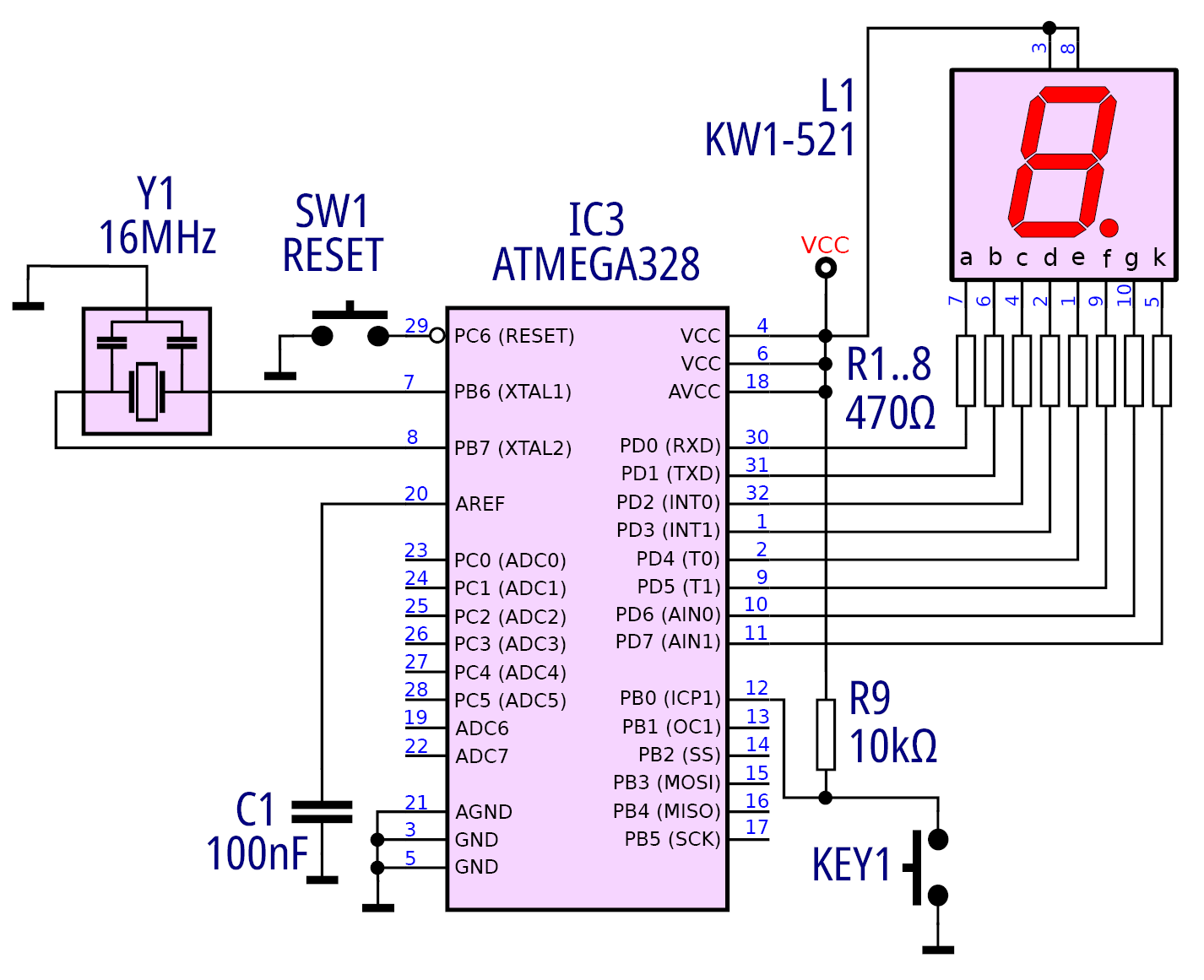
Rysunek 15
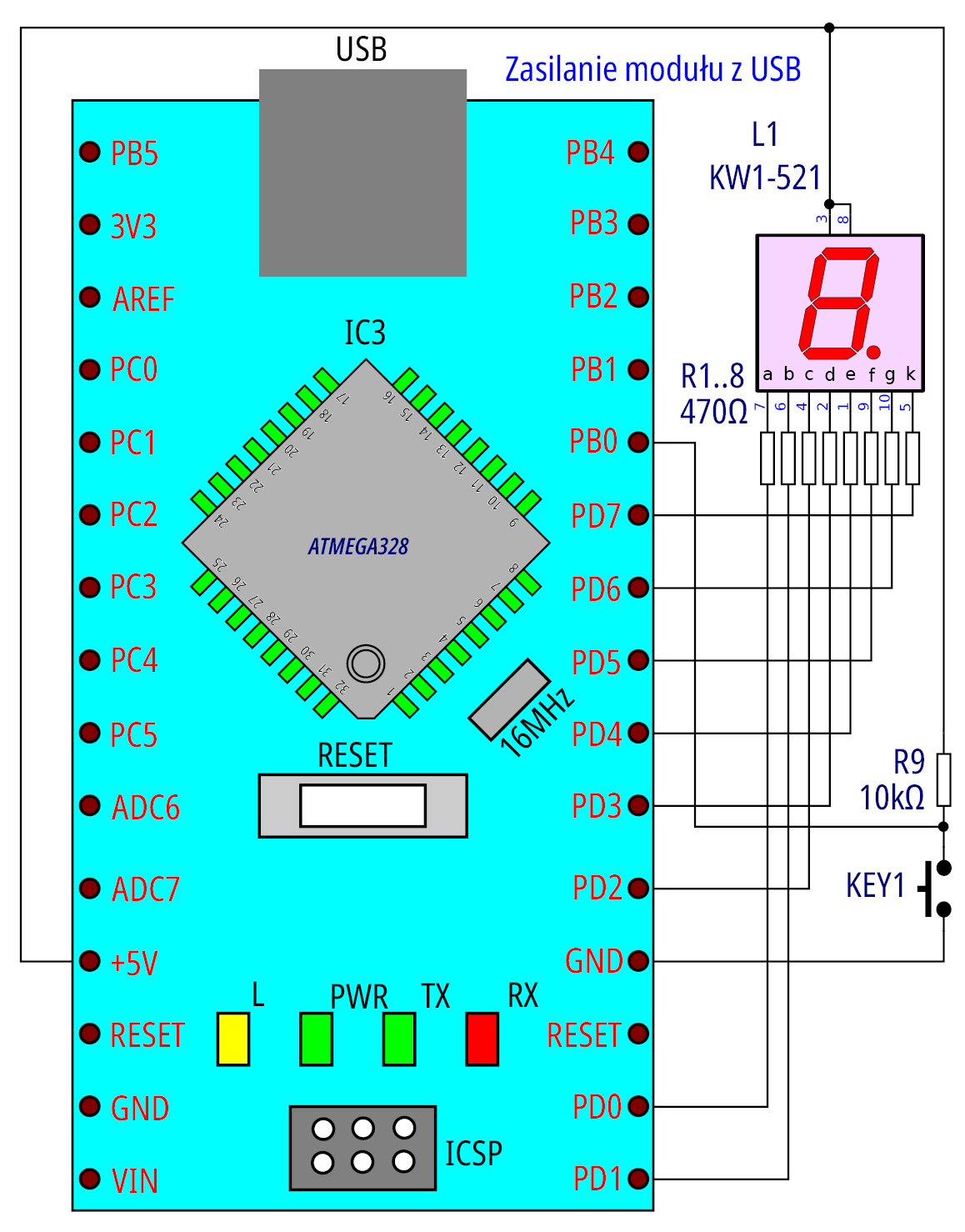
Rysunek 16
Dodane „zabawki” wymagają również odpowiedniej modyfikacji w programie. Należy określić, że wybrany pin przewidziany do obsługi przycisku jest wejściowy z wewnętrznym rezystorem wymuszającym stan jedynki na wejściu w sytuacji, gdy przycisk nie jest naciśnięty. Niezbędne elementy zawiera listing 7:
#define KeybPort PINB
#define KeyConfig1 DDRB
#define KeyConfig2 PORTB
#define KeyPin PB0
void Setup ( void )
{
( . . . )
KeyConfig1 &= ~ ( 1 << KeyPin ) ;
KeyConfig2 |= 1 << KeyPin ;
( . . . )
}
Rejestr konfiguracyjny KeyConfig1 (w rzeczywistości DDRB) ma wyzerowany jeden bit określony przez KeyPin (chociaż w wyniku zadziałania operacji reset mikrokontrolera, jego porty są ustawione jako wejściowe, dodanie tej instrukcji należy do dobrego obyczaju). Drugi rejestr KeyConfig2 już musi być zaprogramowany (ustawiony określony bit), bo tego nikt za nas nie zrobi. Operacje ustawiania oraz zerowania konkretnych bitów były szczegółowo wyjaśnione w artykule U069 („Mikroprocesorowa ośla łączka, część 4”).
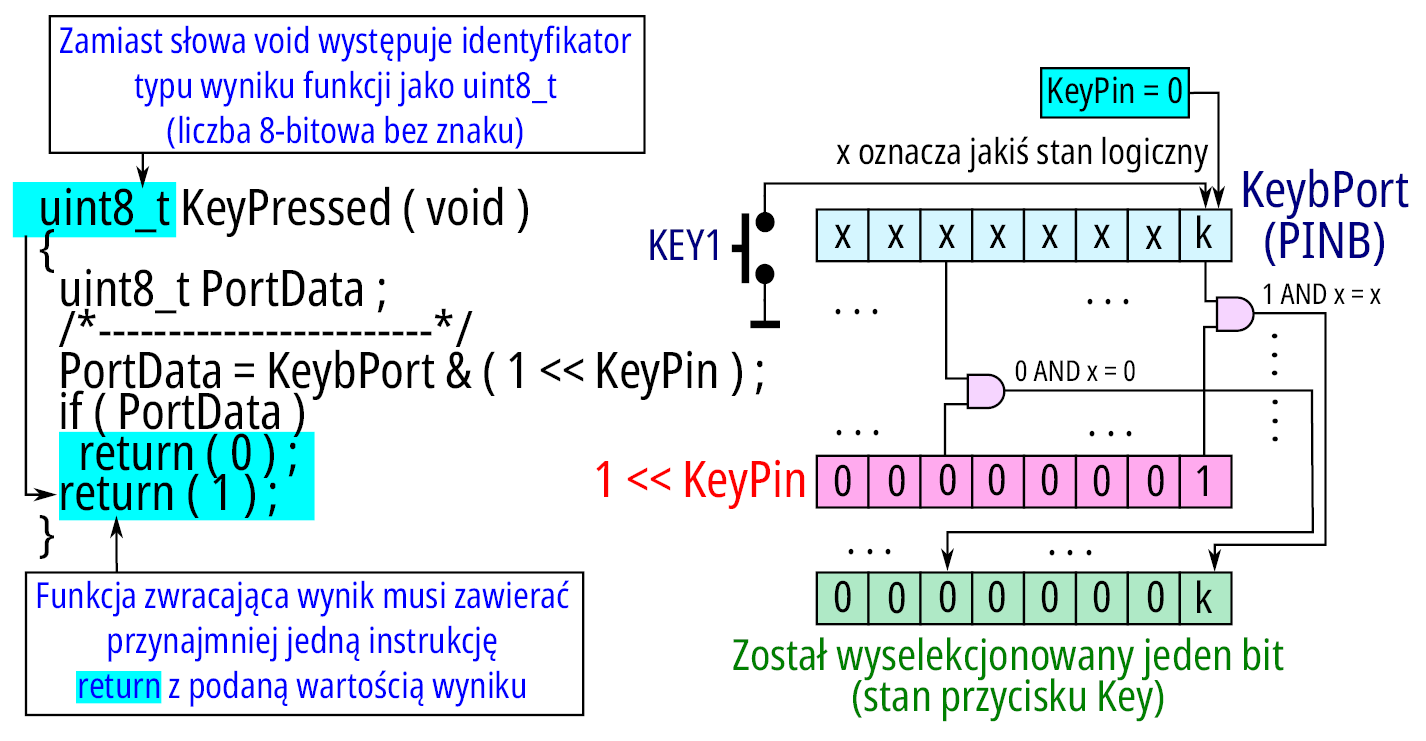
Dochodzi dodatkowa funkcja zwracająca jakiś wynik do obsługi przycisku (o nazwie KeyPressed), której zadaniem jest podać informację typu tak/nie (wynik funkcji jest 1/0) oznaczającą przyciśnięcie przycisku, pokazuje ją listing 8:
uint8_t KeyPressed ( void )
{
uint8_t PortData ;
/*------------------------*/
PortData = KeybPort & ( 1 << KeyPin ) ;
if ( PortData )
return ( 0 ) ;
return ( 1 ) ;
}
Jej działanie ilustruje rysunek 17.
Rysunek 17
Wczytanie stanu portu (KeyPort jako PINB) to rzeczywisty stan na wejściu portu (jako osiem bitów) w iloczynie logicznym z wyrażeniem 1 << KeyPin wyselekcjonuje jednobitowo stan przycisku (wszędzie na bitach będą zera, a na jednym bicie będzie stan generowany przez przycisk) i wynik zostaje zapamiętany w zmiennej lokalnej PortData. Łącznie będzie to liczba o wartości zero lub nie zero (dla KeyPin=0 będzie to 1, dla KeyPin=1 będzie to 2 itd. i w sumie nie ma to znaczenia ile). Stan naciśniętego przycisku da wynik 0, w przeciwnym wypadku będzie to wartość różna od zera. Jeżeli ta wartość jest różna od zera (warunek w instrukcji if (PortData) jest spełniony), oznacza to, że przycisk nie jest wciśnięty, wyniesiony wynik funkcji jest return ( 0 ). Jest to kolejne słowo kluczowe (return) określające instrukcję zwracającą wynik działania funkcji do miejsca jej wywołania. Ta instrukcja jednocześnie oznacza operację wyjścia z funkcji (nie będą wykonane żadne instrukcje zapisane dalej). Taki przypadek występuje w funkcji KeyPressed, gdzie jeżeli jest spełniony warunek w instrukcji if, następuje zakończenie jej działania z wynikiem 0. W przeciwnym wypadku instrukcja nie jest wykonana. Pominięcie jej (return ( 0 ) ; jako instrukcji wykonywanej warunkowo oznacza, że przycisk jest naciśnięty i następuje zakończenie pracy funkcji z innym wynikiem: return ( 1 ) ;.
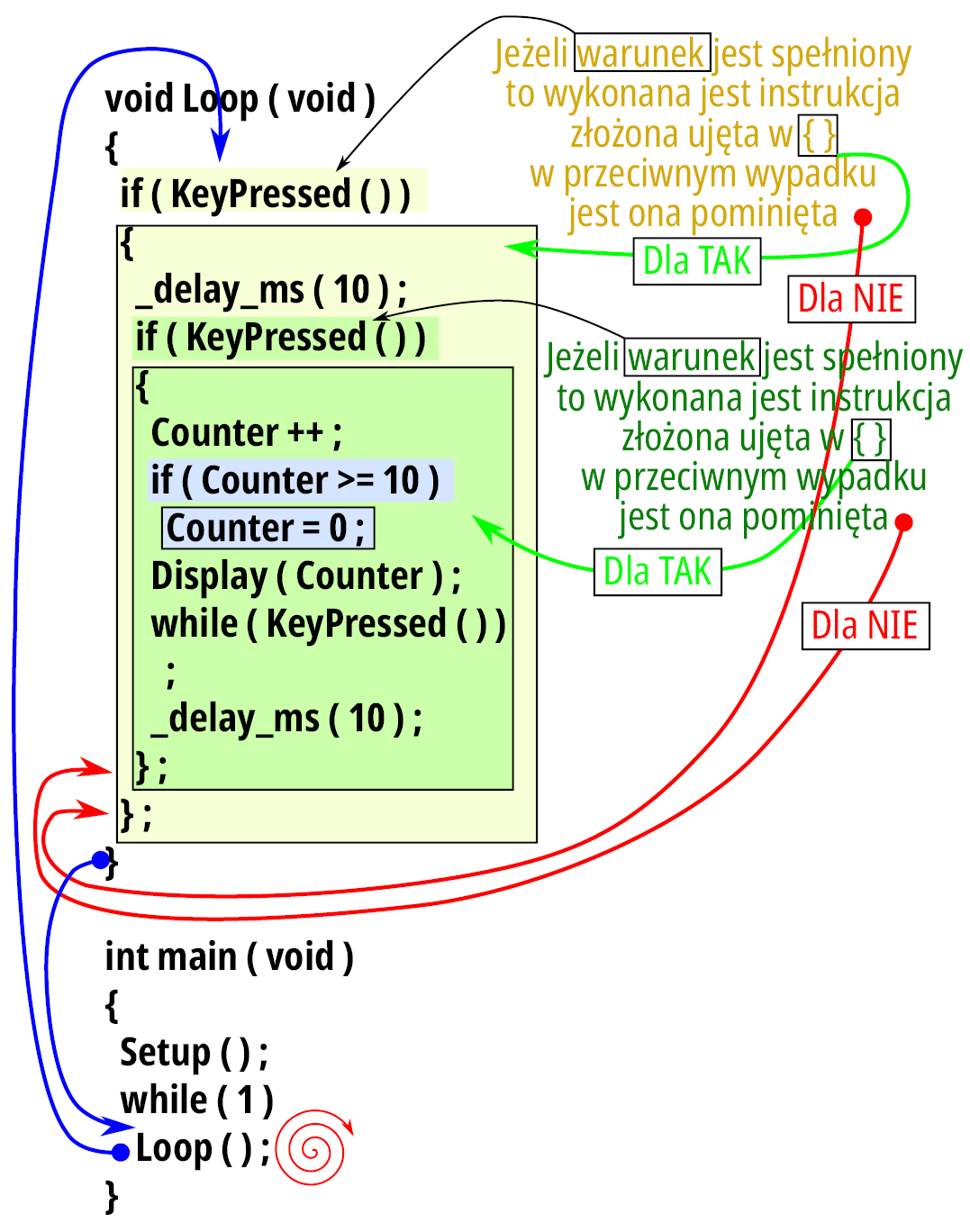
Nowe koncepcje działania mają również swoje odbicie w treści funkcji Loop, której postać prezentuje listing 9:
void Loop ( void )
{
if ( KeyPressed ( ) )
{
_delay_ms ( 10 ) ;
if ( KeyPressed ( ) )
{
Counter ++ ;
if ( Counter >= 10 )
Counter = 0 ;
Display ( Counter ) ;
while ( KeyPressed ( ) )
;
_delay_ms ( 10 ) ;
} ;
} ;
}
Pamiętamy, że ta funkcja jest wywoływana z funkcji main tak często, jak jest to możliwe, gdzie w każdym wywołaniu badane jest, czy został naciśnięty przycisk. W sytuacji, gdy ten fakt jest stwierdzony, program odczekuje niewielki interwał czasu, aby pominąć dzwonienie styków przycisku. Jeżeli po jego upłynięciu przycisk nadal jest naciśnięty, to należy uznać, że jest to stan stabilny. W kolejnym kroku program inkrementuje zawartość zmiennej z ewentualnym wyzerowaniem jej, jeżeli został przekroczony dopuszczalny zakres (identycznie jak w poprzednim wariancie). Po wyświetleniu nowej liczby na wyświetlaczu, program w pętli while odczekuje na zwolnienie przycisku. W instrukcji while sprawdzane jest naciśnięcie przycisku, co należy interpretować jako: dopóki przycisk jest naciśnięty wykonaj instrukcję pustą (nic nie rób). Wyjście z pętli nastąpi w chwili pierwszego „drgnięcia” styków wynikającego ze zwolnienia przycisku. Dla pewności zostaje odczekany dodatkowy czas aby dzwonienie styków nie wniosło „zaburzeń” w działaniu programu. Wykonane czynności ilustruje rysunek 18.
Rysunek 18
Po zaprogramowaniu mikrokontroler realizuje swoje czynności zgodnie z planem (fotografia 19).

Fotografia 19
Proponowane ćwiczenia
Schemat układu pokazany na rysunkach 15 i 16 zawierał rezystor (R9) „podciągający” wejście mikrokontrolera do obsługi przycisku. Możliwe jest usunięcie tego rezystora. Proponuję samodzielnie sprawdzić działanie układu w kombinacjach: zapisu/braku zapisu do rejestru KeyConfig2 (wystarczy jedyny wiersz z KeyConfig2 w funkcji Setup zakomentować) oraz jest rezystor R9/nie ma rezystora R9 (tu należy go fizycznie odłączyć).
Zaprezentowane programy jako kompletne projekty w Atmel Studio są dostępne tutaj.
Andrzej Pawluczuk
apawluczuk@vp.pl



